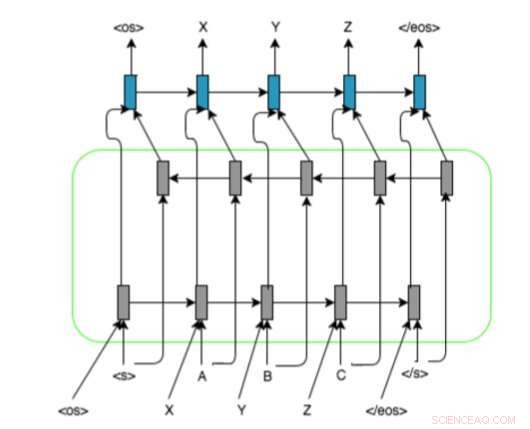
Forskarnas RNN-baserade modellarkitektur med kodare-avkodare dubbelriktad LSTM och justeringsrepresentation på ingångssekvenser. De använder och, , och markörer för att stoppa grafem/fonemsekvenserna till en bestämd längd. Upphovsman:Ngoc Tan Le et al.
Ett team av forskare vid Universite du Quebec vid Montreal och Vietnam National University Ho Chi Minh (VNU-HCM) har nyligen utvecklat ett tillvägagångssätt för maskintranslitering baserat på återkommande neurala nätverk (RNN). Translitteration innebär den fonetiska översättningen av ord på ett givet källspråk (t.ex. franska) till likvärdiga ord på ett målspråk (t.ex. vietnamesiska).
Via translitteration, ett enskilt ord omvandlas till ett fonetiskt ekvivalent ord i ett annat skrivsystem. Denna omvandling bygger vanligtvis på en stor uppsättning regler som definieras av lingvister, som avgör hur fonem är inriktade, med tanke på ett ords ursprung och målspråkets fonologiska system.
Under de senaste åren har forskare har utvecklat flera metoder för djupinlärning för maskinöversättning, som har visat sig vara ett värdefullt alternativ till befintliga statistiska metoder. Dessa lovande resultat motiverade teamet av forskare vid Universite du Quebec i Montreal och VNU-HCM att utveckla en djupinlärningsmetod för maskintranslitering.
Deras tillvägagångssätt använder återkommande neurala nätverk (RNN), eftersom dessa har visat sig vara särskilt användbara för att hantera liknande problem. Forskarna observerade att de flesta state-of-the-art grafem-till-fonem metoder var främst baserade på användningen av grafem-fonem mappningar, medan RNN inte kräver någon justeringsinformation.
"Grapheme-to-phoneme-modeller är nyckelkomponenter i automatisk taligenkänning och text-till-tal-system, "förklarade forskarna i sin artikel, som publicerades på ACM Digital Library. "Med språkresurser med låg resurs som inte har tillgängliga och välutvecklade uttallexikon, grafem-till-fonem-modeller är särskilt användbara. Dessa modeller är baserade på initiala anpassningar mellan grafemkällor och fonemmålsekvenser. "
I deras studie, forskarna introducerade en ny metod för att uppnå lågresursmaskin-translitteration, som använder RNN-baserade modeller och justeringsinformation för ingångssekvenser. Med ett ord på ett givet språk som inte finns i den tvåspråkiga uttalordboken, deras system kan automatiskt förutsäga sin fonemiska representation på målspråket.
"Inspirerad av sekvens-till-sekvens återkommande neurala nätverksbaserade översättningsmetoder, den aktuella forskningen presenterar ett tillvägagångssätt som tillämpar en justeringsrepresentation för ingångssekvenser och förutbildade käll- och målinbäddningar för att övervinna translittereringsproblemet för ett språk med låg resurs, "förklarade forskarna i sin artikel.
Detta nya tillvägagångssätt kombinerar flera djupinlärning och neurala nätverksbaserade tekniker, inklusive kodare-avkodare, uppmärksamhetsmekanismer, justeringsrepresentation för ingångssekvenser och förutbildade käll- och målinbäddningar. Forskarna utvärderade sin metod i en translitterationsuppgift som involverade fransk-vietnamesiska språkresurser med låg resurs, uppnå mycket lovande resultat.
"Utvärdering och experiment med franska och vietnamesiska visade att med endast en liten tvåspråkig uttalordlista tillgänglig för utbildning av translitterationsmodeller, lovande resultat uppnåddes, "skrev forskarna.
Enligt forskarna, deras studie var bland de första som analyserade det vietnamesiska språket i en translitterationsuppgift med RNN. Deras metod uppnådde anmärkningsvärda resultat, överträffar andra toppmoderna statistikbaserade och multijoint sekvensbaserade tillvägagångssätt.
Det nya systemet som forskarna har utvecklat kan effektivt och automatiskt lära sig språkliga regelbundenheter från små tvåspråkiga uttalordböcker. Även om deras studie specifikt tillämpade den på fransk-vietnamesiska translitterationsuppgifter, den kan också utvidgas till alla andra språk med låg resurs för vilka en tvåspråkig uttalord finns tillgänglig.
"I framtida arbete, vi tänker testa vårt föreslagna tillvägagångssätt med en större tvåspråkig uttalordlista samt att studera andra tillvägagångssätt, t.ex. halvövervakad eller icke-övervakad, "skrev forskarna i sin artikel." Vi tänker också undersöka överföringsinlärning med hjälp av andra NLP-uppgifter eller språk i inställningar med låg resurs. "
© 2019 Science X Network














