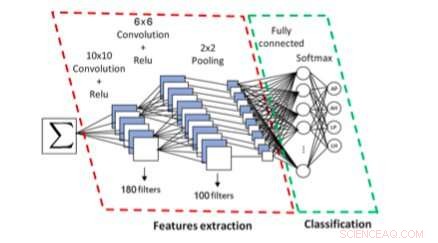
Det CNN-baserade systemet för symbolskript och typidentifiering. Kredit:Khazri &Echi.
Forskare vid universitetet i Tunis har nyligen föreslagit ett nytt system för matematisk formelskript och typidentifiering, som är baserad på konvolutionella neurala nätverk (CNN). Deras metod, presenteras i en artikel publicerad av Springer, kan automatiskt skilja mellan tryckta/handskrivna och arabiska/latinska formler.
På senare år har Forskare har försökt utveckla system som kan identifiera i vilka former ett dokument presenteras, som språket som används och om texten är maskintryckt eller handskriven, för att välja lämpligt igenkänningssystem för varje dokument. De flesta av dessa tillvägagångssätt fokuserar på att identifiera olika former av text, medan väldigt få är utformade för att analysera matematiska formler.
"I detta sammanhang, vi presenterar ett nytt tillvägagångssätt som hanterar problemet med identifiering av manuset, arabiska eller latinska; och typen, handskriven eller maskintryckt, av matematiska formler, " skrev forskarna vid University of Tunis i sin uppsats. "Detta arbete kommer som en del av vår forskning om offlineigenkänning av arabiska matematiska formler."
I sin studie, forskarna presenterade ett syntaxstyrt system utformat för att känna igen symboler och analysera deras arrangemang. För att känna igen symboler, deras tillvägagångssätt använder statistiska funktioner och en Bayes nätverksklassificerare.
För att analysera strukturen för en formel, deras system använder ett uppifrån-och-ned-och nerifrån-upp-parsing-schema baserat på operatörsdominans. Med andra ord, deras system utför en lexikal, geometrisk och syntaktisk analys av en formel, vilket hjälper det att identifiera sitt manus (latin vs. arabiska) och om det var handskrivet eller maskintypat.
"Formelanalys består i att tillämpa, från den dominerande operatören och dess sammanhang, lämplig regel för att dela upp formlerna i underformler, som kommer att analyseras rekursivt på samma sätt, "förklarade forskarna i sin artikel.
Med hjälp av ett CNN, det tillvägagångssätt som utarbetats av forskarna extraherar först och klassificerar sedan sammankopplade komponenter i en formel. Forskarna utbildade och utvärderade sitt system med hjälp av latinska skriftformler från InftyMDB-1 och CROHME-databaser, samt arabiska formler skannade från matteböcker eller handskrivna av fem olika författare.
"Det föreslagna igenkänningssystemet testades på komplexa matematiska formler som innehåller implicit multiplikation, nedsänkta och upphöjda, med tillfredsställande resultat, ", skrev forskarna. "Lägger till fler funktioner, att testa andra funktionsvalsalgoritmer och välja snabbare klassificerare borde förbättra prestandan hos det föreslagna systemet."
Övergripande, forskarnas utvärderingar gav mycket lovande resultat, med att deras system uppnår en identifieringstakt på 94,6 procent. Parsern de använde för att analysera formlers struktur verkar också vara mycket robust, eftersom det uppnådde en imponerande kännedomsgrad på 97,63 procent. I deras framtida arbete, forskarna planerar att förbättra prestandan för sitt system genom att vidareutveckla CNN:s filter och arkitektur.
© 2019 Science X Network