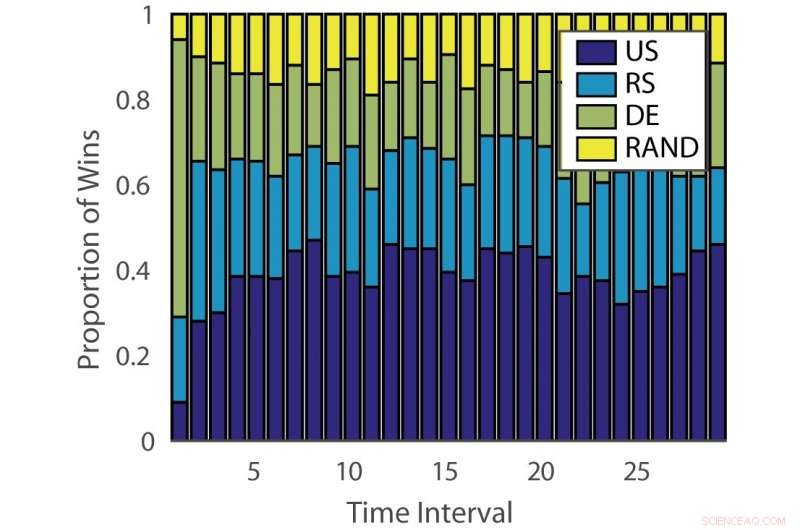
Andel vinster:"ILPD". Kredit:Pang et al.
Forskare vid University of Edinburgh, University College London (UCL) och Nara Institute of Science and Technology har utvecklat en ny ensemble-aktiv inlärningsmetod baserad på en icke-stationär flerarmad bandit och en expertrådgivningsalgoritm. Deras metod, presenteras i en tidning förpublicerad på arXiv, kan minska den tid och ansträngning som investeras i manuell anteckning av data.
"Konventionell övervakad maskininlärning är datahungrig, och märkta data kan vara en flaskhals när datakommentarer är dyrt, "Timothy Hospedales, en av forskarna som genomförde studien berättade för Tech Xplore. "Aktivt lärande stöder övervakat lärande genom att förutsäga de mest informativa datapunkterna att kommentera så att bra modeller kan tränas med en reducerad anteckningsbudget."
Aktiv inlärning är ett särskilt område av maskininlärning där en inlärningsalgoritm aktivt kan välja den data den vill lära sig av. Detta resulterar vanligtvis i bättre prestanda, med betydligt mindre utbildningsdatauppsättningar.
Forskare har utvecklat en mängd olika aktiva inlärningsalgoritmer som kan minska kostnaderna för anteckningar, men hittills, ingen av dessa lösningar har visat sig vara effektiv för alla problem. Andra studier har därför använt banditalgoritmer för att identifiera den bästa aktiva inlärningsalgoritmen för en given datamängd.
"Termen "bandit" syftar på en spelautomat med flera armar bandit, som är en bekväm matematisk abstraktion för utforsknings-/exploateringsproblem, Hospedales förklarade. "En banditalgoritm hittar en bra balans mellan ansträngning som spenderas på att utforska alla spelautomater för att ta reda på vilken som ger mest utbetalning, med ansträngning som lagts ner på att utnyttja den bästa spelautomaten som hittats hittills."
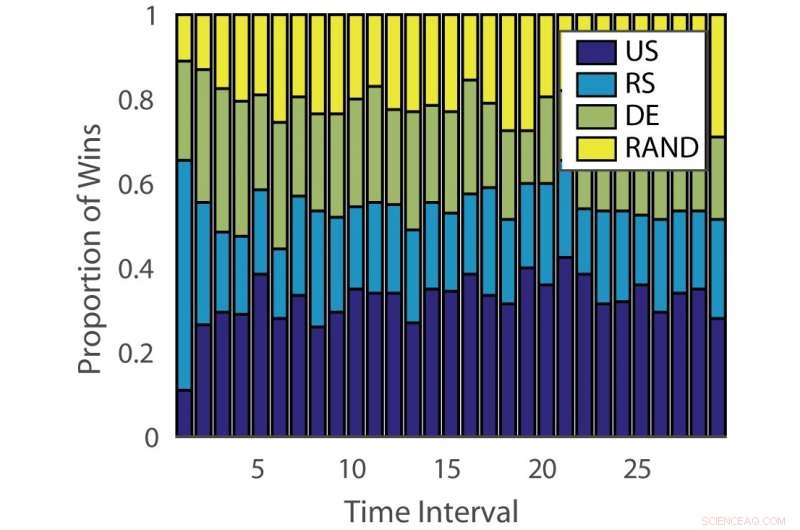
Andel vinster:"tysk". Kredit:Pang et al.
Effektiviteten av aktiva inlärningsalgoritmer varierar både över problem och över tid vid olika inlärningsstadier. Denna observation är analog med att spela spelautomater, där utbetalningssannolikheten förändras över tiden.
"Syftet med vår studie var att utveckla en ny banditalgoritm som förbättrar prestandan genom att ta hänsyn till denna aspekt av det aktiva inlärningsproblemet, " sa Hospedales.
För att ta itu med denna begränsning, forskarna föreslog en dynamisk ensemble active learner (DEAL) baserad på en icke-stationär bandit. Den här eleven bygger upp en uppskattning av varje aktiv inlärningsalgoritms effektivitet online, baserat på belöningen (viktighetsvägd noggrannhet) som erhålls efter varje anteckning av data.
"Det gör det genom att använda preferensen som uttrycks för den punkten av varje aktiv inlärningsalgoritm, "Kunkun Pang, en annan forskare som utförde studien, berättade för Tech Xplore. "För att ta itu med frågan om den förändrade effektiviteten hos aktiva elever över tiden, vi startar om inlärningsalgoritmen med jämna mellanrum för att uppdatera dess aktiva elevpreferens. Med denna förmåga, om den mest effektiva aktiva inlärningsalgoritmen ändras mellan tidiga och sena stadier av inlärning, vi kan snabbt anpassa oss till denna förändring."
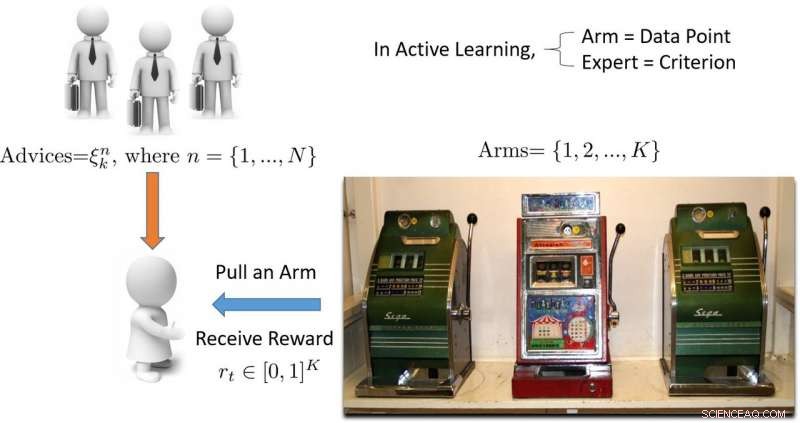
Illustration av flerarmad banditbaserad aktiv inlärningsmetod. Kredit:Pang et al.
Forskarna testade sin metod på 13 populära datauppsättningar, uppnå mycket uppmuntrande resultat. Deras DEAL-algoritm har en matematisk prestandagaranti, vilket innebär att det finns en hög grad av tilltro till hur väl det kommer att fungera.
"Garantin relaterar prestandan för vår algoritm, vilket är ett idealiskt orakel som alltid vet det rätta valet för den aktiva eleven, Hospedales förklarade. "Det ger en gräns för prestandagapet mellan en sådan best-case-algoritm och vår."
Den empiriska utvärderingen utförd av Hospedales och hans kollegor bekräftade att deras DEAL-algoritm förbättrar aktiv inlärningsprestanda på en uppsättning riktmärken. Den gör detta genom att kontinuerligt identifiera den mest effektiva aktiva inlärningsalgoritmen för olika uppgifter och i olika stadier av träningen.
"I dag, medan aktivt lärande är tilltalande, dess inverkan på metoder för maskininlärning är begränsad på grund av besväret med att matcha algoritmer till problem och till stadier av inlärning, "Hospedales sa. "DEAL eliminerar denna svårighet och ger ett tillvägagångssätt för att hantera många problem och alla stadier av lärande. Genom att göra aktivt lärande lättare att använda, vi hoppas att det kan ha en större inverkan på att minska anteckningskostnaderna i maskininlärning."
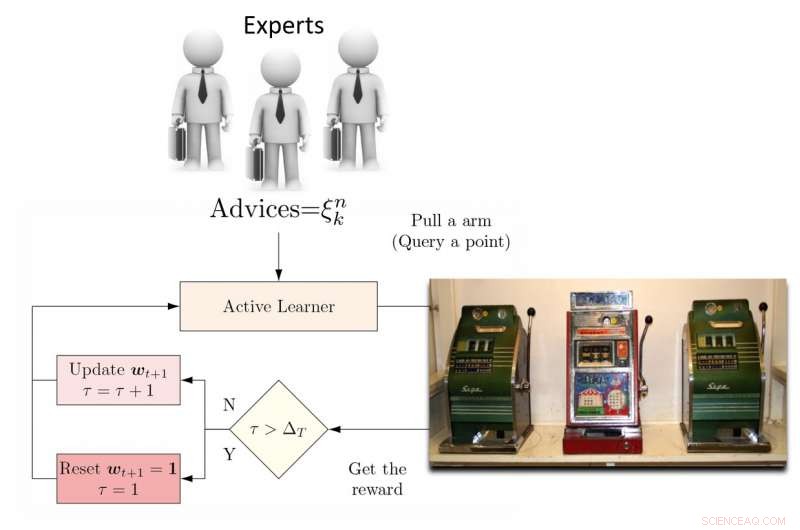
Illustration av DEAL REXP4-algoritmen. Kredit:Pang et al.
Trots de mycket lovande resultaten, tekniken som forskarna har utarbetat har fortfarande en betydande begränsning. DEAL gör all inlärning inom ett enda problem och detta resulterar i en "kallstart, betyder att algoritmen närmar sig alla nya problem med ett tomt blad.
"I pågående arbete, vi lär oss att kommentera många olika problem och så småningom överföra denna kunskap till ett nytt problem, för att utföra effektiv anteckning omedelbart utan krav på uppvärmning, " sade Pang. "Vårt preliminära arbete om detta ämne har publicerats och vann även priset för bästa papper på ICML 2018 AutoML-verkstad."
© 2018 Science X Network