Brookhaven Lab samarbetade med Columbia University, University of Edinburgh, och Intel för att optimera prestandan för en 144-nodig parallell dator byggd från Intels Xeon Phi-processorer och Omni-Path höghastighetskommunikationsnätverk. Datorn är installerad på Brookhaven's Scientific Data and Computing Center, som sett ovan med teknikingenjör Costin Caramarcu. Upphovsman:Brookhaven National Laboratory
Högpresterande datorer (HPC)-användningen av superdatorer och parallella bearbetningstekniker för att lösa stora beräkningsproblem-är till stor nytta i det vetenskapliga samfundet. Till exempel, forskare vid US Department of Energy's (DOE) Brookhaven National Laboratory förlitar sig på HPC för att analysera data som de samlar in på de stora experimentella anläggningarna på plats och för att modellera komplexa processer som skulle vara för dyra eller omöjliga att demonstrera experimentellt.
Moderna vetenskapliga tillämpningar, såsom att simulera partikelinteraktioner, kräver ofta en kombination av aggregerad datorkraft, höghastighetsnät för dataöverföring, stora mängder minne, och lagringsmöjligheter med hög kapacitet. Framsteg inom HPC -hårdvara och programvara behövs för att uppfylla dessa krav. Dator- och beräkningsvetare och matematiker i Brookhaven Labs Computational Science Initiative (CSI) samarbetar med fysiker, biologer, och andra domänforskare för att förstå sina dataanalysbehov och tillhandahålla lösningar för att påskynda den vetenskapliga upptäckten.
En HPC -branschledare
I årtionden, Intel Corporation har varit en av ledarna inom utveckling av HPC -teknik. 2016, företaget släppte Intel Xeon PhiTM-processorer (tidigare kodenamn "Knights Landing"), sin andra generationens HPC-arkitektur som integrerar många processorenheter (kärnor) per chip. Samma år, Intel släppte höghastighetskommunikationsnätverket Intel Omni-Path Architecture. För att 5, 000 till 100, 000 enskilda datorer, eller noder, i moderna superdatorer att arbeta tillsammans för att lösa ett problem, de måste snabbt kunna kommunicera med varandra samtidigt som nätverksförseningar minimeras.
Strax efter dessa utgåvor, Brookhaven Lab och RIKEN, Japans största omfattande forskningsinstitution, samlade sina resurser för att köpa en liten 144-nod parallell dator byggd från Xeon Phi-processorer och två oberoende nätverksanslutningar, eller skenor, med Intels Omni-Path-arkitektur. Datorn installerades vid Brookhaven Labs Scientific Data and Computing Center, som är en del av CSI.
En bild av Xeon Phi Knights Landing -processorn dör. En munstycke är ett mönster på en skiva av halvledande material som innehåller den elektroniska kretsen för att utföra en viss funktion. Kredit:Intel
När installationen är klar, fysikern Chulwoo Jung och CSI -beräkningsvetaren Meifeng Lin från Brookhaven Lab; teoretisk fysiker Christoph Lehner, en gemensam utnämnd vid Brookhaven Lab och University of Regensburg i Tyskland; Norman Kristus, Ephraim Gildor professor i beräkningsteoretisk fysik vid Columbia University; och teoretiska partikelfysikern Peter Boyle från University of Edinburgh arbetade i nära samarbete med mjukvaruutvecklare på Intel för att optimera nätverksprogramvaran för två vetenskapliga applikationer:partikelfysik och maskininlärning.
"CSI hade varit mycket intresserad av Intel Omni-Path Architecture sedan den tillkännagavs 2015, "sade Lin." Intels ingenjörers expertis var avgörande för att implementera mjukvaruoptimeringarna som gjorde att vi fullt ut kunde dra nytta av detta högpresterande kommunikationsnätverk för våra specifika applikationsbehov. "
Nätverkskrav för vetenskapliga tillämpningar
För många vetenskapliga tillämpningar, att köra en rang (ett värde som skiljer en process från en annan) eller möjligen några rader per nod på en parallell dator är mycket effektivare än att köra flera rader per nod. Varje rang körs vanligtvis som en oberoende process som kommunicerar med de andra leden med hjälp av ett standardprotokoll som kallas Message Passing Interface (MPI).
Till exempel, fysiker som försöker förstå hur det tidiga universum bildade kör komplexa numeriska simuleringar av partikelinteraktioner baserat på teorin om kvantkromodynamik (QCD). Denna teori förklarar hur elementära partiklar som kallas kvarker och gluoner interagerar för att bilda de partiklar vi direkt observerar, såsom protoner och neutroner. Fysiker modellerar dessa interaktioner med hjälp av superdatorer som representerar rymdets tre dimensioner och tidsdimensionen i ett fyrdimensionellt (4-D) gitter med lika fördelade punkter, liknar en kristall. Gitteret är uppdelat i mindre identiska delvolymer. För gitter -QCD -beräkningar, data måste utbytas vid gränserna mellan de olika delvolymerna. Om det finns flera led per nod, varje rang är värd för en annan 4-D undervolym. Således, att dela upp delvolymerna skapar fler gränser där data behöver utbytas och därför onödiga dataöverföringar som saktar ner beräkningarna.
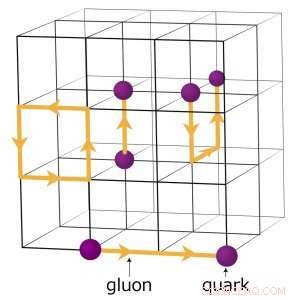
En schematisk bild av gallret för kvantkromodynamikberäkningar. Skärningspunkterna på rutnätet representerar kvarkvärden, medan linjerna mellan dem representerar gluonvärden. Upphovsman:Brookhaven National Laboratory
Programvaruoptimeringar för att främja vetenskap
För att optimera nätverksprogramvaran för en sådan beräkningsintensiv vetenskaplig applikation, laget fokuserade på att öka hastigheten på en enda rang.
"Vi fick koden för en enda MPI -rang att springa snabbare så att en spridning av MPI -led inte skulle behövas för att hantera den stora kommunikationsbelastningen som finns för varje nod, "förklarade Kristus.
Programvaran inom MPI -ranken utnyttjar den trådade parallellitet som finns på Xeon Phi -noder. Gängad parallellism avser samtidig körning av flera processer, eller trådar, som följer samma instruktioner medan du delar några datorer. Med den optimerade programvaran, laget kunde skapa flera kommunikationskanaler på en enda rang och driva dessa kanaler med olika trådar.
MPI-programvaran var nu inställd för att de vetenskapliga applikationerna skulle kunna köras snabbare och dra full nytta av Intel Omni-Path-kommunikationshårdvara. Men efter att ha implementerat programvaran, lagmedlemmarna stötte på en annan utmaning:i varje körning, några noder skulle oundvikligen kommunicera långsamt och hålla de andra tillbaka.
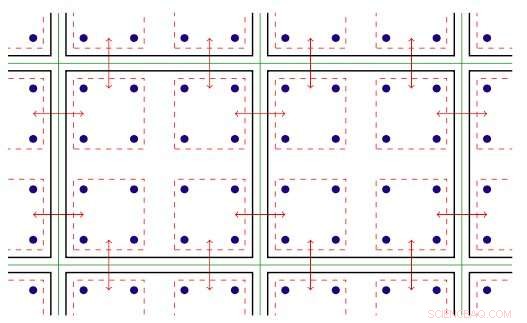
Tvådimensionell illustration av gängad parallellitet. Nyckel:gröna linjer separerar fysiska beräkningsnoder; svarta linjer skiljer MPI -led åt; röda linjer är kommunikationskontexten, med pilarna som anger kommunikation mellan noder eller minneskopior i en nod via Intel Omni-Path-hårdvaran. Upphovsman:Brookhaven National Laboratory
De spårade detta problem till hur Linux - operativsystemet som används av de flesta HPC -plattformar - hanterar minne. I standardläget, Linux delar upp minnet i små bitar som kallas sidor. Genom att konfigurera om Linux för att använda stora ("enorma") minnessidor, de löste problemet. Att öka sidstorleken innebär att färre sidor behövs för att kartlägga det virtuella adressutrymmet som en applikation använder. Som ett resultat, minnet kan nås mycket snabbare.
Med programförbättringarna, teammedlemmarna analyserade prestandan för Intel Omni-Path Architecture och Intel Xeon Phi-processorns noder installerade på Intels dubbelskena "Diamond" -kluster och Distributed Research Using Advanced Computing (DiRAC) single-rail-kluster i Storbritannien. För deras analys, de använde två olika klasser av vetenskapliga tillämpningar:partikelfysik och maskininlärning. För båda applikationskoderna, de uppnådde nästan trådlös hastighet-den teoretiska maximala hastigheten för dataöverföring. Denna förbättring representerar en ökning av nätverksprestanda som är mellan fyra och tio gånger högre än de ursprungliga koderna.
"På grund av det nära samarbetet mellan Brookhaven, Edinburgh, och Intel, dessa optimeringar gjordes tillgängliga över hela världen i en ny version av Intel Omni-Path MPI-implementeringen och ett bästa praxis för att konfigurera Linux-minneshantering, "sa Kristus." Faktorn på fem hastigheter i utförandet av fysikkoden på Xeon Phi -datorn vid Brookhaven Lab - och på University of Edinburghs nya, ännu större 800-nodiga Hewlett Packard Enterprise "hyperkub" -dator-används nu bra i pågående studier av grundläggande frågor inom partikelfysik. "