Fynd, och mäta islamofobi hatprat på sociala medier. Upphovsman:John Gomez/Shutterstock
I ett landmärke, en grupp riksdagsledamöter publicerade nyligen en arbetsdefinition av termen islamofobi. De definierade det som "rotat i rasism", och som "en typ av rasism som riktar sig till uttryck för muslimitet eller uppfattad muslimitet".
I vårt senaste arbetsdokument, vi ville bättre förstå förekomsten och svårighetsgraden av sådana islamofoba hatprat på sociala medier. Sådant tal skadar riktade offer, skapar en känsla av rädsla bland muslimska samhällen, och strider mot grundläggande rättviseprinciper. Men vi stod inför en viktig utmaning:även om det är extremt skadligt, Islamofobiskt hattal är faktiskt ganska sällsynt.
Varje dag skickas miljarder inlägg på sociala medier, och bara ett mycket litet antal av dem innehåller något slags hat. Så vi började med att skapa ett klassificeringsverktyg med hjälp av maskininlärning som automatiskt upptäcker om tweets innehåller islamofobi eller inte.
Upptäcker islamofobiskt hattal
Stora framsteg har gjorts med att använda maskininlärning för att klassificera mer allmänt hatiskt yttrande robust, i stor skala och i tid. Särskilt, det har gjorts stora framsteg med att kategorisera innehåll baserat på om det är hatiskt eller inte.
Men islamofobiskt hatprat är mycket mer nyanserat och komplext än så här. Det kör spektrumet från att verbalt attackera, misshandla och förolämpa muslimer att ignorera dem; från att lyfta fram hur de uppfattas vara "annorlunda" till att antyda att de inte är legitima medlemmar i samhället; från aggression till uppsägning. Vi ville ta hänsyn till denna nyans med vårt verktyg så att vi kunde kategorisera om innehållet är islamofobiskt eller inte eller om islamofobin är stark eller svag.
Vi definierade islamofobiskt hatprat som "allt innehåll som produceras eller delas som uttrycker en urskillningslös negativitet mot islam eller muslimer". Detta skiljer sig från men är väl anpassat till parlamentsledamöternas arbetsdefinition av islamofobi, beskrivs ovan. Enligt våra definitioner, stark islamofobi inkluderar uttalanden som "alla muslimer är barbarer", medan svag islamofobi innehåller mer subtila uttryck, som "muslimer äter så konstig mat".
Att kunna skilja mellan svag och stark islamofobi hjälper inte bara oss att bättre upptäcka och ta bort hat, men också för att förstå dynamiken i islamofobi, undersöka radikaliseringsprocesser där en person gradvis blir mer islamofobisk, och ge bättre stöd till offren.
Upphovsman:Vidgen och Yasseri
Inställning av parametrar
Verktyget vi skapade kallas en övervakad maskininlärningsklassificerare. Det första steget i att skapa en är att skapa en tränings- eller testuppsättning - så här lär sig verktyget att tilldela tweets till var och en av klasserna:svag islamofobi, stark islamofobi och ingen islamofobi. Att skapa denna dataset är en svår och tidskrävande process eftersom varje tweet måste märkas manuellt, så maskinen har en grund att lära av. Ett ytterligare problem är att detektering av hatprat är i sig subjektivt. Vad jag anser är starkt islamofobiskt, du kanske tror är svag, och vice versa.
Vi gjorde två saker för att mildra detta. Först, vi ägnade mycket tid åt att skapa riktlinjer för märkning av tweets. Andra, vi hade tre experter som märker varje tweet, och använde statistiska tester för att kontrollera hur mycket de gick med på. Vi började med 4, 000 tweets, ur ett urval av 140 miljoner tweets som vi samlade in från mars 2016 till augusti 2018. De flesta av de 4, 000 tweets uttryckte ingen islamofobi, så vi tog bort många av dem för att skapa en balanserad dataset, bestående av 410 starka, 484 svaga, och 447 inga (totalt 1, 341 tweets).
Det andra steget var att bygga och ställa in klassificeraren genom tekniska funktioner och välja en algoritm. Funktioner är vad klassificeraren använder för att faktiskt tilldela varje tweet till rätt klass. Vår huvudsakliga egenskap var en ordinbäddningsmodell, en djupinlärningsmodell som representerar enskilda ord som en vektor med tal, som sedan kan användas för att studera ordlikhet och ordanvändning. Vi identifierade också några andra funktioner från tweets, som den grammatiska enheten, känslor och antalet omnämnanden av moskéer.
När vi hade byggt vår klassificerare, det sista steget var att utvärdera det, vilket vi gjorde genom att tillämpa den på en ny dataset med helt osynliga tweets. Vi valde 100 tweets som tilldelats var och en av de tre klasserna, alltså 300 totalt, och fick våra tre expertkodare att märka om dem. Detta låter oss utvärdera klassificerarens prestanda, jämför de etiketter som tilldelats av vår klassificerare med de faktiska etiketterna.
Klassificerarens främsta begränsning var att den kämpade för att identifiera svaga islamofobiska tweets eftersom dessa ofta överlappade med både starka och inga islamofoba. Som sagt, övergripande, dess prestanda var stark. Noggrannheten (antalet korrekt identifierade tweets) var 77% och precisionen var 78%. På grund av vår rigorösa design- och testprocess, vi kan lita på att klassificeraren sannolikt kommer att prestera på samma sätt när den används i stor skala "i naturen" på osynliga Twitter -data.
Använd vår klassificerare
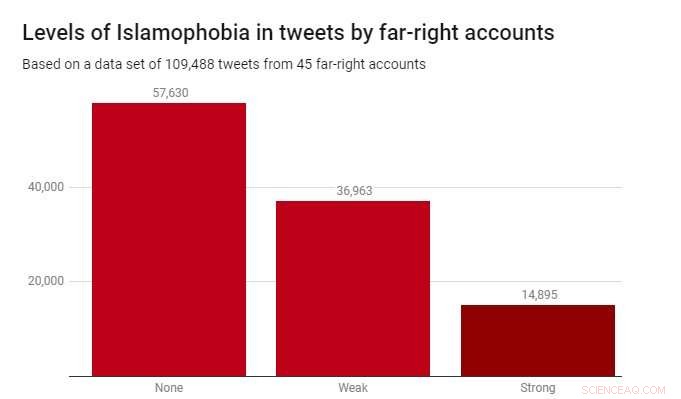
Vi tillämpade klassificeraren på en datamängd på 109, 488 tweets producerade av 45 högerextrema konton under 2017. Dessa identifierades av välgörenhetsorganisationen Hope Not Hate i deras 2015 och 2017 State of Hate-rapporter. Diagrammet nedan visar resultaten.
Medan de flesta tweets - 52,6% - inte var islamofoba, svag islamofobi var betydligt vanligare (33,8%) än stark islamofobi (13,6%). Detta tyder på att det mesta av islamofobin i dessa högerextrema konton är subtil och indirekt, snarare än aggressiv eller öppen.
Att upptäcka islamofobiskt hattal är en verklig och angelägen utmaning för regeringar, teknikföretag och akademiker. Tyvärr, detta är ett problem som inte kommer att försvinna - och det finns inga enkla lösningar. Men om vi menar allvar med att ta bort hatprat och extremism från onlinelokaler, och göra sociala medieplattformar säkra för alla som använder dem, då måste vi börja med lämpliga verktyg. Vårt arbete visar att det är fullt möjligt att göra dessa verktyg-att inte bara automatiskt upptäcka hatiskt innehåll utan också att göra det på ett nyanserat och finkornigt sätt.
Denna artikel publiceras från The Conversation under en Creative Commons -licens. Läs originalartikeln.