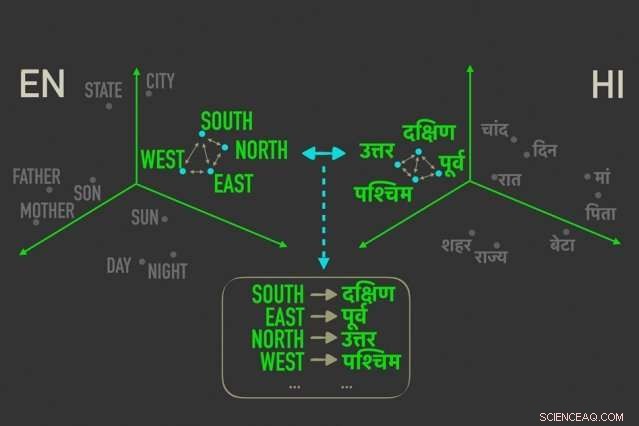
Den nya modellen mäter avstånd mellan ord med liknande betydelser i "ordinbäddningar, ” och justerar sedan orden i båda inbäddningarna som är närmast korrelerade med relativa avstånd, vilket innebär att de med största sannolikhet är direkta översättningar av varandra. Kredit:Massachusetts Institute of Technology
MIT-forskare har utvecklat en ny "oövervakad" språköversättningsmodell – vilket innebär att den körs utan behov av mänskliga kommentarer och vägledning – som kan leda till snabbare, effektivare datorbaserade översättningar av mycket fler språk.
Översättningssystem från Google, Facebook, och Amazon kräver utbildningsmodeller för att leta efter mönster i miljontals dokument – som juridiska och politiska dokument, eller nyhetsartiklar – som har översatts till olika språk av människor. Med tanke på nya ord på ett språk, de kan sedan hitta de matchande orden och fraserna på det andra språket.
Men dessa översättningsdata är tidskrävande och svåra att samla in, och kanske helt enkelt inte existerar för många av de 7, 000 språk som talas över hela världen. Nyligen, forskare har utvecklat "enspråkiga" modeller som gör översättningar mellan texter på två språk, men utan direkt översättningsinformation mellan de två.
I ett dokument som presenteras denna vecka vid konferensen om empiriska metoder i naturlig språkbehandling, forskare från MIT:s Computer Science and Artificial Intelligence Laboratory (CSAIL) beskriver en modell som går snabbare och mer effektivt än dessa enspråkiga modeller.
Modellen utnyttjar ett mått i statistik, kallas avstånd Gromov-Wasserstein, som i huvudsak mäter avstånd mellan punkter i ett beräkningsutrymme och matchar dem med punkter på liknande avstånd i ett annat utrymme. De tillämpar den tekniken på "ordinbäddningar" av två språk, som är ord representerade som vektorer – i grunden, uppsättningar av siffror – med ord med liknande betydelser samlade närmare varandra. Genom att göra så, modellen anpassar snabbt orden, eller vektorer, i båda inbäddningar som är närmast korrelerade med relativa avstånd, vilket innebär att de sannolikt är direkta översättningar.
I experiment, forskarnas modell presterade lika exakt som de senaste enspråkiga modellerna – och ibland mer exakt – men mycket snabbare och använde bara en bråkdel av beräkningskraften.
"Modellen ser orden på de två språken som uppsättningar av vektorer, och mappar [dessa vektorer] från en uppsättning till den andra genom att i huvudsak bevara relationer, " säger tidningens medförfattare Tommi Jaakkola, en CSAIL-forskare och Thomas Siebel-professorn vid institutionen för elektroteknik och datavetenskap och Institutet för data, System, och samhället. "Tillvägagångssättet kan hjälpa till att översätta resurssnåla språk eller dialekter, så länge de kommer med tillräckligt enspråkigt innehåll."
Modellen representerar ett steg mot ett av huvudmålen med maskinöversättning, som är helt oövervakad ordjustering, säger första författaren David Alvarez-Melis, en CSAIL Ph.D. student:"Om du inte har några data som matchar två språk ... kan du kartlägga två språk och, med hjälp av dessa avståndsmått, anpassa dem."
Relationer betyder mest
Att anpassa ordinbäddningar för oövervakad maskinöversättning är inte ett nytt koncept. Nyligen arbete tränar neurala nätverk för att matcha vektorer direkt i ordinbäddningar, eller matriser, från två språk tillsammans. Men dessa metoder kräver en hel del justeringar under träningen för att få anpassningarna exakt rätt, vilket är ineffektivt och tidskrävande.
Mätning och matchning av vektorer baserat på relationella avstånd, å andra sidan, är en mycket effektivare metod som inte kräver mycket finjustering. Oavsett var ordvektorer hamnar i en given matris, förhållandet mellan orden, menar deras avstånd, kommer att förbli densamma. Till exempel, vektorn för "far" kan falla i helt olika områden i två matriser. Men vektorer för "far" och "mamma" kommer med största sannolikhet alltid att ligga nära varandra.
"Dessa avstånd är oföränderliga, " Alvarez-Melis säger. "Genom att titta på avstånd, och inte vektorernas absoluta positioner, sedan kan du hoppa över justeringen och gå direkt till att matcha överensstämmelserna mellan vektorer."
Det är där Gromov-Wasserstein kommer väl till pass. Tekniken har använts inom datavetenskap för, säga, hjälpa till att justera bildpixlar i grafisk design. Men måtten verkade "skräddarsydd" för ordanpassning, Alvarez-Melis säger:"Om det finns poäng, eller ord, som är nära varandra i ett utrymme, Gromov-Wasserstein kommer automatiskt att försöka hitta motsvarande kluster av punkter i det andra utrymmet."
För träning och testning, forskarna använde en datauppsättning av allmänt tillgängliga ordinbäddningar, kallas FASTTEXT, med 110 språkpar. I dessa inbäddningar, och andra, ord som förekommer allt oftare i liknande sammanhang har nära matchande vektorer. "Mamma" och "pappa" kommer vanligtvis att vara nära varandra men båda längre bort från, säga, "hus."
Tillhandahålla en "mjuk översättning"
Modellen noterar vektorer som är nära besläktade men ändå olika från de andra, och tilldelar en sannolikhet att vektorer med liknande avstånd i den andra inbäddningen kommer att överensstämma. Det är ungefär som en "mjuk översättning, " Alvarez-Melis säger, "för istället för att bara returnera en översättning av ett enda ord, det säger dig 'denna vektor, eller ord, har en stark överensstämmelse med detta ord, eller ord, på det andra språket."
Ett exempel skulle vara under årets månader, som förekommer nära varandra på många språk. Modellen kommer att se ett kluster av 12 vektorer som är klustrade i en inbäddning och ett anmärkningsvärt liknande kluster i den andra inbäddningen. "Modellen vet inte att det är månader, " Alvarez-Melis säger. "Den vet bara att det finns ett kluster med 12 punkter som är i linje med ett kluster på 12 punkter på det andra språket, men de skiljer sig från resten av orden, så de går nog bra ihop. Genom att hitta dessa överensstämmelser för varje ord, den anpassar sedan hela utrymmet samtidigt."
Forskarna hoppas att arbetet fungerar som en "genomförbarhetskontroll, Jaakkola säger, att tillämpa Gromov-Wasserstein-metoden på maskinöversättningssystem för att köra snabbare, mer effektivt, och få tillgång till många fler språk.
Dessutom, en möjlig fördel med modellen är att den automatiskt producerar ett värde som kan tolkas som kvantifierande, på en numerisk skala, likheten mellan språken. Detta kan vara användbart för lingvistiska studier, säger forskarna. Modellen beräknar hur långt alla vektorer är från varandra i två inbäddningar, vilket beror på meningsbyggnad och andra faktorer. Om alla vektorer är riktigt nära, de kommer att få närmare 0, och ju längre ifrån varandra de är, desto högre poäng. Liknande romanska språk som franska och italienska, till exempel, poäng nära 1, medan klassisk kinesiska får mellan 6 och 9 med andra större språk.
"Detta ger dig en trevlig, enkelt tal för hur lika språk är ... och kan användas för att få insikter om relationerna mellan språk, " säger Alvarez-Melis.
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.














