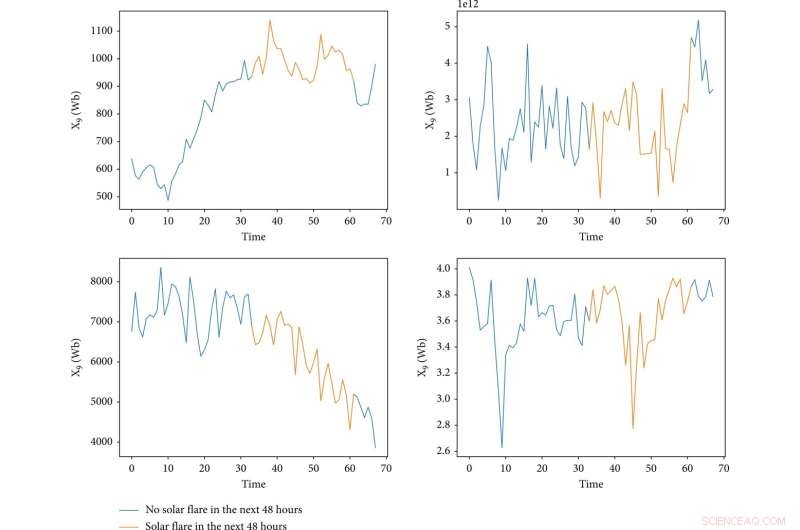
Visualiseringen av fyra funktioner under existensen av en aktiv region. X-axeln representerar tid och dess enhet är ett sampel, där "0" representerar starttiden för en aktiv region, och tidsgapet mellan närliggande tider är 1,5 h. Y-axeln representerar värdet på en egenskap. De blå linjerna indikerar att det inte finns något solsken under de kommande 48 timmarna, och de gula linjerna är motsatsen. Kredit:Rymden:vetenskap och teknik
Solflammor är solstormar som drivs av magnetfält i solaktivitetsområdet. När denna flarestrålning kommer till jordens närhet ökar fotojoniseringen elektrontätheten i jonosfärens D-lager, vilket orsakar absorption av högfrekvent radiokommunikation, scintillation av satellitkommunikation och förstärkt bakgrundsbrusinterferens med radar.
Statistik och erfarenhet visar att ju större blossen är, desto mer sannolikt är det att det åtföljs av andra solutbrott, såsom en solprotonhändelse, och desto allvarligare blir effekterna på jorden, vilket påverkar rymdfärd, kommunikation, navigering, kraftöverföring och andra tekniska system.
Att tillhandahålla prognosinformation om sannolikheten och intensiteten av utbrott av utbrott är ett viktigt inslag i början av operativa väderprognoser för rymden. Modelleringsstudien av prognostisering av solfläckar är en nödvändig del av noggrann flareprognoser och har ett viktigt tillämpningsvärde. I en forskningsartikel som nyligen publicerades i Space:Science &Technology , Hong Chen från College of Science, Huazhong Agricultural University, kombinerade k-means klustringsalgoritmen och flera CNN-modeller för att bygga ett varningssystem som kan förutsäga om ett solfloss skulle inträffa under de närmaste 48 timmarna.
Först introducerade författaren de data som används i uppsatsen och analyserade dem ur statistisk synvinkel för att ge en grund för utformningen av varningssystemet för solutbrott. För att minska projektionseffekten valdes mitten av det aktiva området beläget inom ±30° från solskivans centrum. Efter det märkte författaren uppgifterna enligt de solflossdata som tillhandahålls av NOAA, inklusive start- och sluttiderna för blossarna, numret på den aktiva regionen, blossarnas storlek, etc.
Det fanns en allvarlig obalans mellan antalet positiva och negativa prover i datasetet. För att lindra obalansen mellan positiva och negativa prover fann man en princip att välja de händelser som har positiva prover så mycket som möjligt. Författaren visualiserade sannolikhetstäthetsfördelningen för varje funktion i alla negativa prover och alla positiva prover. Det kunde lätt konstateras att sannolikhetstäthetsfördelningarna för de negativa proverna alla var negativt skeva fördelningar och egenskaperna hos positiva prover var generellt sett större än för negativa prover. Således var det möjligt att filtrera bort händelser med positiva prover efter funktionsvärdena för varje händelse.
Efteråt byggde författaren hela pipelinen med en metod som innehöll följande två steg:dataförbearbetning och modellträning. För att utföra dataförbearbetning användes K-means, en oövervakad klustringsmetod, för att klustra händelser för att minska händelser som bara inkluderar negativa prover så mycket som möjligt.
Efter k-means klustring delades alla händelser in i tre kategorier, nämligen kategori A, kategori B och kategori C. Författaren fann att förhållandet mellan positiva prover i kategori C är 0,340633, vilket är mycket större än hela datamängden. Därför valdes endast data i kategori C som indata i nästa steg av algoritmen.
I det andra steget var de neurala nätverk som författaren använde Resnet18, Resnet34 och Xception, som vanligtvis används vid djupinlärning. Tre fjärdedelar av proverna i kategori C valdes ut slumpmässigt. I varje händelse var träningsdata för de neurala nätverksmodellerna och resten av proverna betraktades som valideringsdata under träningsmodellen.
För att undvika påverkan av dimension standardiserade författaren också originaldata. Standardiseringsmetoden skilde sig från de som vanligtvis användes. Enligt standardiseringsberäkningsformeln, om etiketten för ett prov förutspåddes att vara 1 av det neurala nätverket, betraktades detta prov som en signal om solflamma som skulle inträffa under de kommande 48 timmarna. Men om det förutspås vara 0, skulle sannolikheten för att solflamma inträffar under de kommande 48 timmarna vara så liten att den skulle kunna ignoreras.
Sedan genomförde författaren experiment och diskuterade resultaten. Författaren gav först en introduktion av experimentell miljö och genomförde sedan flera ablationsexperiment och jämförelser med olika modeller för att verifiera förbättringen av k-means klustringsalgoritm och booststrategi. Dessutom gjorde författaren också jämförelser mellan metoden som användes i experimentet och andra 13 binära klassificeringsalgoritmer som vanligtvis används för att presentera dess förutsägelseprestanda.
De experimentella resultaten visade att prediktionsprestandan för modellen som integrerade flera neurala nätverk var bättre än den för ett enda faltningsneurala nätverk. Slutligen kombinerades förutsägelseresultaten av Resnet18, Resnet34 och Xception genom att öka strategin. För alla nätverk kan återkallelsen vara oförändrad eller till och med minska kraftigt efter klustring. Precisionen måste dock öka avsevärt.
Efter klustring, även om den positiva provfrekvensen skulle förbättras avsevärt, från 5 % till 34 %, skulle nästan 40 % av informationen från positiva prover också gå förlorad. Författaren trodde att detta var huvudorsaken till att återkallelsen förblev oförändrad eller till och med minskade. It also meant that the number of positive samples predicted in the experiment was less than the one without clustering, but the probability that a predicted positive sample was a true positive was higher.
In contrast with the phenomenon that the prediction performance of other binary classification methods was decreasing or even very poor after clustering, the performance of the author's method improved by more than 9% after clustering. In conclusion, the two-stage solar flare early warning system consisted of an unsupervised clustering algorithm (k-means) and several CNN models, where the former was to increase the positive sample rate, and the latter integrated the prediction results of the CNN models to improve the prediction performance.
The results of the experiment proved the effectiveness of the method. + Utforska vidare