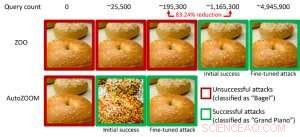
Figur 1:Prestandajämförelse för att förvandla en bagelbild till en motstridig bagelbild som klassificeras som en "flygel" med ZOO- och AutoZOOM-attacker. Kredit:IBM
Nyligen genomförda studier har identifierat bristen på robusthet i nuvarande AI-modeller mot kontradiktoriska exempel – avsiktligt manipulerade förutsägelseundanvikande datainmatningar som liknar normala data men kommer att få vältränade AI-modeller att missköta sig. Till exempel, visuellt omärkliga störningar av en stoppskylt kan enkelt skapas och leda en högprecisions AI-modell mot felklassificering. I vårt tidigare dokument som publicerades vid European Conference on Computer Vision (ECCV) 2018, vi validerade att 18 olika klassificeringsmodeller tränade på ImageNet, en stor datauppsättning för allmänt objektigenkänning, är alla sårbara för motstridiga störningar.
I synnerhet, motstridiga exempel genereras ofta i inställningen "white-box", där AI-modellen är helt transparent för en motståndare. I det praktiska scenariot, när du använder en egenutbildad AI-modell som en tjänst, som ett online-bildklassificerings-API, man kan felaktigt tro att den är robust för motstridiga exempel på grund av begränsad tillgång och kunskap om den underliggande AI-modellen (aka "svarta lådan"-inställningen). Dock, vårt senaste arbete publicerat på AAAI 2019 visar att robustheten på grund av begränsad modellåtkomst inte är jordad. Vi tillhandahåller ett allmänt ramverk för att generera motstridiga exempel från den riktade AI-modellen med endast modellens input-output-svar och få modellfrågor. Jämfört med det tidigare arbetet (ZOO-attack), vårt föreslagna ramverk, kallas AutoZOOM, minskar minst 93 % modellfrågor i genomsnitt samtidigt som man uppnår liknande attackprestanda, tillhandahåller en frågeeffektiv metod för att utvärdera motståndskraften hos AI-system med begränsad åtkomst. Ett illustrerande exempel visas i figur 1, där en motstridig bagelbild genererad från en svart-box bildklassificerare kommer att klassificeras som attackmålet "flygel". Denna artikel är utvald för muntlig presentation (29 januari, 11:30-12:30 @ coral 1) och affischpresentation (29 januari, 18:30-20:30) på AAAI 2019.
I inställningen för vit låda, kontradiktoriska exempel skapas ofta genom att utnyttja gradienten för ett designat attackmål i förhållande till datainmatningen för vägledning av kontradiktorisk störning, vilket kräver att man känner till modellarkitekturen såväl som modellvikterna för slutledning. Dock, i black-box-inställningen är det omöjligt att skaffa gradienten på grund av begränsad tillgång till dessa modelldetaljer. Istället, en motståndare kan bara komma åt input/output-svaren för den distribuerade AI-modellen, precis som vanliga användare (t.ex. ladda upp en bild och ta emot förutsägelsen från ett online-bildklassificerings-API). Det visades först i ZOO-attacken att det är möjligt att generera motstridiga exempel från modeller med begränsad åtkomst genom att använda tekniker för gradientuppskattning. Dock, det kan krävas en enorm mängd modellfrågor för att skapa ett kontradiktoriskt exempel. Till exempel, i figur 1, ZOO-attack tar mer än 1 miljon modellfrågor för att hitta den kontradiktoriska bagelbilden. För att påskynda frågeeffektiviteten när det gäller att hitta motstridiga exempel i den svarta lådan, vårt föreslagna AutoZOOM-ramverk har två nya byggstenar:(i) en adaptiv strategi för slumpmässig gradientuppskattning för att balansera antalet frågeräkningar och förvrängning, och (ii) en autokodare som antingen tränas offline med omärkta data eller en bilinjär storleksändringsoperation för acceleration. För (i), AutoZOOM har en optimerad och frågeeffektiv gradientestimator, som har ett adaptivt schema som använder få frågor för att hitta den första framgångsrika motstridiga störningen och sedan använder fler frågor för att finjustera distorsionen och göra det motstridiga exemplet mer realistiskt. För (ii), som visas i figur 2, AutoZOOM implementerar en teknik som kallas "dimensionsreduktion" för att minska komplexiteten i att hitta motstridiga exempel. Dimensionsminskningen kan realiseras av en offline-tränad autokodare för att fånga dataegenskaper eller en enkel bilinjär bildförändring som inte kräver någon träning.
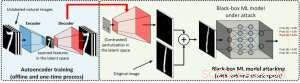
Figur 2:Illustration av dimensionsreduktionstekniken som används i AutoZOOM för inlösen av frågor. Avkodaren kan antingen vara en offlinetränad autokodare eller en bilinjär storleksändringsoperation som inte kräver någon träning. Kredit:IBM
Med dessa två kärntekniker, våra experiment med black-box djupa neurala nätverksbaserade bildklassificerare tränade på MNIST, CIFAR-10 och ImageNet visar att AutoZOOM uppnår en liknande attackprestanda samtidigt som den uppnår en betydande minskning (minst 93 %) av det genomsnittliga antalet frågeställningar jämfört med ZOO-attacken. På ImageNet, denna drastiska minskning innebär miljontals färre modellförfrågningar, vilket gör AutoZOOM till ett effektivt och praktiskt verktyg för att utvärdera motståndskraften hos AI-modeller med begränsad åtkomst. Dessutom, AutoZOOM är en generell sökinlösenaccelerator som lätt kan tillämpas på olika metoder för att generera motstridiga exempel i den praktiska svarta lådan.
AutoZOOM-koden är öppen källkod och kan hittas här. Kolla också in IBM:s Adversarial Robustness Toolbox för fler implementeringar av motstridiga attacker och försvar.
Den här historien återpubliceras med tillstånd av IBM Research. Läs originalberättelsen här.














