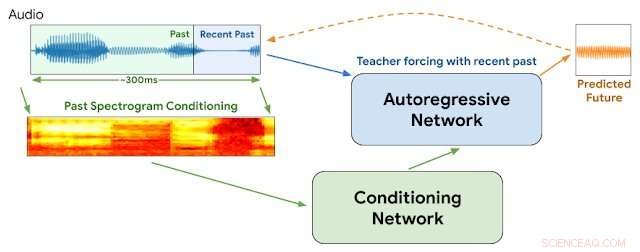
WaveNetEQ-arkitektur. Under slutledning, vi "värmer upp" det autoregressiva nätverket genom att lärare tvingar med det senaste ljudet. Efteråt, modellen levereras med egen utgång som ingång för nästa steg. Ett MEL-spektrogram från en längre ljuddel används som ingång för konditioneringsnätverket. Kredit:Google
"Det är bra att höra din röst, du vet att det har gått så lång tid
Om jag inte får dina samtal, då blir allt fel...
Din röst över linjen ger mig en konstig känsla"
- Blondin, "Lägg på telefonen"
1978, Debbie Harry förde sitt new wave-band Blondie till toppen av listorna med en klagande berättelse om längtan efter att höra sin pojkväns röst på långt håll och insistera på att han inte skulle låta henne "hänga i telefonen".
Men frågorna uppstår:Tänk om det var 2020 och hon pratade över VOIP med intermittenta paketförluster, ljudjitter, nätverksfördröjningar och paketöverföringar som inte är i sekvens?
Det får vi aldrig veta.
Men Google tillkännagav denna vecka detaljer om en ny teknik för sin populära Duo-röst- och videoapp som kommer att hjälpa till att säkerställa smidigare röstöverföringar och minska tillfälliga luckor som ibland förstör internetbaserade anslutningar. Vi skulle vilja tro att Debbie skulle godkänna det.
Vi har alla upplevt ljudjitter på Internet. Det inträffar när ett eller flera paket med instruktioner som innefattar en ström av ljudinstruktioner försenas eller blandas ur funktion mellan den som ringer och lyssnar. Metoder som använder röstpaketbuffertar och artificiell intelligens kan i allmänhet jämna ut jitter på 20 millisekunder eller mindre. Men avbrotten blir mer märkbara när de saknade paketen blir 60 millisekunder och mer.
Google säger att praktiskt taget alla samtal upplever en viss datapaketförlust:en femtedel av alla samtal förlorar 3 procent av sitt ljud och en tiondel förlorar 8 procent.
Denna vecka, Googles forskare vid DeepMind-avdelningen rapporterade att de har börjat använda ett program som heter WaveNetEQ för att ta itu med dessa problem. Algoritmen utmärker sig på att fylla i tillfälliga ljudluckor med syntetiserade men naturligt klingande talelement. Att förlita sig på ett omfattande bibliotek med taldata, WaveNetEQ fyller i ljudluckor upp till 120 millisekunder. Sådana ljudbitswappar kallas PLC (Packet Loss concealments).
"WaveNetEQ är en generativ modell baserad på DeepMinds WaveRNN-teknik, " Googles AI-blogg rapporterade den 1 april, "som tränas med hjälp av en stor korpus av taldata för att realistiskt fortsätta korta talsegment, vilket gör det möjligt för den att fullständigt syntetisera den råa vågformen av saknat tal."
Programmet analyserade ljud från 100 högtalare på 48 språk, nollpunkten på "egenskaperna hos mänskligt tal i allmänhet, istället för egenskaperna hos ett specifikt språk, " förklarade rapporten.
Dessutom, ljudanalys testades i miljöer som erbjuder ett brett utbud av bakgrundsljud för att säkerställa korrekt igenkänning av högtalare på livliga trottoarer i staden, tågstationer eller cafeterier.
All WaveNetEQ-behandling måste köras på mottagarens telefon så att krypteringstjänsterna inte äventyras. Men det extra kravet på bearbetningshastighet är minimalt, Google hävdar. WaveNetEQ är "snabb nog att köras på en telefon, samtidigt som den ger den senaste ljudkvaliteten och en mer naturligt ljudande PLC än andra system som används för närvarande."
Ljudexempel som illustrerar ljudjitter och förbättringar med WabeNetEQ publiceras i Google Blog-rapporten.
© 2020 Science X Network