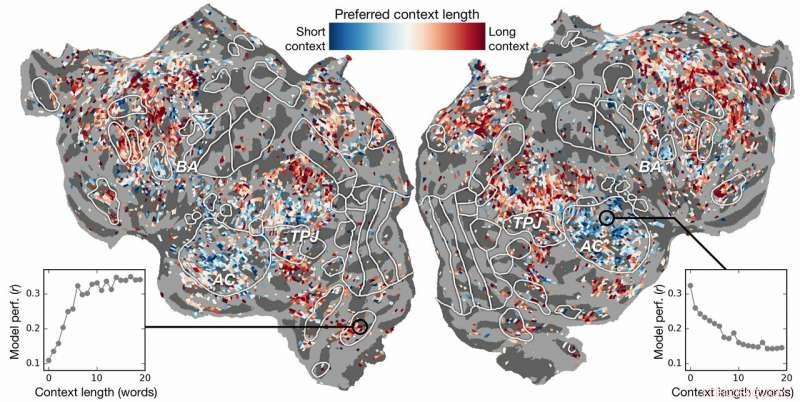
Kontextlängdpreferens över cortex. Ett index för kontextlängdpreferens beräknas för varje voxel i ett ämne och projiceras på det ämnets kortikala yta. Voxlar som visas i blått modelleras bäst med korta sammanhang, medan röda voxlar bäst modelleras med långa sammanhang. Kredit:Huth lab, UT Austin
Kan artificiell intelligens (AI) hjälpa oss att förstå hur hjärnan förstår språk? Kan neurovetenskap hjälpa oss att förstå varför AI och neurala nätverk är effektiva för att förutsäga mänsklig perception?
Forskning från Alexander Huth och Shailee Jain från University of Texas i Austin (UT Austin) tyder på att båda är möjliga.
I ett dokument som presenterades vid 2018 års konferens om neurala informationsbehandlingssystem (NeurIPS), forskarna beskrev resultaten av experiment som använde artificiella neurala nätverk för att förutsäga med större noggrannhet än någonsin tidigare hur olika områden i hjärnan svarar på specifika ord.
"När ord kommer in i våra huvuden, vi bildar idéer om vad någon säger till oss, och vi vill förstå hur det kommer till oss i hjärnan, sade Huth, biträdande professor i neurovetenskap och datavetenskap vid UT Austin. "Det verkar som att det borde finnas system för det, men praktiskt taget det är bara inte så språk fungerar. Som allt annat inom biologi, det är väldigt svårt att reducera ner till en enkel uppsättning ekvationer."
Arbetet använde en typ av återkommande neurala nätverk som kallas långtidsminne (LSTM) som inkluderar i sina beräkningar relationerna mellan varje ord och det som kom tidigare för att bättre bevara sammanhanget.
"Om ett ord har flera betydelser, du härleder betydelsen av det ordet för den specifika meningen beroende på vad som sades tidigare, sa Jain, en Ph.D. student i Huths labb vid UT Austin. "Vår hypotes är att detta skulle leda till bättre förutsägelser av hjärnaktivitet eftersom hjärnan bryr sig om sammanhang."
Det låter självklart, men i decennier har neurovetenskapliga experiment betraktat hjärnans svar på enskilda ord utan en känsla av deras koppling till ordkedjor eller meningar. (Huth beskriver vikten av att göra "verkliga neurovetenskap" i en uppsats från mars 2019 i Journal of Cognitive Neuroscience .)
I sitt arbete, forskarna körde experiment för att testa, och i slutändan förutsäga, hur olika områden i hjärnan skulle reagera när man lyssnar på berättelser (särskilt, Moth Radio Hour). De använde data som samlats in från fMRI-maskiner (functional magnetic resonance imaging) som fångar förändringar i blodets syresättningsnivå i hjärnan baserat på hur aktiva grupper av neuroner är. Detta fungerar som en korrespondent för var språkbegrepp är "representerade" i hjärnan.
Använder kraftfulla superdatorer vid Texas Advanced Computing Center (TACC), de tränade en språkmodell med LSTM-metoden så att den effektivt kunde förutsäga vilket ord som skulle komma härnäst – en uppgift som liknar Googles automatiska kompletteringssökningar, som det mänskliga sinnet är särskilt skickligt på.
"När jag försöker förutsäga nästa ord, den här modellen måste implicit lära sig allt det här andra om hur språk fungerar, sade Huth, "som vilka ord tenderar att följa andra ord, utan att någonsin komma åt hjärnan eller någon data om hjärnan."
Baserat på både språkmodellen och fMRI-data, de tränade ett system som kunde förutsäga hur hjärnan skulle reagera när den hör varje ord i en ny berättelse för första gången.
Tidigare försök hade visat att det är möjligt att lokalisera språksvar i hjärnan effektivt. Dock, den nya forskningen visade att genom att lägga till det kontextuella elementet – i det här fallet upp till 20 ord som kom tidigare – förbättrades förutsägelser av hjärnaktivitet avsevärt. De fann att deras förutsägelser förbättras även när minsta möjliga sammanhang användes. Ju mer sammanhang som ges, desto bättre är träffsäkerheten i deras förutsägelser.
"Vår analys visade att om LSTM innehåller fler ord, då blir det bättre på att förutsäga nästa ord, sa Jain, "vilket betyder att det måste innehålla information från alla ord i det förflutna."
Forskningen gick längre. Den undersökte vilka delar av hjärnan som var mer känsliga för mängden sammanhang som ingår. De hittade, till exempel, att begrepp som verkar vara lokaliserade till hörselbarken var mindre beroende av sammanhang.
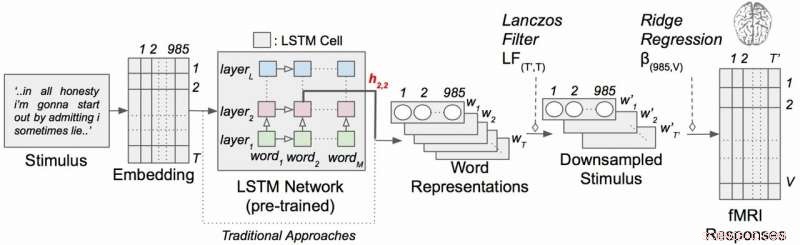
Kontextuell språkkodningsmodell med narrativa stimuli. Varje ord i berättelsen projiceras först in i ett 985-dimensionellt inbäddningsutrymme. Sekvenser av ordrepresentationer matas sedan in i ett LSTM-nätverk som var förutbildat som en språkmodell. Kredit:Huth lab, UT Austin
"Om du hör ordet hund, detta område bryr sig inte om vad de 10 orden var innan dess, det kommer bara att svara på ljudet av ordet hund", Huth förklarade.
Å andra sidan, hjärnområden som handlar om tänkande på högre nivå var lättare att peka ut när mer sammanhang inkluderades. Detta stödjer teorier om sinnet och språkförståelse.
"Det var en riktigt bra överensstämmelse mellan hierarkin i det konstgjorda nätverket och hierarkin i hjärnan, som vi tyckte var intressant, " sa Huth.
Naturlig språkbehandling – eller NLP – har tagit stora framsteg de senaste åren. Men när det gäller att svara på frågor, ha naturliga konversationer, eller analysera känslorna i skrivna texter, NLP har fortfarande en lång väg att gå. Forskarna tror att deras LSTM-utvecklade språkmodell kan hjälpa till inom dessa områden.
LSTM (och neurala nätverk i allmänhet) fungerar genom att tilldela värden i högdimensionellt utrymme till enskilda komponenter (här, ord) så att varje komponent kan definieras av dess tusentals olika relationer till många andra saker.
Forskarna tränade språkmodellen genom att mata den med tiotals miljoner ord från Reddit-inlägg. Deras system gjorde sedan förutsägelser för hur tusentals voxlar (tredimensionella pixlar) i hjärnan hos sex försökspersoner skulle svara på en andra uppsättning berättelser som varken modellen eller individerna hade hört tidigare. Eftersom de var intresserade av effekterna av kontextlängd och effekten av enskilda lager i det neurala nätverket, de testade i huvudsak 60 olika faktorer (20 längder av sammanhangsbevarande och tre olika lagerdimensioner) för varje ämne.
Allt detta leder till beräkningsproblem av enorm skala, kräver enorma mängder datorkraft, minne, lagring, och datahämtning. TACC:s resurser var väl lämpade för problemet. Forskarna använde Maverick superdator, som innehåller både GPU:er och processorer för datoruppgifterna, och Corral, en lagrings- och datahanteringsresurs, att bevara och distribuera data. Genom att parallellisera problemet över många processorer, de kunde köra beräkningsexperimentet på veckor snarare än år.
"För att utveckla dessa modeller effektivt, du behöver mycket träningsdata, " sade Huth. "Det betyder att du måste passera igenom hela din datauppsättning varje gång du vill uppdatera vikterna. Och det är i grunden väldigt långsamt om du inte använder parallella resurser som de hos TACC."
Om det låter komplicerat, väl – det är det.
Detta leder till att Huth och Jain överväger en mer strömlinjeformad version av systemet, där istället för att utveckla en språkprediktionsmodell och sedan tillämpa den på hjärnan, de utvecklar en modell som direkt förutsäger hjärnans reaktion. De kallar detta för ett heltäckande system och det är dit Huth och Jain hoppas att gå i sin framtida forskning. En sådan modell skulle förbättra sin prestanda direkt på hjärnans svar. En felaktig förutsägelse av hjärnaktivitet skulle återkoppla till modellen och stimulera till förbättringar.
"Om det här fungerar, då är det möjligt att detta nätverk kan lära sig att läsa text eller inta språk på samma sätt som våra hjärnor gör, " sa Huth. "Föreställ dig Google Translate, men den förstår vad du säger, istället för att bara lära sig en uppsättning regler."
Med ett sådant system på plats, Huth tror att det bara är en tidsfråga innan ett tankeläsningssystem som kan översätta hjärnaktivitet till språk är genomförbart. Sålänge, de får insikter i både neurovetenskap och artificiell intelligens från sina experiment.
"Hjärnan är en mycket effektiv beräkningsmaskin och syftet med artificiell intelligens är att bygga maskiner som är riktigt bra på alla uppgifter en hjärna kan göra, " sa Jain. "Men, vi förstår inte mycket om hjärnan. Så, vi försöker använda artificiell intelligens för att först ifrågasätta hur hjärnan fungerar, och då, baserat på de insikter vi får genom denna förhörsmetod, och genom teoretisk neurovetenskap, vi använder dessa resultat för att utveckla bättre artificiell intelligens.
"Tanken är att förstå kognitiva system, både biologiska och konstgjorda, och att använda dem tillsammans för att förstå och bygga bättre maskiner."