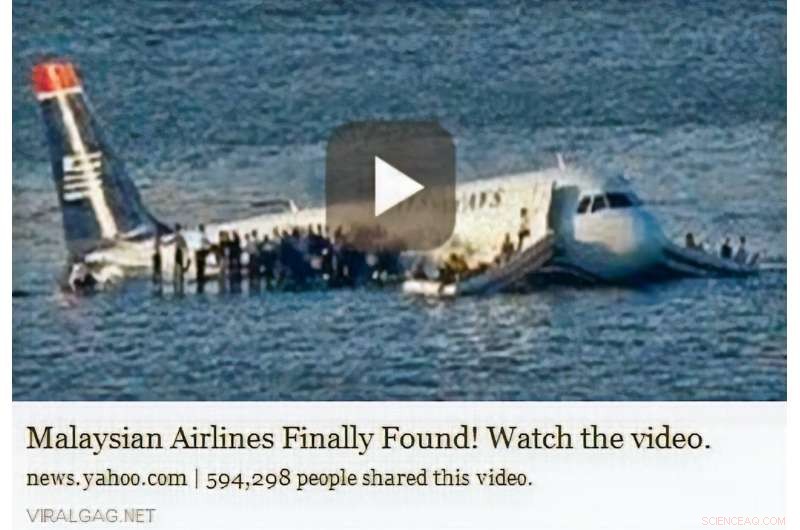
En video av US Airways Flight 1549 lånades av nyheter på Malaysia Airlines Flight 370. Kredit:Wen, Su &Yu.
Forskare vid UC Davis har nyligen utvecklat ett nytt maskininlärningsbaserat verktyg för att verifiera multimediarykten online. Deras papper, förpublicerad på arXiv, föreslår gränsöverskridande och plattformsoberoende funktioner för ryktesverifiering, som utnyttjar den semantiska likheten mellan rykten och information på andra webbplatser. Deras metod kan kombinera information från flera språk för att få en komplett bild av onlinenyheter.
Ett växande antal människor världen över använder nu enheter för att läsa nyheterna och lära sig om vad som händer i världen. Dock, sociala medieplattformar är till stor del omodererade, resulterar i spridningen av falska nyheter, som ofta åtföljs av tillverkat eller avkontextualiserat multimediainnehåll. Falska rykten kan spridas väldigt snabbt på nätet, orsakar förödelse och förvirring bland läsarna, så utvecklingen av verktyg för att verifiera äktheten av onlineinformation är av yttersta vikt.
"Vår forskning är inspirerad av den ökande populariteten för falska nyheter kopplade till multimediainnehåll i sociala nätverk, "Weiming Wen, en av de utexaminerade forskarna som genomförde studien, berättade för Tech Xplore. "Det handlar främst om hur man använder NLP-tekniker för att verifiera rykten med multimediainnehåll. Grundidén är att lösa problemet genom maskininlärning — extrahera specifika egenskaper från den här typen av rykten och bygga en modell för att klassificera rykten som falska eller verkliga."
Tidigare ryktesverifieringsforskning använde multimediainnehåll som indatafunktioner, utnyttja kriminaltekniska egenskaper hos bilder eller videor för att avgöra om de har manipulerats. Även om dessa bilder har förbättrade resultat, de flesta av dessa studier kunde inte effektivt använda multimediainnehåll för att konsekvent verifiera rykten på Twitter.
En möjlig orsak till detta är att ofta, multimediainnehåll kopplat till falska nyheter är bara lånat från autentiska händelser och är något semantiskt anpassat till texten som åtföljer det. Detta betyder att själva bilden är verklig, men placeras i en helt annan historia för att göra det falska ryktet mer trovärdigt.
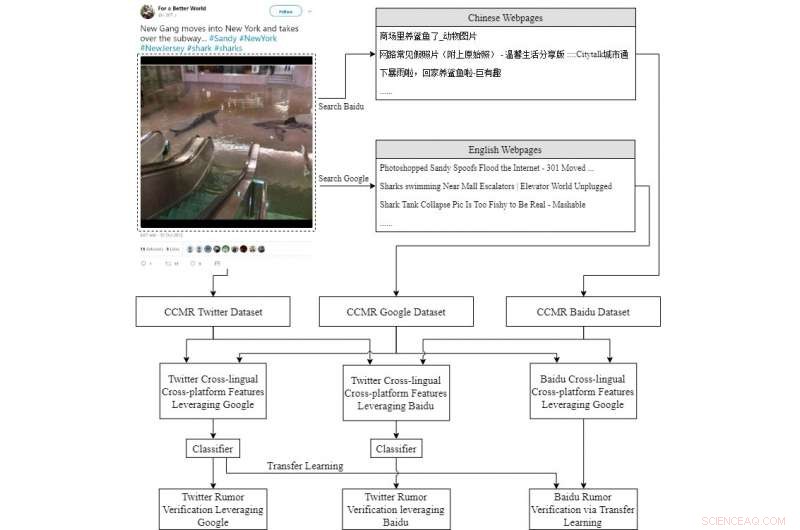
Informationsflödet i vår föreslagna pipeline. TFG representerar de tvärspråkiga plattformsoberoende funktionerna för tweets som utnyttjar Googles information, medan TFB är liknande men utnyttjar Baidu-information istället. BFG betyder tvärspråkiga plattformsoberoende funktioner för Baidu som utnyttjar Googles information. Kredit:Wen, Su &Yu.
Forskarna vid UC Davis föreslog ett alternativt sätt att verifiera rykten som utnyttjar multimediainnehåll genom att hitta information associerad med det på andra nyhetsplattformar.
De flesta befintliga ryktesverifieringsdatauppsättningar är enspråkiga, till exempel, inkluderar endast multimediainnehåll presenterat med engelsk eller kinesisk text. Forskarna skapade en ny tvärspråkig, plattformsöverskridande ryktesverifieringsdataset (CCMR), som består av tre deldataset:CCMR Twitter, CCMR Google och CCMR Baidu.
"När vi säger multimediarykten, vi menar tweets eller annat innehåll på sociala medier som inte är verifierat och har bilder eller videor tillsammans med texten, "Zhou Yu, biträdande professor vid UC Davis, vem som genomförde studien, berättade för Tech Xplore. "Text och bild anses vara två olika informationskanaler. Vi utnyttjar visionsinformation på ett innovativt sätt, använder det som en pivot för att länka nyheter från olika plattformar och på olika språk."
Funktionerna som utvecklats av forskarna bäddar in både ryktet och de tillhörande titlarna på olika webbsidor i 300-dimensionella vektorer med en förtränad flerspråkig meningsinbäddning. De tränade sin flerspråkiga meningsinbäddningsalgoritm på 453, 000 par engelska och kinesiska parallella nyheter, samt mikrobloggar i UM-Corpus dataset. Denna algoritm kan kombinera nyheter från flera språk, uppnå en effektivare rykteverifiering.
"Med tanke på ett rykte bifogat med en bild, vi söker först bilden via Google Image för att få en massa relaterade inlägg, ", förklarade Wen. "Vi extraherar sedan drag av detta rykte genom att beräkna likheten och överensstämmelsen mellan ryktet och de sökta inläggen. Till sist, vi använder vår förtränade modell för att verifiera detta rykte med hjälp av dess funktioner."

Exempel på parallella rykten i evenemanget Pig Fish. Kredit:Wen, Su &Yu. Kredit:Wen, Su &Yu.
När den testades, Maskininlärningsmetoder som använde de gränsöverskridande och plattformsoberoende funktionerna som föreslagits av forskarna uppnådde toppmoderna ryktesverifieringsresultat. Dessa funktioner visade sig också vara kompakta och generaliserbara över språk.
"Jag tror att den mest meningsfulla delen av vår studie är att vi utvecklade ett ramverk för ryktesverifiering som fungerar specifikt för multimediarykten, vilket är extremt vanligt, men har inte studerats noggrant, " sade Wen. "Med detta ramverk, vi kan effektivt verifiera multimediarykten från plattformar som Facebook och Twitter."
Denna studie kan vara en viktig milstolpe på vägen mot att utveckla effektiva sätt att validera online-rykten som åtföljs av multimediainnehåll. Dessutom, den engelsk-kinesiska datamängden som sammanställts av forskarna skulle kunna användas i ytterligare forskning för att utforska metoder för tvärlingual rykteverifiering.
"I framtiden, vi planerar att skapa skäl för våra verifieringsresultat om multimediarykten, ", sa Wen. "Förutom att klassificera ett rykte som falskt, vi vill också automatiskt generera en anledning, som "det här inlägget är falskt eftersom det lånar en bild från en annan händelse för att bevisa sitt uttalande, " sa Wen.
© 2018 Tech Xplore














