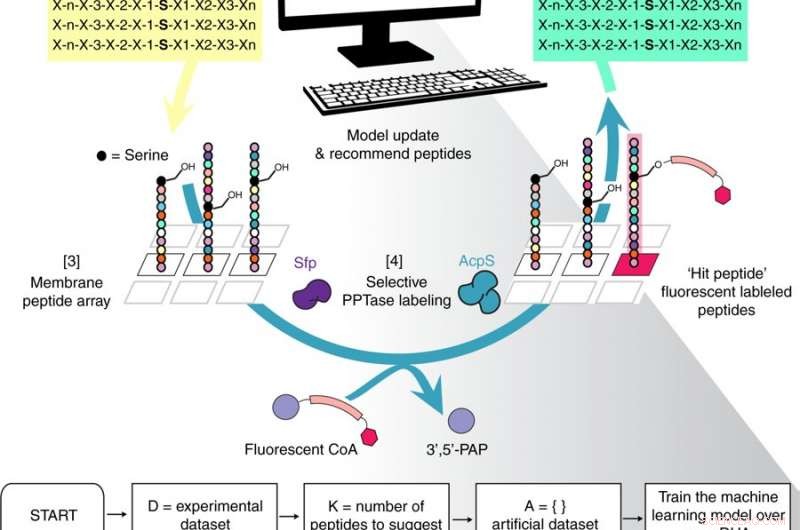
Översikt över det iterativa arbetsflödet för peptidoptimering med Optimal Learning (POOL). Kreditera: Naturkommunikation (2018). DOI:10.1038/s41467-018-07717-6
Forskare och ingenjörer har länge varit intresserade av att syntetisera peptider - kedjor av aminosyror som är ansvariga för att utföra många funktioner i celler - för att både efterlikna naturen och för att utföra nya aktiviteter. En designad peptid, till exempel, kan vara ett funktionellt läkemedel som verkar i vissa områden i kroppen utan att försämras, en svår uppgift för många peptider.
Men metoder för att upptäcka och syntetisera peptider är dyra och tidskrävande, ofta med månader eller år av gissningar och misslyckanden.
Northwestern University forskare, samarbetar med medarbetare vid Cornell University och University of California, San Diego, har utvecklat ett nytt sätt att hitta optimala peptidsekvenser:att använda en maskininlärningsalgoritm som samarbetspartner.
Algoritmen analyserar experimentella data och ger förslag på den näst bästa sekvensen att prova, skapa en fram och tillbaka urvalsprocess som drastiskt minskar tiden som behövs för att hitta den optimala peptiden.
Resultaten, som skulle kunna ge ett nytt ramverk för experiment inom materialvetenskap och kemi, publicerades i Naturkommunikation den 7 december.
"Vi ser detta som nästa våg i hur vi designar molekyler och material, " sa Northwestern professor Nathan Gianneschi, motsvarande författare på tidningen. "Vi kan kombinera det vi vet från intuitionen med kraften i en algoritm och hitta lösningen med färre experiment."
Gianneschi är professor för Jacob och Rosaline Cohn vid avdelningen för kemi vid Northwesterns Weinberg College of Arts and Sciences och vid avdelningarna för materialvetenskap och ingenjörsvetenskap och för biomedicinsk teknik vid Northwestern Engineering.
För att skapa metoden, Gianneschi, som också är biträdande direktör för Northwesterns International Institute for Nanotechnology, slog sig ihop med Peter Frazier, en docent vid Cornell som arbetar med operationsforskning och maskininlärning, och Michael Burkart, en kemisk biolog och expert på enzymologi vid UC San Diego, att hitta ett bättre sätt att göra peptider som kan generera biomaterial – specifikt nanostrukturer och mikrostrukturer som kan modifiera proteiner på vissa sätt. Det första steget var att hitta rätt peptider som skulle fungera som enzymatiska substrat för dessa strukturer.
Peptider är byggda av kedjor av aminosyror som kan vara så många som 20 aminosyror långa, med 20 olika möjligheter för varje syra. Eftersom sekvensen bestämmer peptidfunktionen, att räkna ut optimala sekvenser kräver dyra experiment som ofta utförs med gissningar.
Experimentalisterna, Gianneschi och Burkart, arbetat med Frazier under flera år för att utveckla ett system som kombinerade experimentell data med en maskininlärningsalgoritm för att hitta de bästa strategierna för att skapa nya material.
Efter att Frazier designade algoritmen och de två arbetade tillsammans för att träna den, experimentalisterna utvecklade en uppsättning av 100 peptider, genomförde experiment för att ta reda på vilka som fungerade som de var tänkta att, matade sedan in den informationen i algoritmen. Algoritmen rekommenderade sedan vad som skulle ändras för nästa omgång av peptidutveckling, och rekommenderade också strategier som den trodde skulle misslyckas.
"Nu började vi bli selektiva, ", sa Gianneschi. Genom att slutföra denna process flera gånger, de kunde hitta optimala peptider.
"Istället för att gissa och titta på miljontals peptider, vi kunde titta på hundratals peptider och mycket snabbt konvergera på sekvenser som betedde sig på helt nya sätt, " sa han. Jämfört med slumpmässiga mutationer eller gissningar, Algoritmmetoden var statistiskt mycket mer framgångsrik.
Även om detta arbete fokuserade på substrat, denna process kan användas för att upptäcka peptider för alla slags ändamål, som läkemedelstillförsel, och kanske till och med användas för att upptäcka DNA-sekvenser, också. Eftersom vilken typ av optimal sekvens som helst kunde upptäckas, forskare är inte heller begränsade till vilka aminosyrasekvenser som finns i den genetiska koden.
Nästa steg är att automatisera hela processen. Gianneschi är också intresserad av att använda metoden för att hitta optimala ytor för polymerer, specifikt polymerer som används i medicinska implantat. Att hitta rätt ytor som binder till vävnad eller muskler kan hjälpa till att förhindra ärrvävnad eller avstötning av implantat.
"Du kan i princip upptäcka sekvenser som gör specifika saker, som verkligen är kärnan i vad peptider och nukleinsyror gör i naturen, ", sa han. "Detta kan revolutionera hur vi gör peptider."