Detta kan låta som en munsbit men det betyder verkligen mycket. Mozilla talar om "den hittills största publika domänen transkriberade röstdataset." Översättning:Över 14, 000 personer. På 18 språk. Av nästan 1, 400 timmar (1, 368 för att vara exakt) av inspelad röst. Välkommen till ett initiativ kallat Common Voice.
Detta är vad Mozillas tillkännagivande sa, i form av en blogg på torsdag från George Roter.
"I dag, vi är glada över att dela vår första flerspråkiga dataset med 18 språk representerade, inklusive engelska, franska, tyska och mandarinkinesiska (traditionell), men också till exempel walesiska och kabyle. Sammanlagt, den nya datamängden innehåller cirka 1, 400 timmars röstklipp från mer än 42, 000 personer."
Bidragsgivare till projektet har professionella specialiteter som sträcker sig från doktorander i taligenkänning till maskininlärningsforskare till en professor i beräkningslingvistik. Som sådan, insatsen representerar en global gemenskap av röstbidragsgivare tillsammans med vad Mozilla krediterade som "passionerade volontärer."
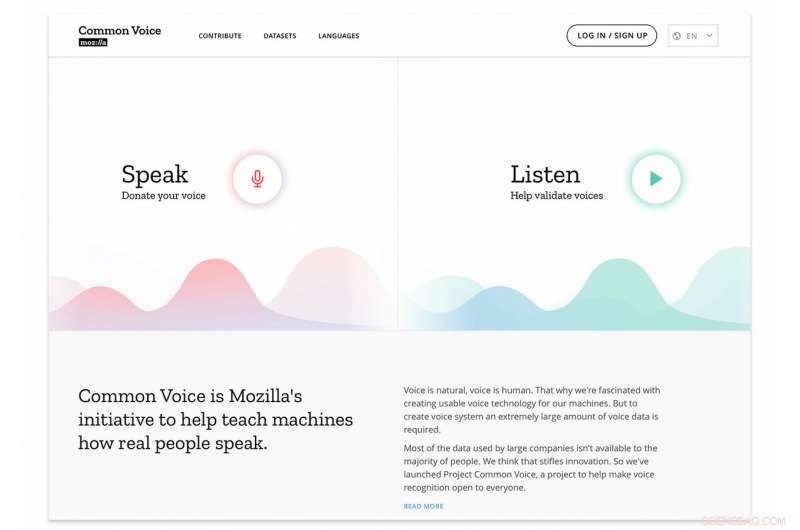
Syftet med Common Voice är att hjälpa maskiner att lära sig hur riktiga människor talar. I korthet, det har utvecklats till en enorm samling röstklipp på dussintals språk. Vad händer härnäst:Den fullständiga datamängden kommer att finnas tillgänglig för nedladdning på Common Voice-webbplatsen.
Det ser ut som om Mozilla-teamets bidragsgivare också räknade ut de oundvikliga smärtpunkterna. Bloggen nämnde de punkterna. "Människor som bidrar ser inte bara framsteg per språk i inspelning och validering, men har också förbättrade uppmaningar som varierar från klipp till klipp; ny funktionalitet att granska, spela in igen, och hoppa över klipp som en integrerad del av upplevelsen; förmågan att snabbt flytta mellan tala och lyssna; samt en funktion för att välja bort att tala under en session."
Låter som kul eller en akademisk sandlåda men faktiskt finns det mer solida ambitioner bland dem som har bidragit till att bygga upp dess korpus.
Under 2019, Mariella Moon in Engadget har märkt att utbudet av språk som nu ingår nederländska, Hakha-Chin, esperanto, Persiska, baskiska, spanska, franska, Tysk, Mandarinkinesisk (traditionell), walesiska och kabyle.
TechRadar Olivia Tambini, sa, "Genom att tillhandahålla ett stort bibliotek av mänskliga röster på en rad olika språk gratis, Mozilla kan öppna dörrarna för företag som inte har Apples resurser, Amazon, och Google, att utveckla sina egna röstassistenter."
En annan fördel är Mozilla själv. Mariella Moon in Engadget sa, "Organisationen själv planerar att använda klippen den samlar in för att förbättra sitt tal-till-text, Text-till-tal- och DeepSpeech-motorer."
Roter sa, lätt och enkel, "Vårt mål är att både släppa röstaktiverade produkter själva, samtidigt som de stödjer forskare och mindre aktörer."
Observera att skryträtten tillhör att den är den största, inte den enda, datauppsättning av sitt slag. Mozilla ville att webbplatsbesökarna skulle veta att det var den största, inte den enda, och sa också att webbplatsbesökare med tiden kan "se den här sidan som ett referensnav för andra röstdatauppsättningar med öppen källkod."
Om du besöker Common Voice-webbplatsen får du beskedet om deras stora ambitioner. "Vi bygger, " sa Mozilla. Och vad bygger de? En "öppen källkod, flerspråkig datauppsättning av röster som alla kan använda för att träna talaktiverade applikationer."
Bidragsgivare kan välja att tillhandahålla metadata som deras ålder, sex, och accent. Röstklipp i sin tur är taggade med information som är användbar för att träna talmotorer.
© 2019 Science X Network