Forskarna överväger problemet med navigering från en startposition till en målposition. Deras tillvägagångssätt (WayPtNav) består av en inlärningsbaserad uppfattningsmodul och en dynamisk modellbaserad planeringsmodul. Perceptionsmodulen förutsäger en waypoint baserat på den aktuella förstapersons RGB-bildobservationen. Denna waypoint används av den modellbaserade planeringsmodulen för att designa en styrenhet som smidigt reglerar systemet till denna waypoint. Denna process upprepas för nästa bild tills roboten når målet. Kredit:Bansal et al.
Forskare vid UC Berkeley och Facebook AI Research har nyligen utvecklat ett nytt tillvägagångssätt för robotnavigering i okända miljöer. Deras tillvägagångssätt, presenterad i ett papper som för publicerats på arXiv, kombinerar modellbaserad kontrollteknik med inlärningsbaserad perception.
Utvecklingen av verktyg som gör det möjligt för robotar att navigera i omgivande miljöer är en viktig och pågående utmaning inom robotteknik. Under de senaste decennierna, forskare har försökt ta itu med detta problem på en mängd olika sätt.
Kontrollforskaren har i första hand undersökt navigering för en känd agent (eller ett system) inom en känd miljö. I dessa fall, en dynamikmodell av agenten och en geometrisk karta över miljön den kommer att navigera är tillgängliga, Därför kan optimala kontrollscheman användas för att erhålla jämna och kollisionsfria banor för roboten att nå en önskad plats.
Dessa scheman används vanligtvis för att styra ett antal verkliga fysiska system, som flygplan eller industrirobotar. Dock, dessa tillvägagångssätt är något begränsade, eftersom de kräver tydlig kunskap om miljön som ett system kommer att navigera i. I lärande forskarsamhälle, å andra sidan, robotnavigering studeras i allmänhet för en okänd agent som utforskar en okänd miljö. Detta innebär att ett system skaffar policyer för att direkt mappa inbyggda sensoravläsningar för att styra kommandon på ett heltäckande sätt.
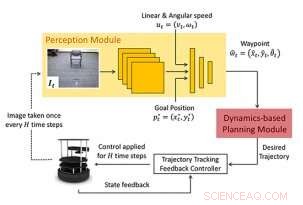
Föreslagna ramar:Det nya tillvägagångssättet för navigering består av en inlärningsbaserad perceptionsmodul och en dynamikmodellbaserad planeringsmodul. Perceptionsmodulen består av en CNN som matar ut ett önskat nästa tillstånd eller waypoint. Denna waypoint används av den modellbaserade planeringsmodulen för att designa en styrenhet för att smidigt reglera systemet till waypointen. Upphovsman:Bansal et al.
Dessa tillvägagångssätt kan ha flera fördelar, eftersom de gör det möjligt att lära sig policyer utan någon som helst kunskap om systemet och miljön det kommer att navigera i. Ändå, Tidigare studier tyder på att dessa tekniker inte generaliserar bra över olika medel. Dessutom, Att lära sig sådana policyer kräver ofta ett stort antal utbildningsexempel.
"I det här pappret, vi studerar robotnavigering i statiska miljöer under antagandet om perfekt robottillståndsmätning, " skrev forskarna i sin uppsats. "Vi gör den avgörande observationen att de mest intressanta problemen involverar ett känt system i en okänd miljö. Denna observation motiverar utformningen av ett faktoriserat tillvägagångssätt som använder lärande för att tackla okända miljöer och utnyttjar optimal kontroll med hjälp av känd systemdynamik för att producera mjuk rörelse."
Teamet av forskare vid UC Berkeley och Facebook tränade en konvolutionellt neuralt nätverk (CNN) baserad modell på högnivåpolicyer, som använder aktuella RGB-bildobservationer för att producera en sekvens av mellanliggande tillstånd, eller 'waypoints'. Dessa waypoints leder till slut en robot till dess önskade plats efter en kollisionsfri väg, i tidigare okända miljöer.
Deras tillvägagångssätt, dubbad waypointbaserad navigering (WayPtNav), kopplar i huvudsak modellbaserade kontrolltekniker med inlärningsbaserad perception. Den inlärningsbaserade uppfattningsmodulen genererar waypoints, som styr roboten till sin målplats via en kollisionsfri väg. Den modellbaserade planeraren, å andra sidan, använder dessa waypoints för att generera en smidig och dynamiskt genomförbar bana, som sedan exekveras på systemet med hjälp av återkopplingskontroll.
Forskarna utvärderade sitt tillvägagångssätt på en hårdvarutestbädd, kallas TurtleBot2. Deras tester samlade mycket lovande resultat, med WayPtNav som möjliggör navigering i röriga och dynamiska miljöer, samtidigt som de överträffar en end-to-end-inlärningsmetod.
"Våra experiment i simulerade verkliga röriga miljöer och på ett verkligt markfordon visar att det föreslagna tillvägagångssättet kan nå målplatser mer tillförlitligt och effektivt i nya miljöer jämfört med ett rent end-to-end inlärningsbaserat alternativ, " skrev forskarna.
Det nya tillvägagångssättet som presenteras av detta team av forskare kan förbättra robotnavigering i nya inomhusmiljöer. Framtida studier kan försöka förbättra WayPtNav ytterligare, ta itu med några av dess nuvarande begränsningar.
"Vårt föreslagna tillvägagångssätt förutsätter perfekt uppskattning av robottillstånd och använder en rent reaktiv policy, "förklarade forskarna." Dessa antaganden och val är kanske inte optimala, speciellt för långdistansuppgifter. Att införliva rumsligt eller visuellt minne för att hantera dessa begränsningar skulle vara givande framtida riktningar. "
© 2019 Science X Network