Ett exempel från MovieGraphs -datamängden, scen från filmen Forrest Gump. Kredit:University of Toronto
Om din vän är ledsen, du kan säga något för att pigga upp dem. Om du ber din arbetskamrat att göra kaffe, de känner till stegen för att slutföra denna uppgift.
Men hur gör artificiellt intelligenta robotar, eller AI:er, lära sig att bete sig på samma sätt som människor gör?
Forskare från University of Toronto presenterar nya metoder för socialt intelligenta AI:er, vid konferensen Computer Vision and Pattern Recognition (CVPR), den främsta årliga datorvisionshändelsen den här veckan i Salt Lake City, Utah.
Hur tränar vi en robot hur man beter sig?
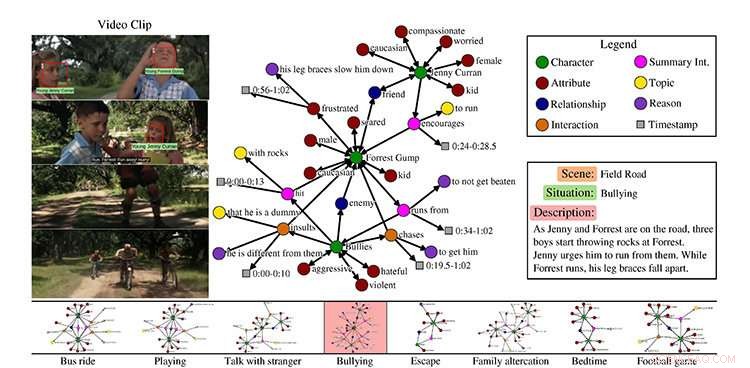
MovieGraphs:Towards Understanding Human-Centric Situations from Videos, Paul Vicol, en doktorsexamen student i datavetenskap, Makarand Tapaswi, en postdoktoral forskare, Lluis Castrejón, en magisterexamen från U of T datavetenskap som nu är doktorand. student vid University of Montreal Institute for Learning Algorithms, och Sanja Fidler, en biträdande professor vid U vid T Mississaugas institution för matematiska och beräknade vetenskaper och tri-campus doktorsexamen vid datavetenskap, har samlat en datamängd med kommenterade videoklipp från mer än 50 filmer.
"MovieGraphs är ett steg mot nästa generation av kognitiva agenter som kan resonera om hur människor känner och om motivationen för deras beteenden, "säger Vicol." Vårt mål är att göra det möjligt för maskiner att uppträda korrekt i sociala situationer. Våra grafer fångar många högnivåegenskaper hos mänskliga situationer som inte har undersökts i tidigare arbete. "
Deras dataset fokuserar på filmer i dramat, romantik, och komedigenrer, som Forrest Gump och Titanic, och följer tecken över tiden. De inkluderar inte superhjältefilmer som Thor eftersom de inte är särskilt representativa för den mänskliga upplevelsen.
"Tanken var att använda filmer som en proxy för den verkliga världen, säger Vicol.
Varje klipp, han säger, är associerad med en graf som fångar detaljerade detaljer om vad som händer i klippet:vilka tecken som finns, deras relationer, interaktioner mellan varandra tillsammans med orsakerna till varför de interagerar, och deras känslor.
Vicol förklarar att datamängden visar, till exempel, inte bara att två människor argumenterar, men vad de bråkar om, och anledningarna till att de bråkar, som kommer från både visuella signaler och dialog. Teamet skapade sitt eget verktyg för att möjliggöra annotering, som gjordes av en enda annotator för varje film.
"Alla klipp i en film kommenteras i följd, och hela grafen som är associerad med varje klipp skapas av en person, vilket ger oss en sammanhängande struktur i varje graf, och mellan grafer över tid, " han säger.
Med sin dataset på mer än 7, 500 klipp, forskarna introducerar tre uppgifter, förklarar Vicol. Den första är videohämtning, baserat på det faktum att graferna är grundade i videorna.
"Så om du söker med en graf som säger att Forrest Gump argumenterar med någon annan, och att karaktärernas känslor är ledsna och arga, då kan du hitta klippet, " han säger.
Det andra är interaktionsbeställning, som avser att bestämma den mest troliga ordningen av teckeninteraktioner. Till exempel, han förklarar om en karaktär skulle ge en annan karaktär en present, personen som fick gåvan skulle säga "tack".
"Du brukar inte säga" tack, 'och sedan ta emot en present. Det är ett sätt att jämföra huruvida vi fångar interaktionens semantik. "
Deras sista uppgift är resonemang förutsägelse baserat på det sociala sammanhanget.
"Om vi fokuserar på en interaktion, kan vi bestämma motivationen bakom den interaktionen och varför den inträffade? Så det är i grunden att försöka förutsäga när någon skriker åt någon annan, själva frasen som skulle förklara varför, " han säger
Tapaswi säger att slutmålet är att lära sig beteende.
"Tänk dig till exempel i ett klipp, maskinen förkroppsligar i princip Jenny [från filmen Forrest Gump]. Vad är en lämplig åtgärd för Jenny? I en scen, det är att uppmuntra Forrest att springa undan mobbare. Så vi försöker få maskiner att lära sig lämpligt beteende. "
"Lämplig i den bemärkelsen att filmer tillåter, självklart."

Skärmdump:MIT CSAIL/VirtualHome:Simulera hushållsaktiviteter via program
Hur lär sig en robot hushållsuppgifter?
Under ledning av Massachusetts Institute of Technology Assistant Professor Antonio Torralba och U i T's Fidler, VirtualHome:Simulera hushållsaktiviteter via program, utbildar en virtuell mänsklig agent med naturligt språk och ett virtuellt hem, så att roboten kan lära sig inte bara genom språk, men genom att se, förklarar U från T masterstudent i datavetenskap Jiaman Li, en bidragande författare med U av T Ph.D. student i datavetenskap Wilson Tingwu Wang.
Li förklarar att åtgärden på hög nivå kan vara "arbete på datorn" och beskrivningen inkluderar:att slå på datorn, sitter framför den, skriva på tangentbordet och ta tag i musen för att rulla.
"Så om vi berättar för en människa denna beskrivning, 'arbeta med dator, 'människan kan utföra dessa handlingar precis som beskrivningarna. Men om vi bara säger till roboten denna beskrivning, hur gör de exakt det? Roboten har inte detta sunt förnuft. Det behöver mycket tydliga steg, eller program. "
Eftersom det inte finns någon datauppsättning som innehåller all denna kunskap, hon säger att forskarna byggde ett med ett webbgränssnitt för att samla programmen, som tillhandahåller åtgärdsnamnet och beskrivningen.
"Sedan byggde vi en simulator så att vi har en virtuell människa i ett virtuellt hem som kan utföra dessa uppgifter, " hon säger.
För hennes del i det pågående projektet, Li använder djupinlärning - en gren av maskininlärning som utbildar datorer att lära sig - för att automatiskt generera program från text eller video för dessa program.
Dock, det är ingen lätt uppgift att utföra varje åtgärd i simulatorn, säger Li, eftersom datamängden resulterade i mer än 5, 000 program.
"Att simulera allt man gör i ett hem är extremt svårt, och vi tar ett steg mot detta genom att genomföra de vanligaste atomaktionerna som promenader, sitta, och hämta, säger Fidler.
"Vi hoppas att vår simulator kommer att användas för att träna robotar komplexa uppgifter i en virtuell miljö, innan vi går vidare till den verkliga världen. "
MovieGraphs stöddes delvis av Natural Science and Engineering Research Council of Canada (NSERC) och VirtualHome stöds delvis av NSERC COmputing Hardware for Emerging Intelligent Sensing Applications (COHESA) Network.














