WaveGlow nätverk. Kredit:Prenger, Valle, och Catanzaro.
Ett team av forskare på NVIDIA har nyligen utvecklat WaveGlow, ett flödesbaserat nätverk som kan generera högkvalitativt tal från melspektrogram, som är akustiska tids-frekvensrepresentationer av ljud. Deras metod, beskrivs i ett papper som för publicerats på arXiv, använder ett enda nätverk tränat med en enda kostnadsfunktion, gör träningsproceduren enklare och mer stabil.
"De flesta neurala nätverk för att syntetisera tal var för långsamma för oss, "Ryan Prenger, en av forskarna som genomförde studien, berättade TechXplore. "De var begränsade i hastighet eftersom de var utformade för att bara generera ett sampel i taget. Undantagen var tillvägagångssätt från Google och Baidu som genererade ljud väldigt snabbt parallellt. Men dessa tillvägagångssätt använde lärarnätverk och studentnätverk och var för komplexa för att replikera."
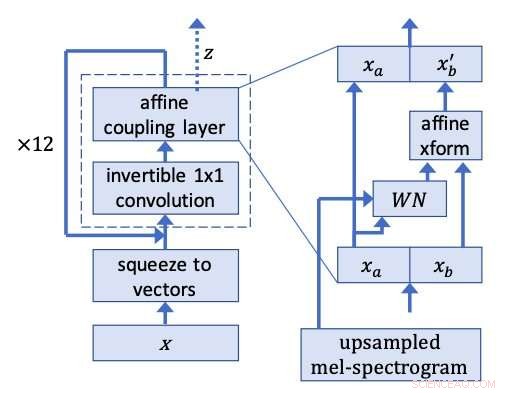
Forskarna drog inspiration från Glow, ett flödesbaserat nätverk av OpenAI som kan generera högkvalitativa bilder parallellt, behåller en ganska enkel struktur. Med hjälp av en inverterbar 1x1 faltning, Glow uppnådde anmärkningsvärda resultat, ger mycket realistiska bilder. Forskarna bestämde sig för att tillämpa samma idé bakom denna metod för talsyntes.
"Tänk på det vita bruset som kommer från en radio som inte är inställd på någon station, " Prenger förklarade. Att vitt brus är superlätt att generera. Grundidén med att syntetisera tal med WaveGlow är att träna ett neuralt nätverk för att omvandla det vita bruset till tal. Om du använder något gammalt neuralt nätverk, träning kommer att bli problematisk. Men om du specifikt använder ett nätverk som kan köras både bakåt och framåt, matematiken blir lätt och några av träningsfrågorna försvinner. "
Forskarna sprang talklipp från utbildningsdatabasen bakåt, träna WaveGlow för att producera något som liknar vitt brus. Deras modell tillämpar samma idé bakom Glow på en WaveNet-liknande arkitektur, alltså namnet WaveGlow.
I en PyTorch-implementering, WaveGlow producerade ljudsampel med en hastighet på över 500 kHz, på en NVIDIA V100 GPU. Crowd-sourced mean opinion score (MOS)-test på Amazon Mechanical Turk tyder på att metoden ger lika bra ljudkvalitet som den bästa allmänt tillgängliga WaveNet-metoden.
"I talsyntesvärlden, det finns behov av modeller som genererar tal mer än en storleksordning snabbare i realtid, "Prenger sa." Vi hoppas att WaveGlow kan fylla detta behov samtidigt som det är lättare att implementera och underhålla än andra befintliga modeller. I den djupa lärande världen, vi tror att denna typ av tillvägagångssätt med ett inverterbart neuralt nätverk och den resulterande enkla förlustfunktionen är relativt undersökt. WaveGlow ger ytterligare ett exempel på hur detta tillvägagångssätt kan ge generativa resultat av hög kvalitet trots sin relativa enkelhet."
WaveGlows kod är lätt tillgänglig online och kan nås av andra som vill prova den eller experimentera med den. Under tiden, forskarna arbetar med att förbättra kvaliteten på syntetiserade ljudklipp genom att finjustera deras modell och genomföra ytterligare utvärderingar.
"Vi har inte gjort mycket analys för att se hur små nätverk vi kan komma undan med, ", sa Prenger. "De flesta av våra arkitekturbeslut baserades på mycket tidiga delar av utbildningen. Dock, mindre nätverk med längre träningstid kan generera lika bra ljud. Det finns många intressanta riktningar som denna forskning kan gå i framtiden. "
© 2018 Science X Network