Kredit:CC0 Public Domain
Ny SFI-forskning utmanar en populär uppfattning om hur maskininlärningsalgoritmer "tänker" om vissa uppgifter.
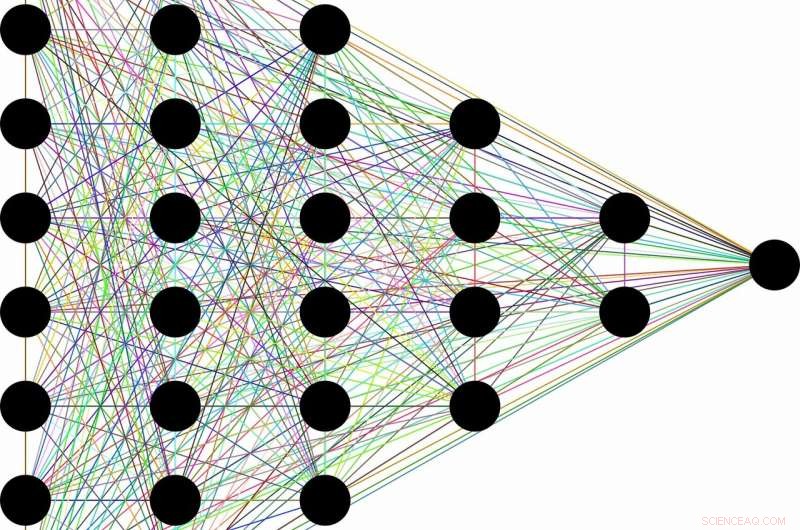
Uppfattningen är ungefär så här:på grund av deras förmåga att förkasta värdelös information, en klass av maskininlärningsalgoritmer som kallas djupa neurala nätverk kan lära sig allmänna begrepp från rådata – som att identifiera katter i allmänhet efter att ha stött på tiotusentals bilder av olika katter i olika situationer. Denna till synes mänskliga förmåga sägs uppstå som en biprodukt av nätverkens skiktade arkitektur. Tidiga lager kodar "katt"-etiketten tillsammans med all råinformation som behövs för förutsägelse. Efterföljande lager komprimerar sedan informationen, som genom en flaskhals. Irrelevanta uppgifter, som färgen på kattens päls, eller fatet med mjölk bredvid, är bortglömd, lämnar bara allmänna egenskaper bakom sig. Informationsteori ger gränser för hur optimalt varje lager är, när det gäller hur väl den kan balansera de konkurrerande kraven på komprimering och förutsägelse.
"Många gånger när du har ett neuralt nätverk och det lär sig att kartlägga ansikten till namn, eller bilder till numeriska siffror, eller fantastiska saker som fransk text till engelsk text, den har många mellanliggande dolda lager som information flödar igenom, säger Artemy Kolchinsky, en SFI-postdoktor och studiens huvudförfattare. "Så det finns den här långvariga idén att när råa indata omvandlas till dessa mellanliggande representationer, systemet handlar förutsägelse för komprimering, och bygga koncept på högre nivå genom denna informationsflaskhals."
Dock, Kolchinsky och hans medarbetare Brendan Tracey (SFI, MIT) och Steven Van Kuyk (University of Wellington) upptäckte en överraskande svaghet när de tillämpade denna förklaring på vanliga klassificeringsproblem, där varje ingång har en korrekt utgång (t.ex. där varje bild antingen kan vara av en katt eller av en hund). I sådana fall, de fann att klassificerare med många lager i allmänhet inte ger upp en viss förutsägelse för förbättrad komprimering. De fann också att det finns många "triviala" representationer av indata som är, ur informationsteoretisk synvinkel, optimala när det gäller deras balans mellan förutsägelse och komprimering.
"Vi upptäckte att det här informationsflaskhalsmåttet inte ser komprimering på samma sätt som du eller jag. Med tanke på valet, det är lika gärna att klumpa ihop "martiniglasögon" med "Labradors", som det är att klumpa ihop dem med champagneflöjter, "" Tracey förklarar. "Detta betyder att vi bör fortsätta söka efter kompressionsmått som bättre matchar våra föreställningar om kompression."
Även om idén att komprimera indata fortfarande kan spela en användbar roll i maskininlärning, denna forskning tyder på att det inte är tillräckligt för att utvärdera de interna representationerna som används av olika maskininlärningsalgoritmer.
På samma gång, Kolchinsky säger att konceptet med avvägning mellan komprimering och förutsägelse fortfarande kommer att hålla för mindre deterministiska uppgifter, som att förutsäga vädret från en bullrig datauppsättning. "Vi säger inte att informationsflaskhals är värdelös för övervakad [maskin]inlärning, " Kolchinsky betonar. "Vad vi visar här är att det beter sig kontraintuitivt på många vanliga maskininlärningsproblem, och det är något som människor i maskininlärningsgemenskapen borde vara medvetna om."