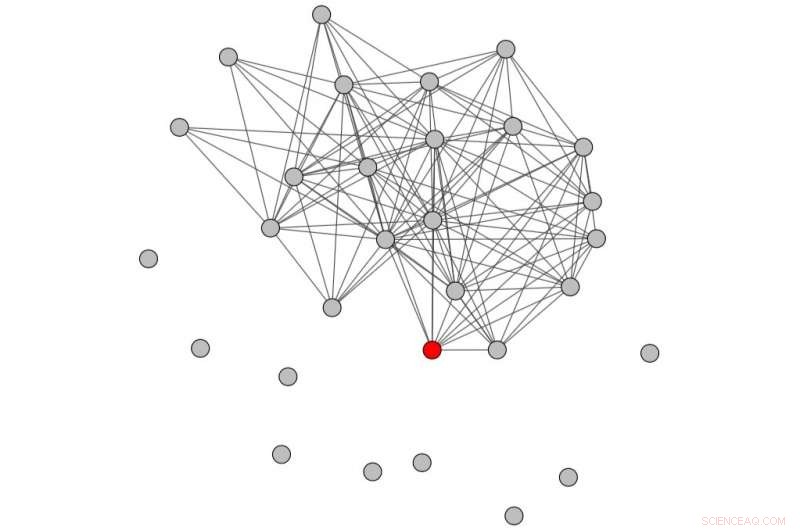
Konversationsdiagram erhållet genom att överväga en tidsperiod före missbruket. Kredit:Papegnies et al.
Ett team av forskare vid Avignon University har nyligen utvecklat ett system för att automatiskt upptäcka övergrepp i onlinesamhällen. Detta system, presenterad i ett papper som för publicerats på arXiv, visade sig överträffa befintliga metoder för att upptäcka missbruk och moderera användargenererat innehåll.
"Ständigt växande onlinesamhällen erbjuder möjlighet att sprida idéer via internet, garantera användare lite anonymitet, "sa forskarna till TechXplore, via e-post. "Dock, dessa utrymmen har ofta användare som visar kränkande beteende. För samhällsledare, det är viktigt att mildra dessa skadliga handlingar, eftersom underlåtenhet att göra det kan förgifta samhället, utlösa användarnas utvandring och utsätta administratörer för juridiska frågor. "
Moderering av online-användargenererat innehåll utförs i allmänhet manuellt av människor; därav, det kan vara både dyrt och tidskrävande. För att minska kostnaderna, forskare har försökt utveckla helautomatiserade verktyg för innehållsmoderering som antingen kan ersätta eller hjälpa mänskliga moderatorer.
"I det här arbetet, vi formulerar uppgiften om innehållsmoderering som ett klassificeringsproblem, och tillämpa vår metod på ett korpus av meddelanden som utbyts av spelare i en MMORPG, ett massivt multiplayer online rollspel, "sa forskarna.
Som ett första steg, forskarna extraherade konversationsnätverk från råa chattloggar som representerar samtalen där varje kränkande meddelande skickades, och kännetecknade dem med topologiska åtgärder. De använde sina resultat som funktioner, utbildning av en klassificerare för att upptäcka missbruk på onlineplattformar.
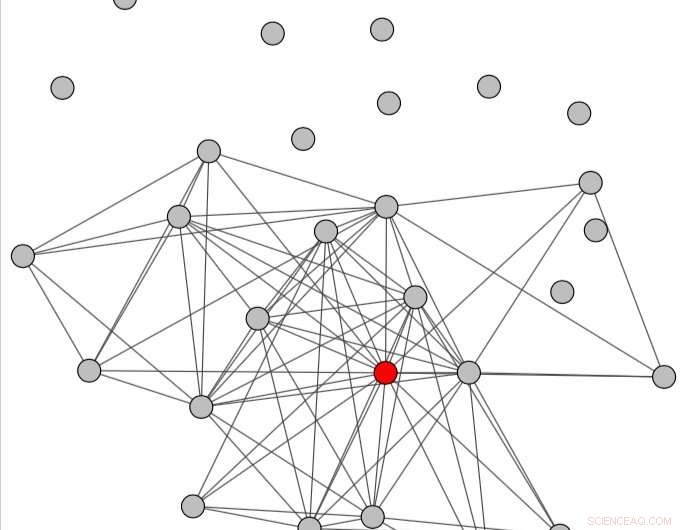
Konversationsgrafen erhålls genom att överväga en tidsperiod efter missbruket. Kredit:Papegnies et al.
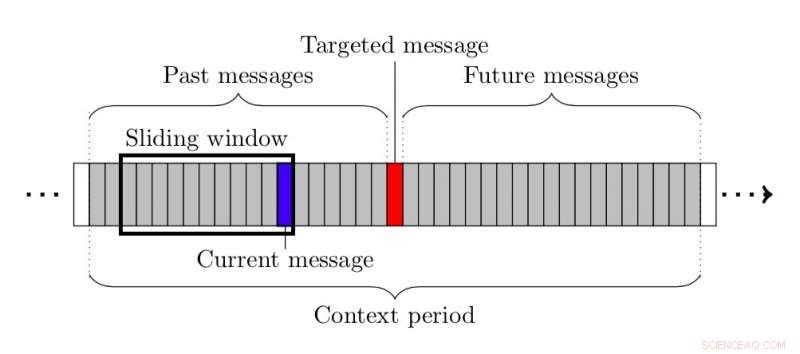
När du extraherar konversationsnätverk, forskarna följde en trestegsmetod. Först, de identifierade delmängden av meddelanden som de skulle använda för att extrahera nätverket. Sedan, de valde en delmängd av användare som var de troliga mottagarna av varje meddelande. Till sist, de lade till kanter och reviderade sina vikter baserat på dessa potentiella meddelandemottagare.
"Befintliga metoder för automatisk upptäckt av kränkande meddelanden fokuserar på textinnehållet i de utbytta meddelandena, vilket väcker många frågor:språkspecifika problem, syntaxfel, Stavningsfel, förvirring, och andra, "förklarade forskarna." Tvärtom, vi använder endast närvaron/frånvaron av interaktioner mellan användare, dvs. det faktum att de utbyter vissa meddelanden (eller inte), genom att motsätta sig de utbytade meddelandets karaktär. Att ignorera innehållet gjorde att vi kunde lösa dessa problem. "
Väsentligen, forskarna modellerade onlinesamtal med hjälp av en graf där noder representerar användare och länkar representerar meddelandeutbyten. Med hjälp av grafspecifika mått, de kunde observera skillnader i hur konversationer struktureras beroende på om de innehåller kränkande meddelanden eller inte. Dessa skillnader användes sedan för att träna en klassificerare för att upptäcka missbruk i konversationer mellan användare.
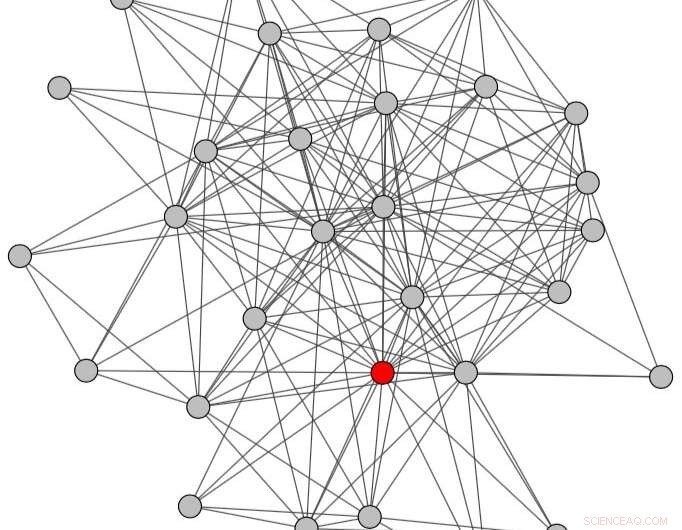
Konversationsdiagram erhållet genom att beakta hela tidsperioden (dvs. både före och efter missbruket). Kredit:Papegnies et al.
"Vår första insats, presenterade i en tidigare artikel, baserades på det traditionella tillvägagångssättet, d.v.s. det använde textinnehållet i meddelanden, "förklarade forskarna." När vi föreslog denna grafbaserade metod, vi förväntade oss inte att det skulle fungera så bra; vi trodde till och med att det skulle resultera i lägre prestanda jämfört med den innehållsbaserade metoden. Vi blev mycket förvånade över att få betydligt bättre resultat. Detta är det mest meningsfulla fyndet i vår studie - att, åtminstone för denna specifika uppgift, samtalets struktur är mer diskriminerande än arten av det utbytta innehållet. "
Kredit:Papegnies et al.
Kredit:Papegnies et al.
Forskarna testade sitt system på en datamängd med användarkommentarer från ett franskt MMORPG -spel och fann att det överträffade befintliga tillvägagångssätt, med ett F-mått på 83,89 när du använder hela funktionsuppsättningen. Genom att minska funktionsuppsättningen och behålla endast de mest diskriminerande funktionerna, de kunde dramatiskt minska datortiden, med bibehållen utmärkt prestanda. I framtiden, deras grafbaserade tillvägagångssätt kan också tillämpas på andra meddelandeklassificeringsuppgifter, till exempel online -upptäckt av troll.
"Vi kommer nu att försöka slå samman båda tillvägagångssätten (innehålls- och grafbaserade), för att kontrollera om de utnyttjar liknande information, i så fall skulle resultaten vara liknande, eller om de förlitar sig på kompletterande information, i vilket fall, att kombinera dem bör leda till förbättringar i prestanda, "tillade forskarna." Sedan, vi vill gå mot en mer automatiserad metod för att karakterisera våra konversationsgrafer, kallas grafinbäddningar. Det är en djup inlärningsbaserad metod som består i att träna ett neuralt nätverk för att få en effektiv representation av graferna. Som jämförelse, vi gör för närvarande denna del av arbetet manuellt, via en uppgift som kallas funktionsval. "
© 2019 Science X Network