Med utgångspunkt från slumpmässigt spel och ingen domänkunskap förutom spelreglerna, AlphaZero besegrade på ett övertygande sätt ett världsmästarprogram i schackspel och shogi (japanskt schack) samt Go. Kredit:DeepMind Technologies Ltd
Ett team av forskare med DeepMind-gruppen och University College, både i Storbritannien, har utvecklat ett AI-system som kan lära sig själv hur man spelar och bemästrar tre svåra brädspel. I deras papper publicerad i tidskriften Vetenskap , gruppen beskriver sitt nya system och förklarar varför de tror att det representerar ytterligare ett stort steg framåt i utvecklingen av AI-system. Murray Campbell med T.J Watson Research Center i USA erbjuder ett perspektiv på arbetet som gjorts av teamet i samma tidskriftsnummer.
Det har gått över 20 år sedan en superdator känd som Deep Blue slog världsmästaren i schack Gary Kasparov, visar världen hur långt AI-beräkningar hade kommit. Under åren sedan, datorer har blivit allt smartare och slår nu människor i spel som schack, shogi och Go. Men sådana system har alla justerats för att göra dem riktigt bra på bara ett spel. I denna nya ansträngning, forskarna har skapat ett AI-system som inte bara är bra på mer än ett spel, men skaffar sig sådan expertis på egen hand.
Det nya systemet, kallas AlphaZero, är ett förstärkande lärandesystem, som, som namnet antyder, betyder att den lär sig genom att upprepade gånger spela ett spel och lära sig av sina erfarenheter. Detta är, självklart, mycket likt hur människor lär sig. En grundläggande uppsättning regler läggs upp och sedan spelar datorn spelet – med sig själv. Den behöver inte ens spela med andra partners. Den spelar sig själv upprepade gånger, notera vilka spel som utgör bra drag och därmed vinna, och som utgör dåliga drag och förlust. Över tid, det förbättras. Så småningom, det blir så bra att det inte bara kan slå människor, men andra dedikerade AI-system för brädspel. Systemet använde också en sökmetod som kallas Monte Carlo-trädsökning. Genom att kombinera de två teknologierna kan systemet lära sig själv hur man blir bättre på att spela. Forskarna gav sitt testsystem mycket kraft, också, genom att anställa 5000 tensorbehandlingsenheter, vilket sätter den i nivå med stora superdatorer.
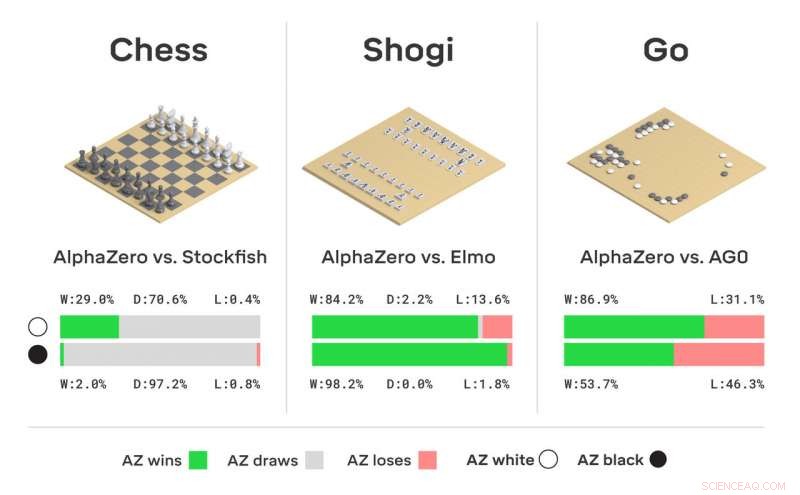
Turneringsutvärdering av AlphaZero i schack, shogi, och gå, som matcher vann, ritade eller förlorade ur AlphaZeros perspektiv, i matcher mot Stockfish, Elmo, och AlphaGo Zero (AG0) som tränades i tre dagar. Kredit:DeepMind Technologies Ltd
Än så länge, AlphaZero har bemästrat schack, shogi och Go – spel som är särskilt väl lämpade för AI-applikationer. Campbell föreslår att nästa steg för sådana system kan vara att förgrena sig till spel som poker, eller till och med populära videospel.
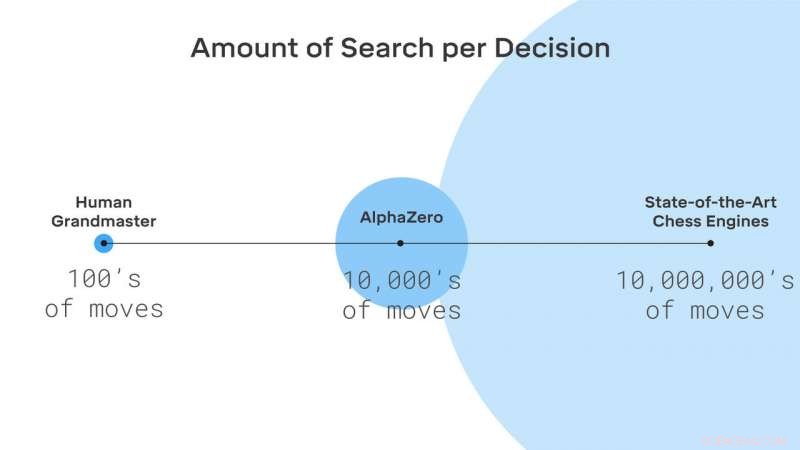
AlphaZero söker bara i en liten bråkdel av de positioner som anses av traditionella schackmotorer. Kredit:DeepMind Technologies Ltd
© 2018 Science X Network