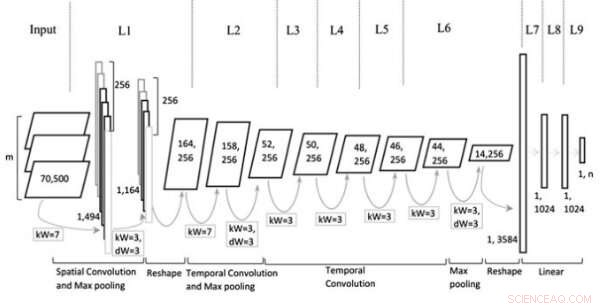
Modellarkitektur. Upphovsman:Jin et al, Wiley Computational Intelligence journal.
Under det senaste decenniet eller så, konvolutionella neurala nätverk (CNN) har visat sig vara mycket effektiva för att hantera en mängd olika uppgifter, inklusive naturliga språkbearbetningsuppgifter (NLP). NLP innebär användning av beräkningstekniker för att analysera eller syntetisera språk, både skriftligt och talat. Forskare har framgångsrikt tillämpat CNN på flera NLP -uppgifter, inklusive semantisk analys, sökfrågehämtning och textklassificering.
Vanligtvis, CNN -utbildade för textklassificeringsuppgifter behandlar meningar på ordnivå, representerar enskilda ord som vektorer. Även om detta tillvägagångssätt kan verka förenligt med hur människor bearbetar språk, nyligen genomförda studier har visat att CNN som behandlar meningar på karaktärsnivå också kan uppnå anmärkningsvärda resultat.
En viktig fördel med analyser på teckennivå är att de inte kräver förkunskaper i ord. Detta gör det lättare för CNN att anpassa sig till olika språk och skaffa onormala ord som orsakas av felstavning.
Tidigare studier tyder på att olika nivåer av textinbäddning (dvs. tecken-, ord-, eller -dokumentnivå) är mer effektiva för olika typer av uppgifter, men det finns fortfarande ingen tydlig vägledning om hur man väljer rätt inbäddning eller när man ska byta till en annan. Med detta i åtanke, ett team av forskare vid Tianjin Polytechnic University i Kina har nyligen utvecklat en ny CNN -arkitektur baserad på typer av representation som vanligtvis används i textklassificeringsuppgifter.
"Vi föreslår en ny arkitektur för CNN baserad på flera representationer för textklassificering genom att konstruera flera plan så att mer information kan dumpas i nätverken, t.ex. olika textdelar som erhållits genom en namngiven enhetsigenkänning eller taggningsverktyg för talord, olika nivåer av textinbäddning eller kontextuella meningar, "skrev forskarna i sin artikel.
Den multirepresentativa CNN-modellen (Mr-CNN) som forskarna tagit fram bygger på antagandet att alla delar av skriven text (t.ex. substantiv, verb, etc.) spelar en nyckelroll i klassificeringsuppgifter och att olika textinbäddningar är mer effektiva för olika ändamål. Deras modell kombinerar två viktiga verktyg, den Stanford-namngivna enhetsigenkänaren (NER) och taggar för POS-ord (part-of-speech). Den förra är en metod för att märka semantiska roller i saker i texter (t.ex. person, företag, etc.); den senare är en teknik som används för att tilldela en del av taltaggarna till varje textblock (t.ex. substantiv eller verb).
Forskarna använde dessa verktyg för att förbehandla meningar, få flera delmängder av den ursprungliga meningen, som alla innehåller specifika typer av ord i texten. De använde sedan delmängderna och hela meningen som flera representationer för deras Mr-CNN-modell.
Vid utvärdering av textklassificeringsuppgifter med text från olika storskaliga och domänspecifika datamängder, Mr-CNN-modellen uppnådde enastående prestanda, med högst 13 procent förbättrad felfrekvens på en datauppsättning och 8 procent förbättring på en annan. Detta tyder på att flera representationer av text gör att nätverket adaptivt kan fokusera sin uppmärksamhet på den mest relevanta informationen, förbättra klassificeringsförmågan.
"Olika storskaliga, domänspecifika datamängder användes för att validera den föreslagna arkitekturen, "forskarna skrev." Uppgifter som analyseras inkluderar ontologi dokument klassificering, kategorisering av biomedicinsk händelse, och sentimentanalys, visar att CNN:er med flera representationer, som lär sig att fokusera uppmärksamhet på specifika representationer av text, kan få ytterligare prestationsvinster jämfört med toppmoderna djupa neurala nätverksmodeller. "
I deras framtida arbete, forskarna planerar att undersöka om finkorniga funktioner kan hjälpa till att förhindra överanpassning av träningsdatasetet. De vill också utforska andra metoder som kan förbättra analysen av specifika delar av meningar, möjligen förbättrar modellens prestanda ytterligare.
© 2019 Science X Network