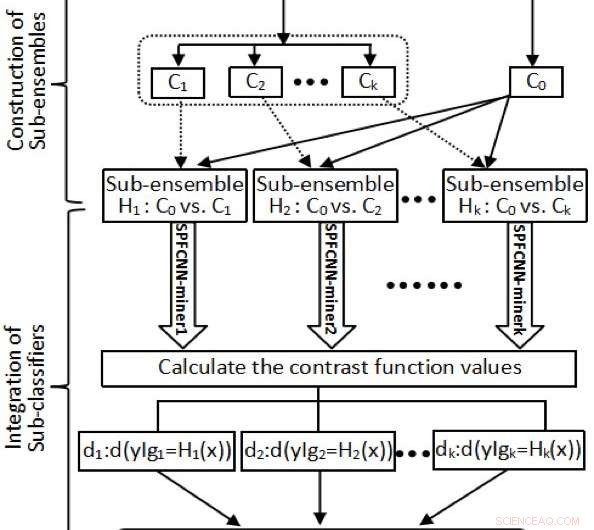
Flödesschemat om MLF. Kredit:Zhao et al.
Forskare vid Chongqing University i Kina har nyligen utvecklat en kostnadskänslig klassificerare för meta-lärande som kan användas när den tillgängliga träningsdatan är högdimensionell eller begränsad. Deras klassificerare, kallas SPFCNN-Miner, presenterades i en artikel publicerad i Elsevier's Framtida generationens datorsystem .
Även om maskininlärningsklassificerare har visat sig vara effektiva i en mängd olika uppgifter, för att uppnå optimala resultat, de kräver ofta en stor mängd träningsdata. När data är högdimensionell, begränsad eller obalanserad, de flesta klassificeringsmetoder kan inte uppnå en tillfredsställande prestanda. I deras studie, teamet av forskare vid Chongqing University satte sig för att bättre förstå dessa datarelaterade utmaningar och utveckla en klassificerare som kan övervinna dem.
"Vi använde siamesiska nätverk som är lämpliga för få-shot-inlärning där lite data är tillgänglig för att lära sig högdimensionell och begränsad data, och tillämpa idén om att kombinera "grunda" och "djupa" tillvägagångssätt för att designa parallella siamesiska nätverk som bättre kan extrahera enkla eller komplexa funktioner från en mängd olika datauppsättningar, "Linchang Zhao, en av forskarna som genomförde studien, berättade för TechXplore. "Huvudmålen med vår studie var att lösa problemet med obalanserad dataklass och få bästa möjliga klassificeringsresultat på sådana datamängder."
Zhao och hans kollegor utvecklade ett siamesiskt parallellkopplat neuralt nätverk (SPFCNN) och tillämpade det på problem med klassobalanserad datadistribution. Att förvandla deras kostnadsokänsliga SPFCNN till ett kostnadskänsligt tillvägagångssätt, de använde en teknik som kallas "kostnadskänslig inlärning."
Först, forskarna delade upp majoritetsgruppen i en datauppsättning baserad på inre produkttransformerade egenskaper. Detta säkerställde att storleken på varje undergrupp i en majoritetsgrupp var nära minoritetsgruppens. Dessutom, de strukturerade några underensembler med hjälp av minoritetsgruppen mot varje erhållen partition.
"Nästa, vi ansökte n SPFCNN-gruvarbetare till alla underensembler, varje provpunkt x j kan uttryckas genom dess motsvarande mått(d j1 , …, d jn ), varje underklassificerare kan omvandlas till ett mått på kontrastiv förlustfunktion genom att anpassa SPFCNN, " förklarade Zhao. "Äntligen, n SPFCNN-gruvarbetare integrerades som en slutlig klassificerare enligt värdena för kontrastiv funktion."
Tillvägagångssättet som Zhao och hans kollegor har utarbetat har många fördelar som skiljer det från andra klassificerare. Först, deras Meta-Learner Function (MLF) kan användas för att partitionera majoritetsgruppen i en datauppsättning baserat på de inre produktens transformerade funktioner, vilket resulterar i att den transformerade datan innehåller information relaterad till avstånd och vinklar mellan objekt i minoritets- och majoritetsgruppen.
"Vinklarna mellan majoritetsgruppen och minoritetsgruppen kan ses som ett uttryck för relaterade platser och representerar sedan den relaterade riktningen för majoritetsgruppen till minoritetsgruppen, " förklarade Zhao.
En ytterligare fördel med den nya SPFCNN-Miner-klassificeraren är att, som andra siamesiska nätverk, det kan effektivt extrahera funktioner på högsta nivå från en liten mängd prover för få-shot-inlärning. Dessutom, parallella siamesiska nätverk är designade för att adaptivt lära sig enkla eller komplexa funktioner från olika dimensioner av dataattribut.
Zhao och hans kollegor utvärderade deras tillvägagångssätt i en serie beräkningstest, använder både kostnadsokänsliga och kostnadskänsliga versioner av SPFCNN-klassificeraren. De fann att det kostnadskänsliga tillvägagångssättet överträffade alla klassificerare de jämförde det med.
"De experimentella resultaten visar att vår SPFCNN är ett konkurrenskraftigt tillvägagångssätt och kan förbättra klassificeringsprestandan mer signifikant jämfört med de benchmarkerade metoderna, " sa Zhao. "Vi fann att prestandan för vår modell inte förbättrades när urvalsstorleken ökade, men påverkades kraftigt av obalansgraden. Prestandan som erhålls genom att införliva det kostnadskänsliga lärandet i vår modell är mer stabil."
Studien utförd av Zhao och hans kollegor introducerar en ny metod som kan användas av forskare för att förbättra prestandan hos klassificerare när data är begränsade eller obalanserade. Dessutom, deras resultat tyder på att balansering av antalet positiva och negativa prover kan vara effektivare än att generera ett större antal konstgjorda prover. Till exempel, deras tillvägagångssätt kan integrera olika felklassificeringskostnader när det slutför en klassificeringsuppgift, vilket gör den mer robust än andra tekniker som används för att ta itu med obalanserade datarelaterade problem.
"I framtiden, vi planerar att använda tekniker som slumpmässiga promenadmatriser, cirkulerande viktdelning och Huffman-kodning för att komprimera vår modell, och den löst anslutna tekniken eller parallell beskärnings-kvantiseringsmetoden kommer att användas för att lätta den föreslagna SPFCNN-modellen, " sa Zhao.
© 2019 Science X Network