 Medan nuvarande översättningssystem bara kan generera översatt talutmatning eller texttexter för videoinnehåll, det automatiska ansikte mot ansikte-översättningsprotokollet kan synkronisera det visuella, så att röststilen och läpprörelsen matchar målspråket. Prajwal Renukanand
Medan nuvarande översättningssystem bara kan generera översatt talutmatning eller texttexter för videoinnehåll, det automatiska ansikte mot ansikte-översättningsprotokollet kan synkronisera det visuella, så att röststilen och läpprörelsen matchar målspråket. Prajwal Renukanand Ett team av forskare i Indien har tagit fram ett system för att översätta ord till ett annat språk och få det att se ut som att en högtalares läppar rör sig i synk med det språket.
Automatisk ansikte mot ansikte översättning, enligt beskrivningen i denna artikel från oktober 2019, är ett framsteg jämfört med text-till-text eller tal-till-tal-översättning, eftersom det inte bara översätter tal, men ger också en läppsynkroniserad ansiktsbild.
För att förstå hur detta fungerar, kolla in demonstrationsvideon nedan, skapat av forskarna. Vid 6:38, du ser ett videoklipp av den avlidne prinsessan Diana i en intervju 1995 med journalisten Martin Bashir, förklarar, "Jag skulle vilja vara en drottning av människors hjärtan, i människors hjärtan, men jag ser inte mig själv som en drottning i det här landet. "
En stund senare, du kommer att se henne säga samma citat på hindi - med läpparna i rörelse, som om hon faktiskt talade det språket.
"Att kommunicera effektivt över språkbarriärer har alltid varit en viktig strävan för människor över hela världen, "Prajwal K.R. doktorand i datavetenskap vid International Institute of Information Technology i Hyderabad, Indien, förklarar via mejl. Han är huvudförfattare till tidningen, tillsammans med sin kollega Rudrabha Mukhopadhyay.
"I dag, internet är fyllt med talande ansiktsvideor:YouTube (300 timmar laddas upp per dag), föreläsningar online, videokonferenser, filmer, TV -program och så vidare, "Prajwal, som går under hans förnamn, skriver. "Nuvarande översättningssystem kan bara generera en översatt talutmatning eller texttexter för sådant videoinnehåll. De hanterar inte den visuella komponenten. Som ett resultat, det översatta talet när det överlagras på videon, läpprörelserna skulle vara synkroniserade med ljudet.
"Således, vi bygger vidare på tal-till-tal-översättningssystemen och föreslår en pipeline som kan ta en video av en person som talar på ett källspråk och mata ut en video av samma högtalare som talar på ett målspråk så att röststil och läpprörelser matchar talspråket, "Säger Prajwal." Genom att göra det, översättningssystemet blir holistiskt, och som framgår av våra mänskliga utvärderingar i detta dokument, förbättrar användarupplevelsen avsevärt när det gäller att skapa och konsumera översatt audiovisuellt innehåll. "
Översättning ansikte mot ansikte kräver ett antal komplexa bedrifter. "Med tanke på en video av en person som talar, vi har två stora informationsströmmar att översätta:den visuella och talinformationen, "förklarar han. De åstadkommer detta i flera stora steg." Systemet transkriberar först meningarna i talet med hjälp av automatisk taligenkänning (ASR). Detta är samma teknik som används för röstassistenter (Google Assistant, till exempel) i mobila enheter. "Därefter de transkriberade meningarna översätts till önskat språk med hjälp av Neural Machine Translation -modeller, och sedan konverteras översättningen till talade ord med en text-till-tal-synt-samma teknik som digitala assistenter använder.
Till sist, en teknik som heter LipGAN korrigerar läpprörelserna i originalvideon för att matcha det översatta talet.
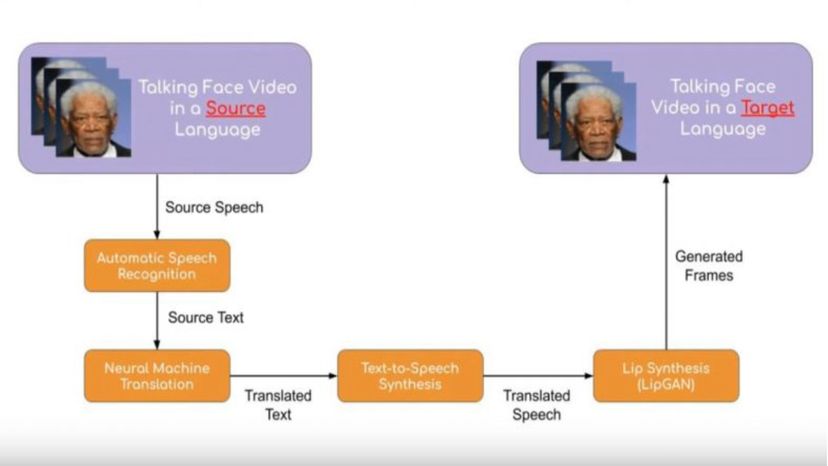 Hur tal går från initial input till synkroniserad output. Prajwal Renukanand
Hur tal går från initial input till synkroniserad output. Prajwal Renukanand "Således, vi får en helt översatt video med läppsynkronisering också, "Förklarar Prajwal.
"LipGAN är vårt nyaste nyckelbidrag. Detta är vad som för in den visuella modaliteten i bilden. Det är viktigast eftersom det korrigerar läppsynkroniseringen i den sista videon, vilket förbättrar användarupplevelsen avsevärt. "
En artikel, publicerad 24 januari 2020 i New Scientist, beskrev genombrottet som en "deepfake, "en term för videor där ansikten har bytts eller ändrats digitalt med hjälp av artificiell intelligens, ofta för att skapa ett missvisande intryck, som denna BBC -berättelse förklarade. Men Prajwal hävdar att det är en felaktig skildring av Face-to-Face Translation, som inte är avsedd att lura, utan snarare för att göra översatt tal lättare att följa.
"Vårt arbete är främst inriktat på att bredda befintliga översättningssystem för att hantera videoinnehåll, "förklarar han." Detta är en programvara som skapats med en motivation att förbättra användarupplevelsen och bryta språkbarriärer för videoinnehåll. Det öppnar upp ett mycket brett spektrum av applikationer och förbättrar tillgängligheten för miljontals videor online. "
Den största utmaningen när det gäller att göra översättning till ansikte mot ansikte var ansiktsgenereringsmodulen. "Nuvarande metoder för att skapa läppsynkroniseringsvideor kunde inte generera ansikten med önskade poser, gör det svårt att klistra in det genererade ansiktet i målvideon, "Prajwal säger." Vi införlivade en "pose prior" som en ingång till vår LipGAN -modell, och som resultat, vi kan generera ett exakt läppsynkroniserat ansikte i önskad målställning som kan smidigt blandas in i målvideon. "
Forskarna ser för sig att ansikte mot ansikte-översättning används för att översätta filmer och videosamtal mellan två personer som var och en talar ett annat språk. "Att få digitala karaktärer i animerade filmer att sjunga/tala visas också i vår video, "Prajwal anteckningar.
Dessutom, han förutser att systemet används för att hjälpa studenter över hela världen att förstå föreläsningsvideor online på andra språk. "Miljontals främmande språkstudenter över hela världen kan inte förstå utmärkt utbildningsinnehåll tillgängligt online, eftersom de är på engelska, " han förklarar.
"Ytterligare, i ett land som Indien med 22 officiella språk, vårt system kan, i framtiden, översätta TV-nyhetsinnehåll till olika lokala språk med exakt läppsynkronisering av nyhetsankarna. Listan över applikationer gäller således för alla typer av videoinnehåll som talar ansikte, som måste göras mer tillgängligt på olika språk. "
Även om Prajwal och hans kollegor tänker att deras genombrott ska användas på positiva sätt, förmågan att lägga främmande ord i en talares mun berör en framstående amerikansk cybersäkerhetsexpert, som fruktar att ändrade videor kommer att bli allt svårare att upptäcka.
"Om du tittar på videon, du kan se om du tittar noga, munnen har en viss suddighet, "säger Anne Toomey McKenna, en framstående forskare i cyberlag och politik vid Penn State Universitys Dickinson Law, och professor vid universitetets Institute for Computational and Data Sciences, i en e -postintervju. "Det kommer att fortsätta att minimeras när algoritmerna fortsätter att förbättras. Det kommer att bli mindre och mindre urskiljbart för det mänskliga ögat."
McKenna till exempel, föreställer sig hur en förändrad video av MSNBC -kommentatorn Rachel Maddow kan användas för att påverka val i andra länder, genom att "vidarebefordra information som är felaktig och motsatsen till vad hon sa."
Prajwal oroar sig också för eventuellt missbruk av ändrade videor men tror att försiktighetsåtgärder kan utvecklas för att skydda mot sådana scenarier, och att den positiva potentialen för ökad internationell förståelse uppväger riskerna med automatisk ansikte mot ansikte översättning. (På den fördelaktiga sidan, detta blogginlägg föreställer att Greta Thunbergs tal skulle översättas vid FN:s klimatmöte i september 2019 till en mängd olika språk som används i Indien.)
"Varje kraftfull teknik kan användas för massor av bra, och har också dåliga effekter, "Prajwal -anteckningar." Vårt arbete är, faktiskt, ett översättningssystem som kan hantera videoinnehåll. Innehåll översatt av en algoritm är definitivt inte riktigt, 'men detta översatta innehåll är viktigt för människor som inte förstår ett visst språk. Ytterligare, i nuvarande skede, sådant automatiskt översatt innehåll är lätt att känna igen av algoritmer och tittare. Samtidigt, aktiv forskning bedrivs för att känna igen sådant förändrat innehåll. Vi tror att den gemensamma ansträngningen för ansvarsfull användning, strikta regler, och forskningens framsteg när det gäller att upptäcka missbruk kan säkerställa en positiv framtid för denna teknik. "
Nu är det filmisktEnligt Language Insight, en studie av brittiska forskare fastställde att en filmbesökares preferens för dubbade kontra textade utländska filmer påverkar den typ av film som de drar till. De som gillar vanliga blockbusters är mer benägna att se en dubbad version av en film, medan de som föredrar undertexter är mer benägna att vara fans av arthouse -import.














