Exempel på full videoram som kommenteras med den nya metoden. Kredit:Růžička och Franchetti.
Forskare vid Carnegie Mellon University har nyligen utvecklat en ny modell som möjliggör snabb och exakt objektdetektering i högupplösta 4K- och 8K-videofilmer med hjälp av GPU:er. Deras uppmärksamhetspipeline-metod utför en tvåstegsutvärdering av varje bild- eller videoram under grov och raffinerad upplösning, begränsa det totala antalet nödvändiga utvärderingar.
På senare år har maskininlärning har uppnått anmärkningsvärda resultat i datorseende uppgifter, inklusive objektdetektering. Dock, de flesta objektigenkänningsmodeller fungerar vanligtvis bäst på bilder med relativt låg upplösning. Eftersom upplösningen för inspelningsenheter snabbt förbättras, det finns ett ökande behov av verktyg som kan bearbeta högupplösta data.
"Vi var intresserade av att hitta och övervinna begränsningarna med nuvarande tillvägagångssätt, " Vít Růžička, en av forskarna som genomförde studien berättade för TechXplore. "Medan många datakällor spelar in i hög upplösning, nuvarande toppmoderna objektdetekteringsmodeller, som YOLO, Snabbare RCNN, SSD, etc., arbeta med bilder som har en relativt låg upplösning på cirka 608 x 608 px. Vårt huvudmål var att skala objektdetekteringsuppgiften till 4K-8K-videor (upp till 7680 x 4320 px) med bibehållen hög bearbetningshastighet. Vi ville också förstå om och hur mycket vi kan dra nytta av hög upplösning jämfört med att använda lågupplösta bilder, när det gäller modellernas noggrannhet."
Den uppmärksamhetspipeline som Růžička och hans kollega Franz Franchetti föreslagit delar upp uppgiften att detektera objekt i två steg. I båda dessa stadier, forskarna delade upp originalbilden genom att lägga över den med ett vanligt rutnät och använde sedan modellen YOLO v2 för snabb objektdetektering.
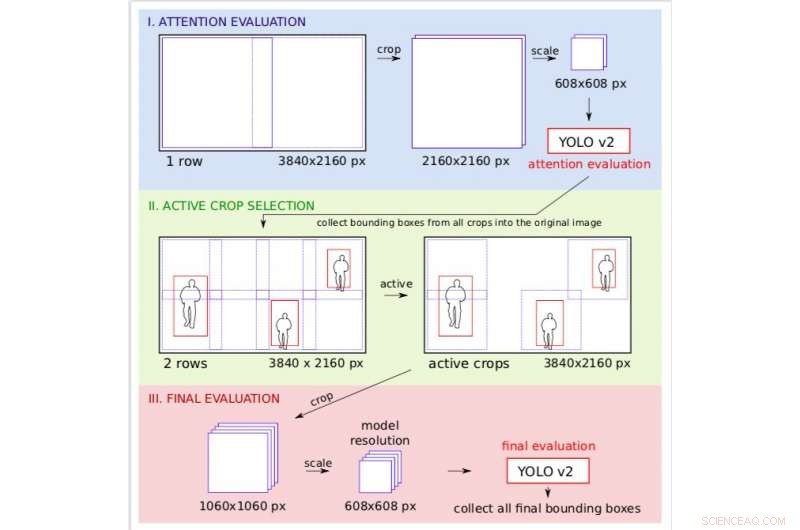
Upplösningshantering på exemplet med 4K-videoramsbehandling. Under uppmärksamhetssteget bearbetas bilden under grov upplösning, så att forskarna kan bestämma vilka delar av bilden som ska vara aktiva i den slutliga finare utvärderingen. Kredit:Růžička och Franchetti.
"Vi skapar många små rektangulära grödor, som kan bearbetas av YOLO v2 på flera serverarbetare, på ett parallellt sätt, " Růžička förklarade. "Det första steget tittar på bilden nedskalad till lägre upplösning och utför en snabb objektdetektering för att få grova begränsningsrutor. Det andra steget använder dessa begränsningsrutor som en uppmärksamhetskarta för att bestämma var vi behöver kontrollera bilden med hög upplösning. Därför, när vissa delar av bilden inte innehåller något föremål av intresse, vi kan spara på att behandla dem under hög upplösning."
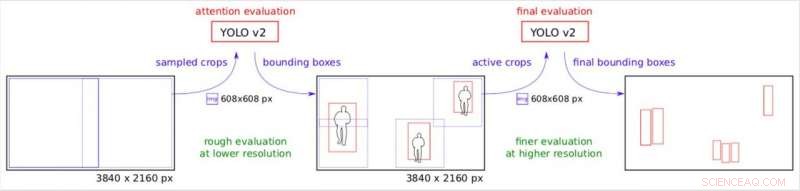
Uppmärksamhetspipen. Stegvis uppdelning av originalbilden under annan effektiv upplösning. Kredit:Růžička och Franchetti.
Forskarna implementerade sin modell i kod, distribuera sitt arbete över GPU:er. De kunde bibehålla hög noggrannhet samtidigt som de nådde en genomsnittlig prestanda på tre till sex fps på 4K-videor och två fps på 8K-videor. Deras metod gav betydande fördelar, med den uppmätta genomsnittliga precisionen på den testade datamängden ökande från 33,6 AP 50 till 74,3 AP 50 vid bearbetning av bilder i hög upplösning jämfört med nedskalning av bilder till låg upplösning, vilket är hur YOLO v2 i allmänhet fungerar.
"Vår metod minskade den tid som krävs för att bearbeta högupplösta bilder med cirka 20 procent, jämfört med att bearbeta varje del av originalbilden under hög upplösning, " Růžička sa. "Den praktiska innebörden av detta är att nära realtid 4K-videobehandling är möjlig. Vår metod kräver också ett lägre antal serverarbetare för att slutföra denna uppgift."
Trots de mycket lovande resultaten som uppnåtts med denna nya objektdetekteringsmetod, Användningen av ett vanligt rutnät som överlagrar originalbilden kan ge upphov till ett antal problem. Till exempel, det kan ibland resultera i att upptäckta föremål skärs på mitten, vilket kräver ett efterbearbetningssteg på de upptäckta begränsningsrutorna. Růžička och Franchetti undersöker för närvarande sätt att ta itu med och kringgå dessa problem för att förbättra sin modell ytterligare.
© 2018 Science X Network