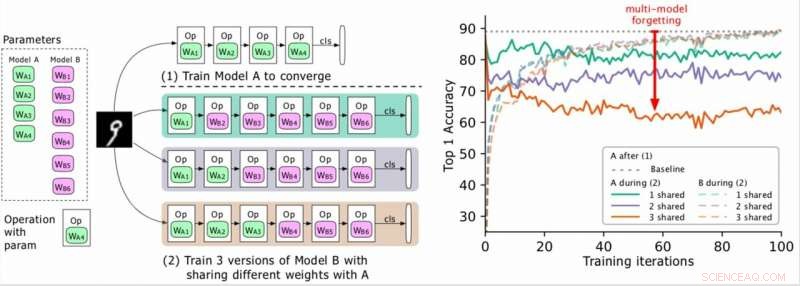
(Vänster) Två modeller som ska utbildas (A, B), där A:s parametrar är gröna och B:er i lila, och B delar några parametrar med A (indikerat med grönt under fas 2). Forskarna utbildar först A till konvergens och sedan utbildar B. (Höger) Noggrannhet i modell A när utbildningen av B fortskrider. De olika färgerna motsvarar olika antal delade lager. Noggrannheten för A minskar dramatiskt, särskilt när fler lager delas, och forskarna hänvisar till droppen (den röda pilen) som multimodellglömning. Upphovsman:Benyahia, Yu et al.
Under de senaste åren har forskare har utvecklat djupa neurala nätverk som kan utföra en mängd olika uppgifter, inklusive visuell igenkänning och NLP -uppgifter (Natural Language Processing). Även om många av dessa modeller uppnådde anmärkningsvärda resultat, de utför vanligtvis bara bra på en viss uppgift på grund av det som kallas "katastrofal glömning".
Väsentligen, katastrofal glömning innebär att när en modell som först utbildades i uppgift A senare tränas i uppgift B, dess prestanda på uppgift A kommer att avsevärt minska. I ett papper som för publicerats på arXiv, forskare vid Swisscom och EPFL identifierade en ny typ av glömning och föreslog ett nytt tillvägagångssätt som kan hjälpa till att övervinna det via en statistiskt motiverad viktförlust av plasticitet.
"När vi började arbeta med vårt projekt, att designa neurala arkitekturer automatiskt var beräknat dyrt och omöjligt för de flesta företag, "Yassine Benyahia och Kaicheng Yu, studiens primära utredare, berättade för TechXplore via e-post. "Det ursprungliga syftet med vår studie var att identifiera nya metoder för att minska denna kostnad. När projektet startade, ett papper från Google påstod att det drastiskt har minskat den tid och de resurser som krävs för att bygga neurala arkitekturer med en ny metod som kallas viktdelning. Detta gjorde autoML möjligt för forskare utan stora GPU -kluster, uppmuntra oss att studera detta ämne mer ingående. "
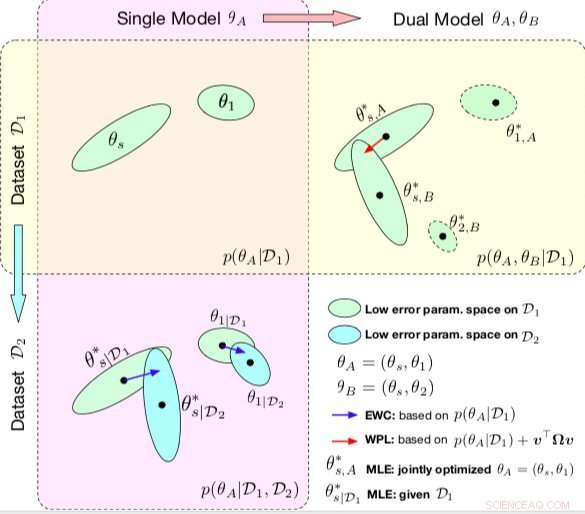
Jämförelse mellan EWC och WPL. Ellipserna i varje delplan representerar parameterregioner som motsvarar lågt fel. (Överst till vänster) Båda metoderna börjar med en enda modell, med parametrar θA ={θs, θ1}, utbildad på en enda dataset D1. (Nederst till vänster) EWC reglerar alla parametrar baserade på p (θA | D1) för att träna samma initialmodell på en ny datamängd D2. (Överst till höger) Däremot WPL använder den ursprungliga datamängden D1 och reglerar endast de delade parametrarna baseds baserat på både p (θA | D1) och v> Ωv, medan parametrarna θ2 kan röra sig fritt. Upphovsman:Benyahia, Yu et al.
Under sin forskning om neurala nätverksbaserade modeller, Benyahia, Yu och deras kollegor märkte ett problem med viktdelning. När de tränade två modeller (t.ex. A och B) sekventiellt, modell A:s prestanda sjönk, medan modell B:s prestanda ökade, eller tvärtom. De visade att detta fenomen, som de kallade "multi-model glömma, "kan hindra prestanda för flera auto-ml-tillvägagångssätt, inklusive Googles effektiva neuralarkitektursökning (ENAS).
"Vi insåg att viktdelning fick modeller att påverka varandra negativt, vilket gjorde att sökningsprocessen för arkitekturen var närmare slumpmässig, "Benyahia och Yu förklarade." Vi hade också våra reserver för arkitektursökning, där endast de slutliga resultaten belyses och där det inte finns några bra ramar för att utvärdera kvaliteten på arkitektursökningen på ett rättvist sätt. Vårt tillvägagångssätt kan hjälpa till att åtgärda detta glömska problem, eftersom det är relaterat till en kärnmetod som nästan alla senaste autoML -papper förlitar sig på, och vi anser att denna påverkan är enorm för samhället. "
I deras studie, forskarna modellerade multimodell som glömde matematiskt och härledde en ny förlust, kallas viktplasticitetsförlust. Denna förlust kan minska att flera modeller glömmer avsevärt genom att reglera inlärningen av en modells delade parametrar beroende på deras betydelse för tidigare modeller.
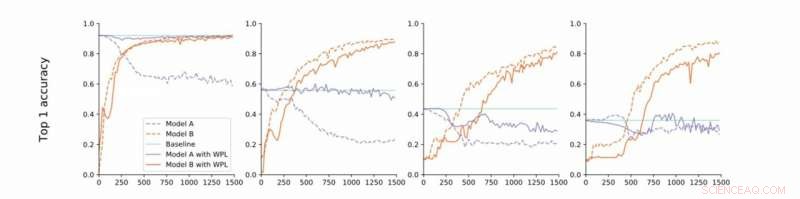
Från strikt till lös konvergens. Forskarna utför experiment på MNIST med modellerna A och B med delade parametrar och rapporterar noggrannheten hos modell A före utbildning av modell B (baslinje, grön) och noggrannheten hos modellerna A och B när du tränar modell B med (orange) eller utan (blå) WPL. I (a) visar de resultaten för strikt konvergens:A tränas inledningsvis i konvergens. De slappnar sedan av detta antagande och tränar A till cirka 55% (b), 43% (c), och 38% (d) av dess optimala noggrannhet. WPL är mycket effektivt när A tränas till minst 40% av optimaliteten; Nedan, Fisher -informationen blir för felaktig för att ge viktiga vikter. Således hjälper WPL att minska glömning av flera modeller, även när vikterna inte är optimala. WPL minskade glömningen med upp till 99,99% för (a) och (b), och med upp till 2% för (c). Upphovsman:Benyahia, Yu et al.
"I grund och botten, på grund av överparameterisering av neurala nätverk, vår förlust minskar parametrar som är 'mindre viktiga' för den slutliga förlusten först, och håller de viktigare oförändrade, "Benyahia och Yu sa." Modell A:s prestanda påverkas alltså inte, medan modell B:s prestanda fortsätter att öka. På små datamängder, vår modell kan minska glömningen upp till 99 procent, och på autoML -metoder, upp till 80 procent mitt under träningen. "
I en serie tester, forskarna visade effektiviteten i deras tillvägagångssätt för att minska glömning av flera modeller, både i fall där två modeller tränas sekventiellt och för neural arkitektur sökning. Deras resultat tyder på att viktplasticitet i neuralarkitektursökning kan avsevärt förbättra prestandan för flera modeller på både NLP- och datorvisionsuppgifter.
Studien utförd av Benyahia, Yu och deras kollegor belyser frågan om katastrofal glömning, särskilt det som uppstår när flera modeller tränas i följd. Efter att ha modellerat detta problem matematiskt, forskarna introducerade en lösning som kunde övervinna den, eller åtminstone drastiskt minska dess inverkan.
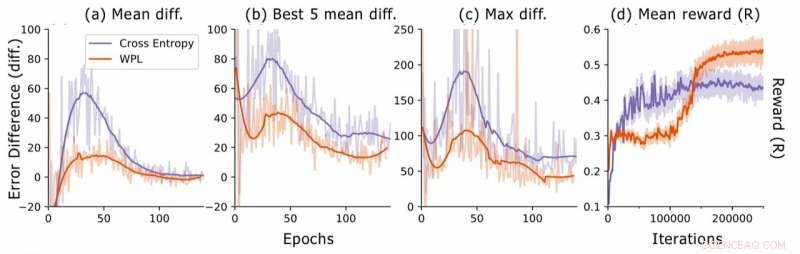
Felskillnad vid neuralarkitektursökning. För varje arkitektur, forskarna beräknar RNN -felskillnaderna err2 − err1, där err1 är felet direkt efter att ha tränat denna arkitektur och err2 den som trots allt är utbildade i den aktuella epoken. De plottar (a) den genomsnittliga skillnaden mellan alla urvalsmodeller, (b) den genomsnittliga skillnaden jämfört med de 5 modellerna med lägsta fel1, och (c) maxskillnaden för alla modeller. I (d), de plottar den genomsnittliga belöningen för de samplade arkitekturerna som en funktion av att träna iterationer. Även om WPL från början leder till lägre belöningar, på grund av en stor vikt α i ekvation (8), genom att minska det glömma det senare gör det möjligt för regulatorn att prova bättre arkitekturer, som indikeras av den högre belöningen i andra halvlek. Upphovsman:Benyahia, Yu et al.
"I att glömma flera modeller, vår vägledande princip var att tänka i formler och inte bara genom enkel intuition eller heuristik, "Benyahia och Yu sa." Vi tror starkt att detta "tänkande i formler" kan leda forskare till stora upptäckter. Det är därför för ytterligare forskning, vi strävar efter att tillämpa detta tillvägagångssätt på andra områden inom maskininlärning. Dessutom, Vi planerar att anpassa vår förlust till de senaste state-of-the-art autoML-metoderna för att visa dess effektivitet för att lösa viktdelningsproblemet som vi observerat. "
© 2019 Science X Network