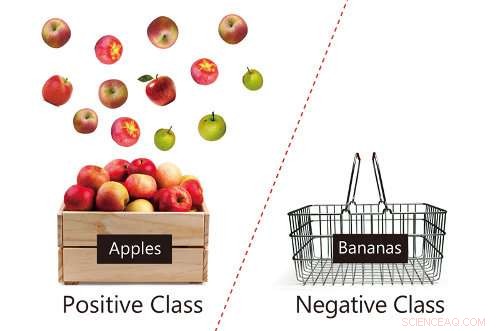
Schematisk som visar positiva data (äpplen) och brist på negativa data (bananer), med en illustration av tillförlitligheten hos äppeldata. Kredit:RIKEN
Ett forskargrupp från RIKEN Center for Advanced Intelligence Project (AIP) har framgångsrikt utvecklat en ny metod för maskininlärning som gör att en AI kan göra klassificeringar utan vad som kallas "negativa data, " ett resultat som skulle kunna leda till bredare tillämpning på en mängd olika klassificeringsuppgifter.
Att klassificera saker är avgörande för vårt dagliga liv. Till exempel, vi måste upptäcka skräppost, falska politiska nyheter, samt mer vardagliga saker som föremål eller ansikten. När du använder AI, sådana uppgifter är baserade på "klassificeringsteknik" inom maskininlärning – att låta datorn lära sig genom att använda gränsen som separerar positiv och negativ data. Till exempel, "positiva" data skulle vara foton inklusive ett glatt ansikte, och "negativa" datafoton som innehåller ett sorgligt ansikte. När en klassificeringsgräns väl är inlärd, datorn kan avgöra om en viss data är positiv eller negativ. Svårigheten med denna teknik är att den kräver både positiva och negativa data för inlärningsprocessen, och negativa data är inte tillgängliga i många fall (t.ex. det är svårt att hitta foton med etiketten, "det här fotot innehåller ett sorgset ansikte, " eftersom de flesta människor ler framför en kamera.)
När det gäller verkliga program, när en återförsäljare försöker förutse vem som kommer att göra ett köp, det kan enkelt hitta data om kunder som köpt från dem (positiv data), men det är i princip omöjligt att få information om kunder som inte köpt från dem (negativ data), eftersom de inte har tillgång till sina konkurrenters data. Ett annat exempel är en vanlig uppgift för apputvecklare:de måste förutsäga vilka användare som kommer att fortsätta använda appen (positiv) eller sluta (negativ). Dock, när en användare avslutar prenumerationen, utvecklarna förlorar användarens data eftersom de måste ta bort data om den användaren helt i enlighet med integritetspolicyn för att skydda personlig information.
Enligt huvudförfattaren Takashi Ishida från RIKEN AIP, "Tidigare klassificeringsmetoder kunde inte hantera situationen där negativa data inte var tillgängliga, men vi har gjort det möjligt för datorer att lära sig med bara positiva data, så länge vi har ett konfidensvärde för våra positiva data, konstruerad från information som köpavsikt eller den aktiva andelen appanvändare. Med vår nya metod, Vi kan bara låta datorer lära sig en klassificerare utifrån positiva data som är utrustade med förtroende. "
Ishida föreslog, tillsammans med forskaren Gang Niu från sin grupp och teamledare Masashi Sugiyama, att de låter datorer lära sig bra genom att lägga till konfidenspoängen, vilket matematiskt motsvarar sannolikheten om uppgifterna tillhör en positiv klass eller inte. De lyckades utveckla en metod som kan låta datorer lära sig en klassificeringsgräns endast från positiv data och information om dess tillförlitlighet (positiv tillförlitlighet) mot klassificeringsproblem av maskininlärning som delar upp data positivt och negativt.
För att se hur väl systemet fungerade, de använde den på en uppsättning foton som innehåller olika märken av modeartiklar. Till exempel, de valde "T-shirt, "som den positiva klassen och en annan sak, t.ex., "sandal", som den negativa klassen. Sedan bifogade de ett förtroendepoäng till "T-shirt"-bilderna. De fann att utan att komma åt de negativa uppgifterna (t.ex. "sandaler" bilder), i vissa fall, deras metod var lika bra som en metod som innebär att man använder positiva och negativa data.
Enligt Ishida, "Denna upptäckt kan utöka utbudet av applikationer där klassificeringsteknik kan användas. Även inom områden där maskininlärning har använts aktivt, vår klassificeringsteknik kan användas i nya situationer där endast positiva data kan samlas in på grund av datareglering eller affärsbegränsningar. Inom en snar framtid, vi hoppas kunna använda vår teknik inom olika forskningsområden, såsom bearbetning av naturligt språk, datorsyn, robotik, och bioinformatik."