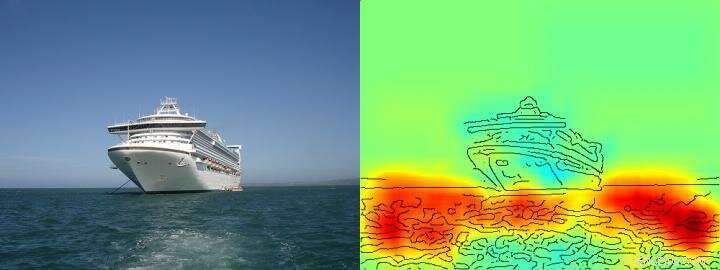
Värmekartan visar ganska tydligt att algoritmen fattar sitt ship/not ship-beslut på basis av pixlar som representerar vatten och inte på basis av pixlar som representerar fartyget. Kreditera: Naturkommunikation , CC BY licens
Artificiell intelligens (AI) och maskininlärningsarkitekturer som djupinlärning har blivit en integrerad del av vårt dagliga liv – de möjliggör digitala talassistenter eller översättningstjänster, förbättra medicinsk diagnostik och är en oumbärlig del av framtida teknologier som autonom körning. Baserat på en ständigt ökande mängd data och kraftfulla nya datorarkitekturer, inlärningsalgoritmer verkar närma sig mänskliga förmågor, ibland till och med överträffa dem. Än så länge, dock, det är ofta okänt för användarna hur exakt AI-system når sina slutsatser. Därför, det kan ofta förbli oklart om AI:s beslutsbeteende verkligen är intelligent eller om procedurerna bara är genomsnittligt framgångsrika.
Forskare från TU Berlin, Fraunhofer Heinrich Hertz Institute HHI och Singapore University of Technology and Design (SUTD) har tagit itu med denna fråga och har gett en inblick i det mångsidiga "intelligens"-spektrum som observeras i nuvarande AI-system, specifikt analysera dessa AI-system med en ny teknologi som möjliggör automatiserad analys och kvantifiering.
Den viktigaste förutsättningen för denna nya teknologi är en metod som utvecklats tidigare av TU Berlin och Fraunhofer HHI, den så kallade Layer-wise Relevance Propagation (LRP) algoritmen som tillåter visualisering enligt vilka indatavariabler AI-system fattar sina beslut. Förlänger LRP, den nya spektralrelevansanalysen (SpRAy) kan identifiera och kvantifiera ett brett spektrum av inlärt beslutsbeteende. På detta sätt har det nu blivit möjligt att upptäcka oönskat beslutsfattande även i mycket stora datamängder.
Denna så kallade "förklarliga AI" har varit ett av de viktigaste stegen mot en praktisk tillämpning av AI, enligt Dr Klaus-Robert Müller, professor i maskininlärning vid TU Berlin. "Särskilt i medicinsk diagnos eller i säkerhetskritiska system, inga AI-system som använder fläckiga eller till och med fuskande problemlösningsstrategier bör användas."
Genom att använda deras nyutvecklade algoritmer, forskare kan äntligen testa vilket existerande AI-system som helst och även härleda kvantitativ information om dem:ett helt spektrum som börjar från naivt problemlösningsbeteende, till fuskstrategier upp till mycket utarbetade "intelligenta" strategiska lösningar observeras.
Dr Wojciech Samek, gruppledare på Fraunhofer HHI sa:"Vi blev mycket förvånade över det breda utbudet av inlärda problemlösningsstrategier. Även moderna AI-system har inte alltid hittat en lösning som verkar meningsfull ur ett mänskligt perspektiv, men använde ibland så kallade Clever Hans Strategies."
Smart Hans var en häst som förment kunde räknas och ansågs vara en vetenskaplig sensation under 1900-talet. Som det upptäcktes senare, Hans behärskade inte matte, men i cirka 90 procent av fallen, han kunde härleda det korrekta svaret från frågeställarens reaktion.
Teamet kring Klaus-Robert Müller och Wojciech Samek upptäckte också liknande "Clever Hans"-strategier i olika AI-system. Till exempel, ett AI-system som vann flera internationella bildklassificeringstävlingar för några år sedan följde en strategi som kan anses vara naiv ur en mänsklig synvinkel. Den klassificerade bilder främst utifrån kontext. Bilder tilldelades kategorin "fartyg" när det var mycket vatten i bilden. Andra bilder klassades som "tåg" om räls fanns. Ytterligare andra bilder tilldelades rätt kategori av deras copyright-vattenstämpel. Den verkliga uppgiften, nämligen att upptäcka begreppen fartyg eller tåg, löstes därför inte av detta AI-system – även om det verkligen klassificerade majoriteten av bilderna korrekt.
Forskarna kunde också hitta dessa typer av felaktiga problemlösningsstrategier i några av de senaste AI-algoritmerna, de så kallade djupa neurala nätverken – algoritmer som hade ansetts vara immuna mot sådana förfall. Dessa nätverk baserade sina klassificeringsbeslut delvis på artefakter som skapades under framställningen av bilderna och har ingenting att göra med det faktiska bildinnehållet.
"Sådana AI-system är inte användbara i praktiken. Deras användning i medicinsk diagnostik eller i säkerhetskritiska områden skulle till och med innebära enorma faror, ", sa Klaus-Robert Müller. "Det är ganska tänkbart att ungefär hälften av de AI-system som för närvarande används implicit eller explicit förlitar sig på sådana Clever Hans-strategier. Det är dags att systematiskt kontrollera det så att säkra AI-system kan utvecklas."
Med sin nya teknik, forskarna identifierade också AI-system som oväntat har lärt sig "smarta" strategier. Exempel inkluderar system som har lärt sig att spela Atari-spelen Breakout och Pinball. "Här, AI:n förstod tydligt konceptet med spelet, och hittade ett intelligent sätt att samla många poäng på ett riktat och lågrisksätt. Systemet ingriper ibland till och med på sätt som en riktig spelare inte skulle göra, sa Wojciech Samek.
"Utöver att förstå AI-strategier, vårt arbete etablerar användbarheten av förklarlig AI för iterativ datauppsättningsdesign, nämligen för att ta bort artefakter i en datauppsättning som skulle få en AI att lära sig felaktiga strategier, samt hjälpa till att bestämma vilka omärkta exempel som behöver kommenteras och läggas till så att fel i ett AI-system kan minskas, " sa SUTD biträdande professor Alexander Binder.
"Vår automatiserade teknik är öppen källkod och tillgänglig för alla forskare. Vi ser vårt arbete som ett viktigt första steg för att göra AI-system mer robusta, förklaras och säker i framtiden, och fler kommer att behöva följa. Detta är en väsentlig förutsättning för allmän användning av AI, sa Klaus-Robert Müller.