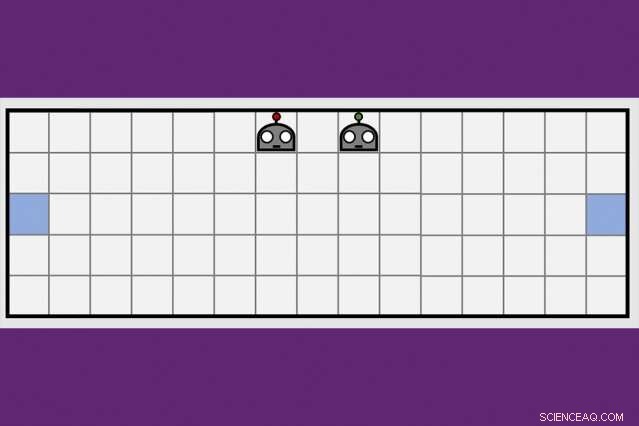
Med hjälp av en ny teknik för kooperativ inlärning, MIT-IBM Watson AI Lab-forskare minskade med hälften av tiden det tog ett par robotagenter att lära sig manövrera till motsatta sidor av ett virtuellt rum. Kredit:Dong-ki Kim
De första artificiella intelligensprogrammen för att besegra världens bästa spelare i schack och spelet Go fick åtminstone en del instruktioner av människor, och slutligen, skulle inte visa sig matcha en ny generation av AI-program som lär sig helt på egen hand, genom försök och misstag.
En kombination av djupinlärning och förstärkande inlärningsalgoritmer är ansvariga för att datorer uppnår dominans i utmanande brädspel som schack och Go, ett växande antal videospel, inklusive Ms Pac-Man, och några kortspel, inklusive poker. Men trots alla framsteg, datorer fastnar fortfarande ju närmare ett spel liknar det verkliga livet, med dold information, flera spelare, kontinuerligt spel, och en blandning av kort- och långsiktiga belöningar som gör beräkningen till det optimala draget hopplöst komplicerat.
För att komma förbi dessa hinder, AI-forskare undersöker kompletterande tekniker för att hjälpa robotagenter att lära sig, modellerad efter hur människor hämtar ny information inte bara på egen hand, men från människorna omkring oss, och från tidningar, böcker, och andra medier. En strategi för kollektivt lärande utvecklad av MIT-IBM Watson AI Lab erbjuder en lovande ny riktning. Forskare visar att ett par robotagenter kan minska tiden det tar att lära sig en enkel navigationsuppgift med 50 procent eller mer när agenterna lär sig att utnyttja varandras växande kunskap.
Algoritmen lär agenterna när de ska be om hjälp, och hur man kan skräddarsy sina råd till vad man har lärt sig fram till dess. Algoritmen är unik genom att ingen av agenterna är experter; var och en är fri att agera som elev-lärare för att begära och erbjuda mer information. Forskarna presenterar sitt arbete denna vecka vid AAAI-konferensen om artificiell intelligens på Hawaii.
Medförfattare på tidningen, som fick ett hedersomnämnande för bästa studentuppsats vid AAAI, är Jonathan How, en professor vid MIT:s institution för flygteknik och astronautik; Shayegan Omidshafiei, en före detta MIT doktorand nu vid Alphabet's DeepMind; Dong-ki Kim från MIT; Miao Liu, Gerald Tesauro, Matthew Riemer, och Murray Campbell från IBM; och Christopher Amato från Northeastern University.
"Denna idé att tillhandahålla åtgärder för att på bästa sätt förbättra elevens lärande, istället för att bara berätta vad den ska göra, är potentiellt ganska kraftfull, " säger Matthew E. Taylor, en forskningschef på Borealis AI, forskningsdelen av Royal Bank of Canada, som inte var involverad i forskningen. "Medan tidningen fokuserar på relativt enkla scenarier, Jag tror att elev-/lärarramverket skulle kunna skalas upp och vara användbart i videospel för flera spelare som Dota 2, robot fotboll, eller scenarier för återhämtning från katastrofer."
Tills vidare, proffsen har fortfarande fördelen i Dota2, och andra virtuella spel som gynnar lagarbete och snabb, strategiskt tänkande. (Även om Alphabets AI-forskningsarm, DeepMind, nyligen gjort nyheter efter att ha besegrat en professionell spelare i realtidsstrategispelet, Starcraft.) Men när maskiner blir bättre på att manövrera dynamiska miljöer, de kan snart vara redo för verkliga uppgifter som att hantera trafik i en storstad eller koordinera sök- och räddningsteam på marken och i luften.
"Maskiner saknar den vettiga kunskap vi utvecklar som barn, säger Liu, en före detta MIT postdoc nu vid MIT-IBM-labbet. "Det är därför de behöver titta på miljontals videorutor, och spendera mycket beräkningstid, lära sig spela ett spel bra. Även då, de saknar effektiva sätt att överföra sin kunskap till teamet, eller generalisera sina färdigheter till ett nytt spel. Om vi kan träna robotar att lära av andra, och generalisera sitt lärande till andra uppgifter, vi kan börja bättre samordna deras interaktioner med varandra, och med människor."
MIT-IBM-teamets nyckelinsikt var att ett team som delar och erövrar för att lära sig en ny uppgift – i det här fallet, manövrera till motsatta ändar av ett rum och vidröra väggen samtidigt - lär sig snabbare.
Deras undervisningsalgoritm växlar mellan två faser. I den första, både elev och lärare bestämmer för varje steg om de ska be om, eller ge, råd baserat på deras tilltro till nästa steg, eller de råd de ska ge, kommer att föra dem närmare sitt mål. Således, eleven ber bara om råd, och läraren bara ger det, när den tillagda informationen sannolikt kommer att förbättra deras prestanda. För varje steg, agenterna uppdaterar sina respektive uppgiftspolicyer och processen fortsätter tills de når sitt mål eller tar slut.
Med varje iteration, algoritmen registrerar elevens beslut, lärarens råd, och deras inlärningsframsteg mätt med spelets slutresultat. I den andra fasen, en teknik för inlärning av djup förstärkning använder tidigare registrerade undervisningsdata för att uppdatera båda rådgivningspolicyerna. "Med varje uppdatering blir läraren bättre på att ge rätt råd vid rätt tidpunkt, säger Kim, en doktorand vid MIT.
I ett uppföljningsdokument som ska diskuteras i en workshop på AAAI, forskarna förbättrar algoritmens förmåga att spåra hur väl agenterna lär sig den underliggande uppgiften – i det här fallet, en boxpressande uppgift — att förbättra agenternas förmåga att ge och ta emot råd. Det är ytterligare ett steg som tar laget närmare sitt långsiktiga mål att gå in i RoboCup, en årlig robottävling som startats av akademiska AI-forskare.
"Vi skulle behöva skala till 11 agenter innan vi kan spela fotboll, säger Tesauro, en IBM-forskare som utvecklade det första AI-programmet för att bemästra spelet backgammon. "Det kommer att ta lite mer arbete men vi är hoppfulla."
Den här historien återpubliceras med tillstånd av MIT News (web.mit.edu/newsoffice/), en populär webbplats som täcker nyheter om MIT-forskning, innovation och undervisning.