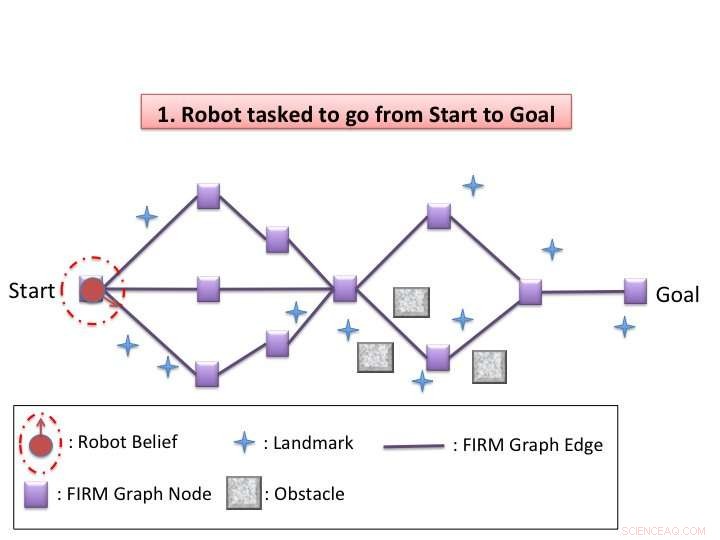
Algoritm illustration. Kredit:Agha-mohammadi et al.
Forskare vid NASA Jet Propulsion Laboratory (JPL), Texas A&M University, och Carnegie Mellon University genomförde nyligen ett forskningsprojekt som syftar till att möjliggöra simultan lokalisering och planering (SLAP) i autonoma robotar. Deras papper, publiceras i IEEE-transaktioner på robotik , presenterar ett dynamiskt omplaneringsschema i trosrum, vilket kan vara särskilt användbart för robotar som arbetar under osäkerhet, som i föränderliga miljöer.
"Robotar som verkar i den verkliga världen måste hantera osäkerhet, "Sung Kyun Kim, en av forskarna som genomförde studien berättade för TechXplore. "Till exempel, en Mars-rover ska navigera till vetenskapliga målplatser, men det måste också undvika kollision med hinder. Således, både exakt lokalisering och kostnadseffektiv vägplanering är viktiga funktioner."
SLAP är en nyckelförmåga för autonoma robotar som arbetar under osäkerhet, gör det möjligt för dem att effektivt navigera i utrymmen, undvika hinder, och planera sin väg till målplatser. En robots sekventiella beslutsprocess under osäkerhet kan formuleras som en POMDP (partially observable Markov decision process), som kontinuerligt behöver lösas online. Dock, Att säkerställa att robotar effektivt och exakt löser POMDP:er kan vara avsevärt utmanande.
"Vi kom på två huvudidéer för att lösa SLAP-problem, " Kim förklarade. "En är att använda återkopplingskontroller för att göra en trostillstånd nåbar. Detta kan effektivt bryta historiens förbannelse, som hjälper oss att lösa större problem. Den andra är att dynamiskt planera om och förbättra beslutet under körning, förbättra lösningens kvalitet och robusthet. Dynamisk omplanering är särskilt fördelaktigt när det finns systemmodelleringsfel, dynamiska miljöförändringar, eller intermittent fel på sensor/ställdon."

Mars rover exempel. Kredit:NASA/JPL-Caltech.
Kim och hans kollegor utarbetade ett dynamiskt omplaneringsschema i trosrymden som tillåter robotar att effektivt navigera i utrymmet runt dem i situationer av osäkerhet, som i föränderliga miljöer eller när de ställs inför oväntade hinder. Deras algoritm har två faser, offline och online.
"I offlinefasen, vår algoritm konstruerar en gles graf i trosutrymmet med en återkopplingskontroller för varje nod och löser sedan den grova globala policyn (bestämma vilken åtgärd som ska vidtas vid det aktuella övertygelsestillståndet) på grafen, " sa Kim. "I onlinefasen, dynamisk omplanering genomförs varje gång trostillståndet uppdateras. Algoritmen utvärderar lokalt varje åtgärd för att flytta till en närliggande nod på grafen och väljer den med lägsta kostnad. Efter att ha utfört den valda åtgärden och uppdaterat den nuvarande övertygelsen, det upprepar omplaneringsprocessen."
Schemat som utformats av Kim och hans kollegor utnyttjar beteendet hos återkopplingskontrollanter i trosrummet. Med andra ord, återkopplingskontroller fungerar som en tratt i trosutrymme, med ett närliggande trostillstånd som potentiellt konvergerar med kontrollmålets trostillstånd. Detta tacklar effektivt en nyckelfråga för att lösa POMPD:exponentiell komplexitet i planeringshorisonten.
Faktiskt, när algoritmens nuvarande övertygelse konvergerar med en känd tro, det finns inget behov av att överväga handlingar och observationer som leder fram till den nuvarande övertygelsen. Detta leder i slutändan till bättre skalbarhet, låter robotar lösa mer komplexa navigeringsproblem.
Mars rover exempel. Kredit:NASA/JPL-Caltech/MSSS.
"Under dynamisk omplanering, den föreslagna metoden startar den lokala optimeringen med den (grova) globala policyn, " sa Kim. "Detta betyder att det kan fatta ett icke-närsynt beslut, till skillnad från andra onlineplanerare med en ändlig vikande horisont. Kortfattat, denna metod kan anpassa sig till dynamiska förändringar i miljön och fungera robust trots en omodellerad störning eller fel, samtidigt som man gör kostnadseffektiva planer i global mening."
Genom att eliminera onödiga stabiliseringssteg, metoden som utformats av Kim och hans kollegor överträffade feedbackbaserad informationsfärdplan (FIRM), en toppmodern teknik för att lösa POMDP:er. I framtiden, detta dynamiska omplaneringsschema i trosrymden skulle kunna möjliggöra bättre SLAP-förmåga i robotar som arbetar under olika grader av osäkerhet.
"Vi planerar nu att tillämpa vår metod på verkliga problem, " sa Kim. "En möjlig tillämpning är en prototyp Mars helikopter-rover navigering och koordinering för planetarisk utforskning, ett projekt som leds av Dr Ali-akbar Agha-mohammadi vid JPL. En helikopter som flyger över terrängen skulle kunna ge en grov karta så att en grov global policy kan erhållas i offlinefasen. Senare, en rover skulle dynamiskt planera om i onlinefasen, för att utföra säkra och kostnadseffektiva navigationsuppdrag."
© 2018 Tech Xplore