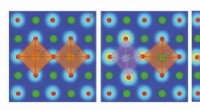
För att identifiera typen av en stolbild, information om stolens orientering (en störande faktor) går förlorad genom att glömma operationen (som går från vänster visualisering till höger). Kredit:University of Southern California
Tänk om nästa gång du ansöker om ett lån, en datoralgoritm bestämmer att du måste betala en högre avgift främst baserat på din ras, kön eller postnummer.
Nu, Föreställ dig att det var möjligt att träna en AI djupinlärningsmodell för att analysera den underliggande data genom att inducera minnesförlust:den glömmer viss data och fokuserar bara på andra.
Om du tänker att det här låter som datavetarens version av "The Eternal Sunshine of the Spotless Mind, " du skulle vara ganska bra. Och tack vare AI-forskare vid USC:s Information Sciences Institute (ISI), detta koncept, kallad motståndskraftig glömska, är nu en verklig mekanism.
Vikten av att ta itu med och ta bort fördomar i AI blir allt viktigare när AI blir allt vanligare i våra dagliga liv, noterade Ayush Jaiswal, tidningens huvudförfattare och Ph.D. kandidat vid USC Viterbi School of Engineering.
"AI och, mer specifikt, maskininlärningsmodeller ärver fördomar som finns i data de tränas på och är benägna att till och med förstärka dessa fördomar, " förklarade han. "AI används för att fatta flera verkliga beslut som påverkar oss alla, [såsom] fastställande av kreditgränser, godkänna lån, poängsättning av arbetsansökningar, etc. Om, till exempel, modeller för att fatta dessa beslut tränas blint på historiska data utan att kontrollera för partiskhet, de skulle lära sig att orättvist behandla individer som tillhör historiskt missgynnade delar av befolkningen, som kvinnor och färgade."
Forskningen leddes av Wael AbdAlmageed, forskargruppsledare vid ISI och en forskningsdocent vid USC Viterbis Ming Hsieh Department of Electrical and Computer Engineering, och forskningsdocent Greg Ver Steeg, liksom Premkumar Natarajan, forskningsprofessor i datavetenskap och verkställande direktör för ISI (ledig). Under deras ledning, Jaiswal och medförfattare Daniel Moyer, Ph.D., utvecklat den kontradiktoriska glömska metoden, som lär djupinlärningsmodeller att bortse från specifika, oönskade datafaktorer så att resultaten de producerar är opartiska och mer exakta.
Forskningsdokumentet, med titeln "Invariant representation through adversarial forgetting, " presenterades på konferensen Association for the Advancement for Artificial Intelligence i New York City den 10 februari, 2020.
Olägenheter och neurala nätverk
Deep learning är en kärnkomponent i AI och kan lära datorer hur man hittar korrelationer och gör förutsägelser med data, hjälpa till att identifiera personer eller föremål, till exempel. Modeller letar i huvudsak efter associationer mellan olika funktioner inom data och målet som det är tänkt att förutsäga. Om en modell fick i uppdrag att hitta en specifik person från en grupp, det skulle analysera ansiktsdrag för att skilja alla från varandra och sedan identifiera den riktade personen. Enkel, höger?
Tyvärr, saker går inte alltid så smidigt, eftersom modellen kan sluta lära sig saker som kan verka kontraintuitiva. Det kan associera din identitet med en viss bakgrund eller ljusinställning och inte kunna identifiera dig om belysningen eller bakgrunden har ändrats; det kan koppla din handstil till ett visst ord, och bli förvirrad om samma ord skrevs i någon annans handstil. Dessa passande benämningar olägenhetsfaktorer är inte relaterade till den uppgift du försöker utföra, och att felassociera dem med förutsägelsemålet kan faktiskt bli farligt.
Modeller kan också lära sig fördomar i data som är korrelerade med förutsägelsemålet men som är oönskade. Till exempel, i uppgifter som utförs av modeller som involverar historiskt insamlade socioekonomiska data, som att fastställa kreditpoäng, kreditgränser, och låneberättigande, modellen kan göra falska förutsägelser och visa fördomar genom att göra kopplingar mellan fördomarna och förutsägelsemålet. Det kan dra till slutsatsen att eftersom det analyserar data från en kvinna, hon måste ha en låg kreditpoäng; eftersom det analyserar data från en färgad person, de får inte vara berättigade till ett lån. Det råder ingen brist på berättelser om banker som kommer under beskyllning för sina algoritmers partiska beslut i hur mycket de tar ut människor som har tagit lån baserat på deras ras, kön, och utbildning, även om de har exakt samma kreditprofil som någon i ett mer socialt privilegierat befolkningssegment.
Som Jaiswal förklarade, den kontradiktoriska glömska mekanismen "fixar" neurala nätverk, som är kraftfulla modeller för djupinlärning som lär sig att förutsäga mål utifrån data. Kreditgränsen du fick på det nya kreditkortet du registrerade dig för? Ett neuralt nätverk analyserade sannolikt dina finansiella data för att komma fram till den siffran.
Forskargruppen utvecklade den kontradiktoriska glömska mekanismen så att den först kunde träna det neurala nätverket att representera alla underliggande aspekter av data som det analyserar och sedan glömma specificerade fördomar. I exemplet med kreditkortsgränsen, det skulle innebära att mekanismen kan lära bankens algoritm att förutsäga gränsen samtidigt som den glömmer, eller vara oföränderlig till, de särskilda uppgifterna som hänför sig till kön eller ras. "[Mekanismen] kan användas för att träna neurala nätverk för att vara oföränderliga till kända fördomar i träningsdatauppsättningar, " sa Jaiswal. "Detta, i tur och ordning, skulle resultera i utbildade modeller som inte skulle vara partiska när man fattar beslut."
Algoritmer för djupinlärning är bra på att lära sig saker, men det är svårare att se till att algoritmerna inte lär sig vissa saker. Att utveckla algoritmer är en mycket datadriven process, och data tenderar att innehålla fördomar.
Men kan vi inte bara ta bort all information om ras, kön, och utbildning för att ta bort fördomar?
Inte helt. Det finns många andra datafaktorer som är korrelerade med dessa känsliga faktorer som är viktiga för algoritmer att analysera. Nyckeln, som ISI AI-forskarna fann, lägger till begränsningar i modellens träningsprocess för att tvinga modellen att göra förutsägelser samtidigt som den är oföränderlig för specifika datafaktorer, i huvudsak, selektiv glömma.
Kämpar mot fördomar
Invarians hänvisar till förmågan att identifiera ett specifikt objekt även om dess utseende (dvs. data) ändras på något sätt, och Jaiswal och hans kollegor började fundera på hur detta koncept skulle kunna tillämpas för att förbättra algoritmer. "Min medförfattare, Dan [Moyer], och jag kom faktiskt på den här idén lite naturligt baserat på våra tidigare erfarenheter inom området för invariant representationsinlärning, " påpekade han. Men att konkretisera konceptet var ingen enkel uppgift. "De mest utmanande delarna var [den] rigorösa jämförelsen med tidigare arbeten inom denna domän på ett brett spektrum av datauppsättningar (som krävde att köra ett mycket stort antal experiment) och [ utveckla] en teoretisk analys av glömskaprocessen, " han sa.
Den kontradiktoriska mekanismen för att glömma kan också användas för att förbättra innehållsgenereringen inom en mängd olika områden. "Det spirande området för rättvis maskininlärning tittar på sätt att minska fördomar i algoritmiskt beslutsfattande baserat på konsumentdata, ", sa Ver Steeg. "Ett mer spekulativt område involverar forskning om att använda AI för att generera innehåll inklusive försök till böcker, musik, konst, spel, och även recept. För att innehållsgenereringen ska lyckas, vi behöver nya sätt att kontrollera och manipulera representationer av neurala nätverk och glömska mekanismen kan vara ett sätt att göra det."
Så hur dyker ens fördomar upp i modellen i första hand?
De flesta modeller använder historiska data, som, tyvärr, kan till stor del vara partisk mot traditionellt marginaliserade samhällen som kvinnor, minoriteter, även vissa postnummer. Det är kostsamt och krångligt att samla in data, så forskare tenderar att ta till data som redan finns och träna modeller baserade på det, vilket är hur fördomar kommer in i bilden.
Den goda nyheten är att dessa fördomar erkänns, och även om problemet är långt ifrån löst, framsteg görs för att förstå och ta itu med dessa problem. " n forskarsamhället, människor blir definitivt allt mer medvetna om datafördomar, och designa och analysera insamlingsprotokoll för att kontrollera för kända fördomar, ", sa Jaiswal. "Studien av fördomar och rättvisa i maskininlärning har vuxit snabbt som ett forskningsfält under de senaste åren."
Bestämning av vilka faktorer som ska anses vara irrelevanta eller partiska görs av domänexperter och baseras på statistisk analys. "Än så länge, invarians har mestadels använts för att ta bort faktorer som allmänt anses oönskade/irrelevanta inom forskarvärlden baserat på statistiska bevis, " sa Jaiswal.
Dock, eftersom forskare avgör vad som är irrelevant eller partiskt, det kan finnas en potential för dessa beslut att förvandlas till fördomar i sig. Detta är en faktor som forskare också arbetar med. "Att ta reda på vilka faktorer som ska glömmas är ett kritiskt problem som lätt kan leda till oavsiktliga konsekvenser, ", noterade Ver Steeg. "En färsk artikel från Nature om rättvis lärande påpekar att vi måste förstå mekanismerna bakom diskriminering om vi hoppas kunna specificera algoritmiska lösningar korrekt."
Mänsklig informationsbehandling är extremt komplicerad, och den kontradiktoriska mekanismen för att glömma hjälper oss att komma ett steg närmare att utveckla AI som kan tänka som vi gör. Som Ver Steeg påpekade, människor tenderar att separera olika former av information om världen runt dem genom att instinktfå algoritmer att göra detsamma är utmaningen.
"Om någon kliver framför din bil, du slår till på rasterna och sloganen på deras tröja kommer inte ens in i ditt sinne, ", sa Ver Steeg. "Men om du träffade den personen i ett socialt sammanhang, den informationen kan vara relevant och hjälpa dig att få igång en konversation. För AI, olika typer av information blandas ihop. Om vi kan lära neurala nätverk att separera begrepp som är användbara för olika uppgifter, vi hoppas att det leder AI till en mer mänsklig förståelse av världen."
Mänsklig informationsbehandling är extremt komplicerad, och den kontradiktoriska mekanismen för att glömma hjälper oss att komma ett steg närmare att utveckla AI som kan tänka som vi gör. Som Ver Steeg påpekade, människor tenderar att separera olika former av information om världen omkring dem genom instinkt – att få algoritmer att göra detsamma är utmaningen.
"Om någon kliver framför din bil, du slår till på rasterna och sloganen på deras tröja kommer inte ens in i ditt sinne, ", sa Ver Steeg. "Men om du träffade den personen i ett socialt sammanhang, den informationen kan vara relevant och hjälpa dig att få igång en konversation. För AI, olika typer av information blandas ihop. Om vi kan lära neurala nätverk att separera begrepp som är användbara för olika uppgifter, vi hoppas att det leder AI till en mer mänsklig förståelse av världen."