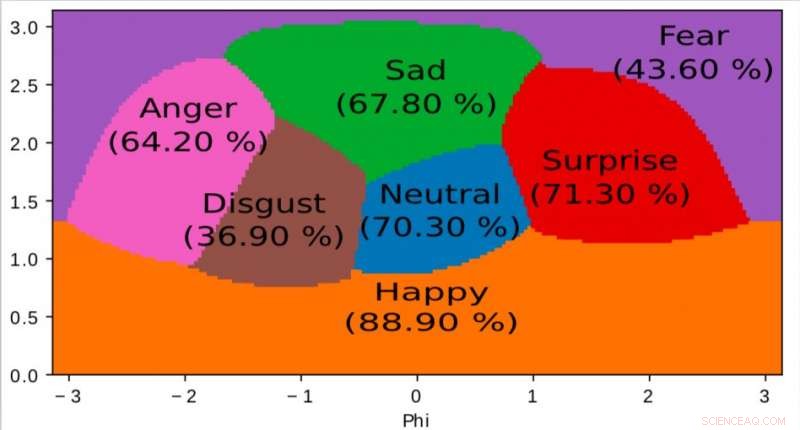
En representation av det inre rummet som vår algoritm lärt sig och som används för att kartlägga känslor till ett kontinuerligt 2D-rum. Det är intressant att notera att även om träningsdata endast innehåller diskreta känsloetiketter, nätverket lär sig ett kontinuerligt utrymme, tillåter inte bara att fint beskriva människors känslomässiga tillstånd utan också att positionera känslor i förhållande till varandra. Detta utrymme har stark likhet med det upphetsningsvalensutrymme som definieras av modern psykologi. Kredit:Jurie et al.
Forskare vid Orange Labs och Normandie University har utvecklat en ny djup neural modell för audiovisuellt känslomässig igenkänning som fungerar bra med små träningsuppsättningar. Deras studie, som förpublicerades den arXiv , följer en filosofi om enkelhet, avsevärt begränsa parametrarna som modellen hämtar från datauppsättningar och använda enkla inlärningstekniker.
Neurala nätverk för emotionsigenkänning har ett antal användbara tillämpningar inom hälso- och sjukvårdssammanhang, kundanalys, övervakning, och till och med animation. Medan toppmoderna algoritmer för djupinlärning har uppnått anmärkningsvärda resultat, de flesta kan fortfarande inte nå samma förståelse av känslor som människor uppnår.
"Vårt övergripande mål är att underlätta interaktion mellan människa och dator genom att göra datorer i stånd att uppfatta olika subtila detaljer uttryckta av människor, "Frédéric Jurie, en av forskarna som genomförde studien, berättade för TechXplore. "Att uppfatta känslor som finns i bilder, video, röst och ljud faller inom detta sammanhang."
Nyligen, studier har satt ihop multimodala och temporala datauppsättningar som innehåller kommenterade videor och audiovisuella klipp. Ändå innehåller dessa datauppsättningar vanligtvis ett relativt litet antal kommenterade prov, samtidigt som man presterar bra, de flesta befintliga djupinlärningsalgoritmer kräver större datamängder.
Forskarna försökte ta itu med denna fråga genom att utveckla ett nytt ramverk för audiovisuellt känslomässig igenkänning, som smälter samman analysen av bild- och ljudmaterial, bibehåller en hög noggrannhetsnivå även med relativt små träningsdatauppsättningar. De tränade sin neurala modell på AFEW, en datauppsättning med 773 audiovisuella klipp extraherade från filmer och kommenterade med diskreta känslor.

Illustration av hur detta 2D-utrymme kan användas för att kontrollera känslor som uttrycks av ansikten, på ett kontinuerligt sätt, med hjälp av adversarial generative networks (GAN). Kredit:Jurie et al.
"Man kan se den här modellen som en svart låda som bearbetar videon och automatiskt härleder människors känslomässiga tillstånd, " Jurie förklarade. "En stor fördel med sådana djupa neurala modeller är att de själva lär sig hur man bearbetar videon genom att analysera exempel, och kräver inte att experter tillhandahåller specifika bearbetningsenheter."
Modellen som utarbetats av forskarna följer Occams rakhyvelfilosofiska princip, vilket antyder att mellan två tillvägagångssätt eller förklaringar, det enklaste är det bästa valet. I motsats till andra modeller för djupinlärning för emotionsigenkänning, därför, deras modell hålls relativt enkel. Det neurala nätverket lär sig ett begränsat antal parametrar från datamängden och använder grundläggande inlärningsstrategier.
"Det föreslagna nätverket består av kaskadbearbetningslager som abstraherar informationen, från signalen till dess tolkning, " Sa Jurie. "Ljud och video bearbetas av två olika kanaler i nätverket och kombineras på senare tid i processen, nästan på slutet."
När den testades, deras ljusmodell uppnådde en lovande känsla igenkänningsnoggrannhet på 60,64 procent. Den rankades också på fjärde plats vid 2018 års utmaning för Emotion Recognition in the Wild (EmotiW), hölls vid ACM International Conference on Multimodal Interaction (ICMI), i Colorado.

Illustration av hur detta 2D-utrymme kan användas för att kontrollera känslor som uttrycks av ansikten, på ett kontinuerligt sätt, med hjälp av adversarial generative networks (GAN). Kredit:Jurie et al.
"Vår modell är ett bevis på att vi följer Occams rakknivprincip, dvs. genom att alltid välja de enklaste alternativen för att designa neurala nätverk, det är möjligt att begränsa storleken på modellerna och få mycket kompakta men toppmoderna neurala nätverk, som är lättare att träna, ", sa Jurie. "Detta står i kontrast till forskningstrenden att göra neurala nätverk större och större."
Forskarna kommer nu att fortsätta att utforska sätt att uppnå hög noggrannhet i emotionsigenkänning genom att samtidigt analysera visuella och auditiva data, använda de begränsade kommenterade utbildningsdatauppsättningarna som för närvarande är tillgängliga.
"Vi är intresserade av flera forskningsriktningar, till exempel hur man bättre kan sammanföra de olika modaliteterna, hur man representerar känslor med kompakta semantiskt betydelsefulla fullständiga deskriptorer (och inte bara klassetiketter) eller hur man får våra algoritmer att kunna lära sig med mindre, eller till och med utan, kommenterade data, sa Jurie.
© 2018 Tech Xplore