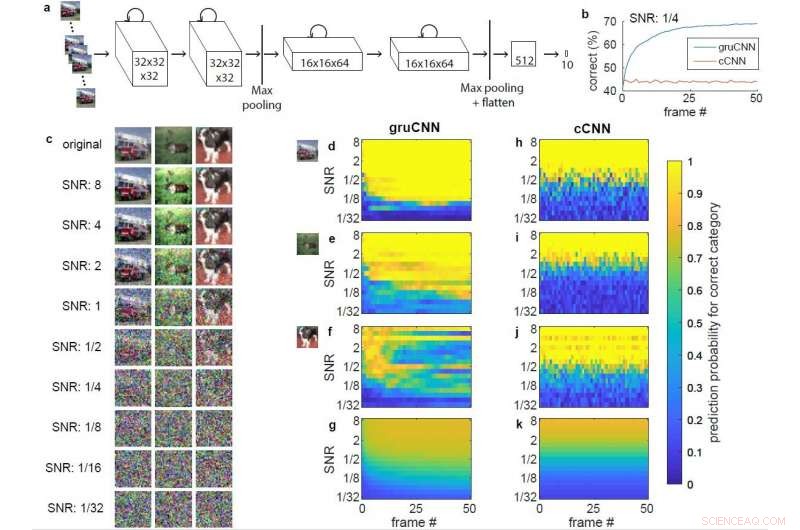
Arkitektur och exempeldata. a) gruCNNs arkitektur. Varje kanalaktivitet beror på både den aktuella ingången och det föregående tillståndet. b) Klassificeringsprestanda för exempel gruCNN och cCNN när alla testsekvenser hade en SNR på 1/4. c) Originalbild och bild med olika SNR för en brandbil (kategori lastbil) en ren (kategori hjort), och en hund, visas utan jitter. d–k) Färgkodade predikterade sannolikheter (utdata från softmax) för den korrekta (positiva) bildkategorin för gruCNN (d–g) och cCNN (h–k). Horisontella axlar visar förutspådda sannolikheter över 51 bildrutor, vertikala axlar över ett område av SNR. d) &h) och e) &i) motsvarar prestanda i brandbilen och renexempel, respektive. Den prediktiva sannolikheten vid låga SNR fortsätter att förbättras över ramar för gruCNN-förutsägelserna, men är relativt konstanta för cCNN. f) &j) Data för det tredje exemplet (hunden), där gruCNN misslyckas (vilket är sällsynt) medan cCNN förutsäger kategorin korrekt som mest SNR. Den genomsnittliga förutsagda sannolikheten för korrekt (positiv) bildkategori för alla 10, 000 testbilder visas i g) &k). Kredit:Till S. Hartmann/arXiv:1811.08537 [cs.CV].
Under de senaste åren, klassiska konvolutionella neurala nätverk (cCNN) har lett till anmärkningsvärda framsteg inom datorseende. Många av dessa algoritmer kan nu kategorisera objekt i bilder av god kvalitet med hög noggrannhet.
Dock, i verkliga applikationer, såsom autonom körning eller robotik, bilddata inkluderar sällan bilder tagna under idealiska ljusförhållanden. Ofta, bilderna som CNN skulle behöva för att bearbeta har tilltäppta objekt, rörelseförvrängning, eller låg signal / brusförhållande (SNR), antingen som ett resultat av dålig bildkvalitet eller låga ljusnivåer.
Även om cCNN också framgångsrikt har använts för att minska brus i bilder och förbättra deras kvalitet, dessa nätverk kan inte kombinera information från flera bildrutor eller videosekvenser och blir därför lätt bättre än människor på bilder av låg kvalitet. Till S. Hartmann, en neurovetenskaplig forskare vid Harvard Medical School, har nyligen genomfört en studie som tar upp dessa begränsningar, introducerar ett nytt CNN -tillvägagångssätt för analys av bullriga bilder.
Hartmann, som har en bakgrund inom neurovetenskap, har ägnat över ett decennium åt att studera hur människor uppfattar och bearbetar visuell information. På senare år har han blev allt mer fascinerad av likheterna mellan djupa CNN som används i datorseende och hjärnans visuella system.
I den visuella cortexen, område av hjärnan specialiserat på att bearbeta visuell input, majoriteten av neurala anslutningar görs i laterala och feedbackriktningar. Detta tyder på att det finns mycket mer med visuell bearbetning än de tekniker som används av cCNN. Detta motiverade Hartmann att testa faltningslager som innehåller återkommande bearbetning, vilket är avgörande för den mänskliga hjärnans bearbetning av visuell information.
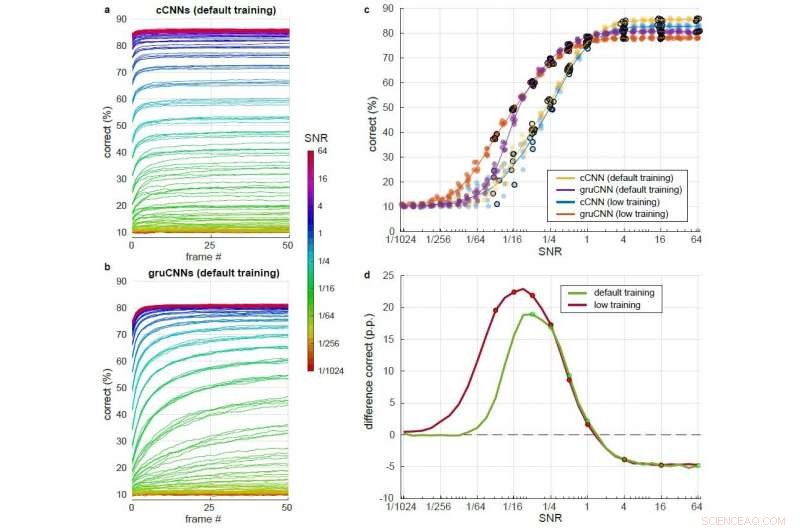
Detaljerad jämförelse av cCNN med Bayesiansk slutledning och gruCNN-prestanda över ett stort antal SNR-nivåer. Varje modellarkitektur testades efter träning med något högre SNR (standardträning) och efter träning med något lägre SNR (låg träning). a) &b) Procent korrekt under loppet av 51 bildrutor för olika SNR (färgkodade) med standardträning för a) cCNN (med Bayesian Inference) och b) gruCNN. c) Prickar:korrekt klassificering för modellarkitekturerna vid den sista bilden. Jitter i SNR-värden lades till för att öka läsbarheten av plotter, men fanns inte i uppgifterna. Linjer:genomsnittlig prestanda för de fem modellerna per arkitektur. d) Medelprestanda för gruCNN minus medelprestanda för cCNN för modeller tränade med standard och lägre SNR (grön och röd, respektive). SNR-nivåer som används under träning indikeras med prickar. Upphovsman:Till S. Hartmann/arXiv:1811.08537 [cs.CV].
Använda återkommande anslutningar inom CNN:s konvolutionella lager, Hartmanns tillvägagångssätt säkerställer att nätverk är bättre rustade för att behandla pixelbrus, som den som finns i bilder tagna under dåliga ljusförhållanden. När den testades på simulerade bullriga videosekvenser, återkommande CNN (gruCNN) presterade mycket bättre än klassiska metoder, framgångsrikt klassificera objekt i simulerade videor med låg kvalitet, som de som tas på natten.
Att lägga till återkommande anslutningar till ett faltningslager lägger till slutligen rumsligt begränsat minne, låter nätverket lära sig hur man integrerar information över tid innan signalen blir för abstrakt. Den här funktionen kan vara särskilt användbar när det är låg signalkvalitet, till exempel i bilder som är brusiga eller tagna under dåliga ljusförhållanden.
I sin studie, Hartmann fann att cCNNs fungerade bra på bilder med höga SNR, gruCNNs, överträffade dem på bilder med låg SNR. Till och med lägga till Bayes-optimala temporala integrationer, som tillåter cCNN att integrera flera bildramar, matchade inte gruCNN -prestanda. Hartmann observerade också att vid låga SNR, gruCNNs förutsägelser hade högre konfidensnivåer än de som producerades av cCNN.
Medan den mänskliga hjärnan har utvecklats för att se i mörkret, de flesta befintliga CNN är ännu inte utrustade för att behandla suddiga eller brusiga bilder. Genom att tillhandahålla nätverk med kapacitet att integrera bilder över tid, tillvägagångssättet som Hartmann utarbetat skulle så småningom kunna förbättra datorseendet till den grad att det matchar, eller till och med överstiger, mänskliga prestationer. Detta kan vara enormt för applikationer som självkörande bilar och drönare, liksom i andra situationer där en maskin måste 'se' under icke-ideala ljusförhållanden.
Studien som Hartmann genomförde skulle kunna bana väg för utvecklingen av mer avancerade CNN som kan analysera bilder tagna under dåliga ljusförhållanden. Att använda återkommande anslutningar i de tidiga stadierna av neurala nätverksbehandling kan avsevärt förbättra datorseendeverktyg, övervinna begränsningarna hos klassiska CNN-metoder vid bearbetning av brusiga bilder eller videoströmmar.
Som nästa steg, Hartmann skulle kunna utöka omfattningen av sin forskning genom att utforska verkliga tillämpningar av gruCNN, testa dem i ett brett utbud av verkliga scenarier. Potentiellt, hans tillvägagångssätt kan också användas för att förbättra kvaliteten på amatör- eller skakiga hemmavideor.
© 2018 Science X Network