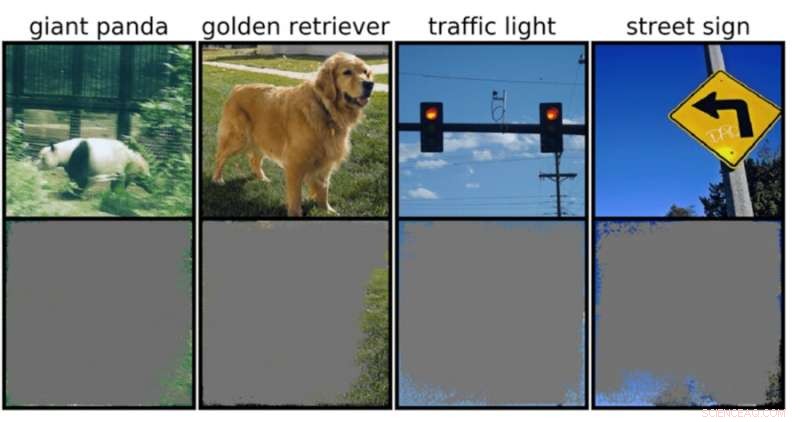
En djupbildsklassificerare kan bestämma bildklasser med över 90 procents tillförlitlighet genom att främst använda bildkanter, snarare än ett objekt i sig. Kredit:Rachel Gordon
Trots allt som neurala nätverk kan åstadkomma, förstår vi fortfarande inte riktigt hur de fungerar. Visst, vi kan programmera dem för att lära sig, men att förstå en maskins beslutsprocess förblir ungefär som ett fint pussel med ett svindlande, komplext mönster där massor av integrerade bitar ännu inte har monterats.
Om en modell försökte klassificera en bild av detta pussel, till exempel, kan den stöta på välkända, men irriterande motståndsattacker, eller till och med mer omfattande data eller bearbetningsproblem. Men en ny, mer subtil typ av misslyckande som nyligen identifierats av MIT-forskare är en annan anledning till oro:"övertolkning", där algoritmer gör säkra förutsägelser baserade på detaljer som inte är meningsfulla för människor, som slumpmässiga mönster eller bildgränser.
Detta kan vara särskilt oroande för miljöer med hög insats, som beslut på en del av en sekund för självkörande bilar och medicinsk diagnostik för sjukdomar som behöver mer omedelbar uppmärksamhet. Särskilt autonoma fordon förlitar sig starkt på system som exakt kan förstå omgivningen och sedan fatta snabba, säkra beslut. Nätverket använde specifika bakgrunder, kanter eller speciella mönster av himlen för att klassificera trafikljus och gatuskyltar – oavsett vad som fanns på bilden.
Teamet fann att neurala nätverk som tränats på populära datauppsättningar som CIFAR-10 och ImageNet led av övertolkning. Modeller tränade på CIFAR-10, till exempel, gjorde säkra förutsägelser även när 95 procent av ingångsbilderna saknades, och resten är meningslös för människor.
"Övertolkning är ett datauppsättningsproblem som orsakas av dessa meningslösa signaler i datauppsättningar. Dessa högsäkerhetsbilder är inte bara oigenkännliga, utan de innehåller mindre än 10 procent av originalbilden i oviktiga områden, som gränser. Vi fann att dessa bilder var meningslösa för människor, men ändå kan modeller klassificera dem med hög tillförsikt", säger Brandon Carter, Ph.D. på MIT Computer Science and Artificial Intelligence Laboratory. student och huvudförfattare på en artikel om forskningen.
Djupbildsklassificerare används ofta. Förutom medicinsk diagnostik och förstärkning av autonom fordonsteknologi finns det användningsfall inom säkerhet, spel och till och med en app som talar om för dig om något är eller inte är en korv, för ibland behöver vi trygghet. Tekniken i diskussionen fungerar genom att bearbeta enskilda pixlar från massor av förmärkta bilder för nätverket att "lära sig".
Bildklassificering är svårt, eftersom maskininlärningsmodeller har förmågan att fästa vid dessa nonsens subtila signaler. Sedan, när bildklassificerare tränas på datauppsättningar som ImageNet, kan de göra till synes tillförlitliga förutsägelser baserat på dessa signaler.
Även om dessa meningslösa signaler kan leda till modellbräcklighet i den verkliga världen, är signalerna faktiskt giltiga i datamängderna, vilket innebär att övertolkning inte kan diagnostiseras med typiska utvärderingsmetoder baserade på den noggrannheten.
För att hitta skälen till modellens förutsägelse om en viss indata, börjar metoderna i den föreliggande studien med hela bilden och frågar upprepade gånger, vad kan jag ta bort från denna bild? I grund och botten fortsätter den att dölja bilden tills du sitter kvar med den minsta biten som fortfarande fattar ett säkert beslut.
För det ändamålet skulle det också kunna vara möjligt att använda dessa metoder som en typ av valideringskriterier. Till exempel, om du har en självgående bil som använder en utbildad maskininlärningsmetod för att känna igen stoppskyltar, kan du testa den metoden genom att identifiera den minsta ingångsdelmängd som utgör en stoppskylt. Om det består av en trädgren, en viss tid på dygnet eller något som inte är en stoppskylt, kan du vara orolig för att bilen kan stanna på en plats den inte är avsedd för.
Även om det kan tyckas att modellen är den troliga boven här, är det mer sannolikt att datauppsättningarna får skulden. "Det finns frågan om hur vi kan modifiera datamängderna på ett sätt som skulle göra det möjligt för modeller att tränas för att närmare efterlikna hur en människa skulle tänka på att klassificera bilder och därför, förhoppningsvis, generalisera bättre i dessa verkliga scenarier, som autonom körning och medicinsk diagnos, så att modellerna inte har det här nonsensiva beteendet, säger Carter.
Detta kan innebära att man skapar datauppsättningar i mer kontrollerade miljöer. För närvarande är det bara bilder som extraheras från offentliga domäner som sedan klassificeras. Men om du till exempel vill göra objektidentifiering kan det vara nödvändigt att träna modeller med objekt med en oinformativ bakgrund.