Kredit:Petr Kratochvil/public domain
I en värld av djupa förfalskningar och alltför mänskligt naturligt språk AI, forskare vid Harvard John A. Paulson School of Engineering and Applied Sciences (SEAS) och IBM Research frågade:Finns det ett bättre sätt att hjälpa människor att upptäcka AI-genererad text?
Den frågan ledde Sebastian Gehrmann, en doktorsexamen kandidat på SEAS, och Hendrik Strobelt, en forskare vid IBM, att utveckla en statistisk metod, tillsammans med ett interaktivt verktyg med öppen åtkomst, för att upptäcka AI-genererad text.
Generatorer av naturliga språk är tränade på tiotals miljoner onlinetexter och efterliknar mänskligt språk genom att förutsäga de ord som oftast kommer efter varandra. Till exempel, orden "har" "är" och "var" är statiskt sett mest sannolikt att komma efter ordet "jag".
Att använda den idén, Gehrmann och Strobelt utvecklade en metod som, snarare än att identifiera fel i text, identifierar text som är för förutsägbar.
"Tanken vi hade är att när modellerna blir bättre och bättre, de går från definitivt värre än människor, som är detekterbar, lika bra som eller bättre än människor, som kan vara svåra att upptäcka med konventionella metoder, sa Gehrmann.
"Innan, du kunde se på alla misstag att text var maskingenererad, " sa Strobelt. "Nu, det är inte längre misstagen utan snarare användningen av högst sannolika (och lite tråkiga) ord som ropar ut maskingenererad text. Med detta verktyg, människor och AI kan arbeta tillsammans för att upptäcka falsk text."
Gehrmann och Strobelt kommer att presentera sin forskning, som var medförfattare av Alexander Rush, Associate in Computer Science på SEAS, vid Association for Computational Linguistics (ACL) konferens den 28 juli–2 augusti.
Gehrmann och Strobelts metod, känd som GLTR, är baserad på en modell som utbildats på 45 miljoner texter från webbplatser - den offentliga versionen av OpenAI -modellen, GPT-2. Eftersom den använder GPT-2 för att upptäcka genererad text, GLTR fungerar bäst mot GPT-2, men klarar sig också bra mot andra modeller.
Så här fungerar det:
Om du matar in en textpassning i verktyget, det markerar texten i grönt, gul, röd eller lila, varje färg anger ordets förutsägbarhet i sammanhanget för ordet före det. Grön betyder att ordet var mycket förutsägbart, gul, måttligt förutsägbar, rött inte särskilt förutsägbart och lila betyder att modellen inte alls hade förutsagt ordet.
Så ett stycke text genererat av GPT-2 kommer att se ut så här:

Kredit:Harvard University
Att jämföra, det här är en riktig New York Times artikel:
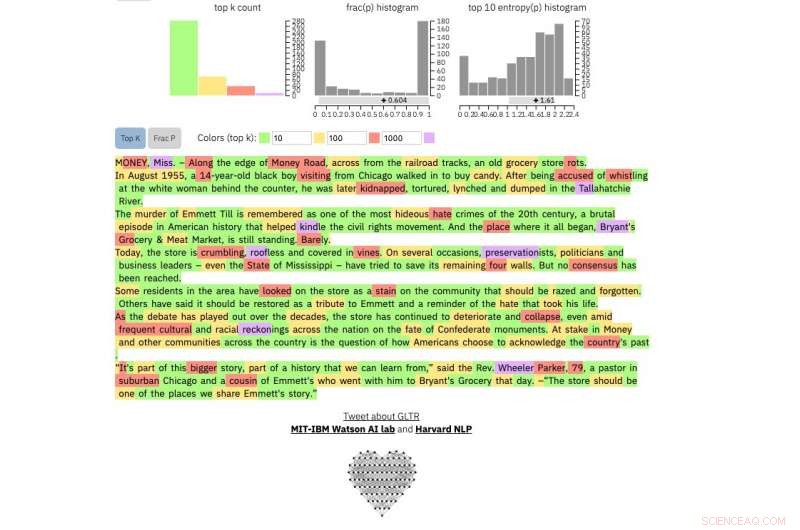
Kredit:Harvard University
Och det här är ett utdrag från den utan tvekan mest oförutsägbara mänskliga texten som någonsin skrivits, James Joyces Finnegans Wake :
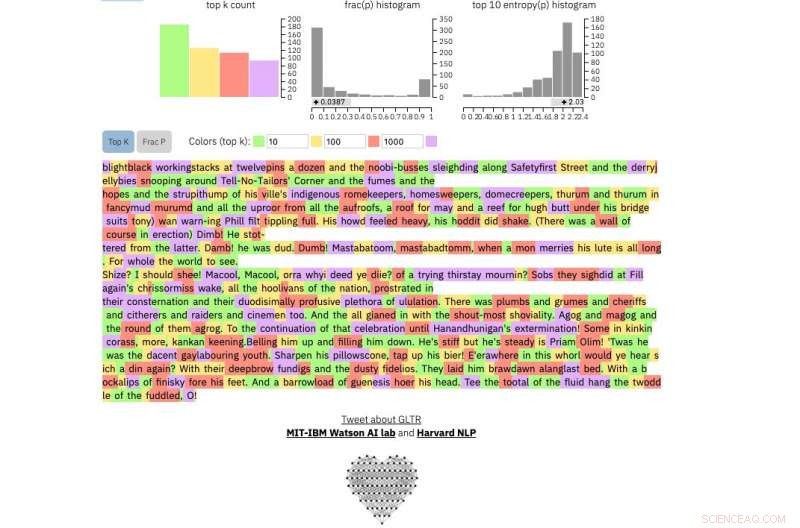
Kredit:Harvard University
Metoden är inte avsedd att ersätta människor för att identifiera falska texter utan snarare att stödja mänsklig intuition och förståelse. Forskarna testade modellen med en grupp studenter i en SEAS Computer Science-klass.
Utan modellen, eleverna kunde identifiera cirka 50 procent av AI-genererad text. Med färgöverlägget, eleverna kunde identifiera 72 procent.
Gehrmann och Strobelt säger att med lite träning och erfarenhet av programmet, antalet kan förbättras ytterligare.
"Vårt mål är att skapa samarbetssystem för mänskliga och AI, ", sade Gehrmann. "Denna forskning är inriktad på att ge människor mer information så att de kan fatta ett välgrundat beslut om vad som är sant och vad som är falskt."