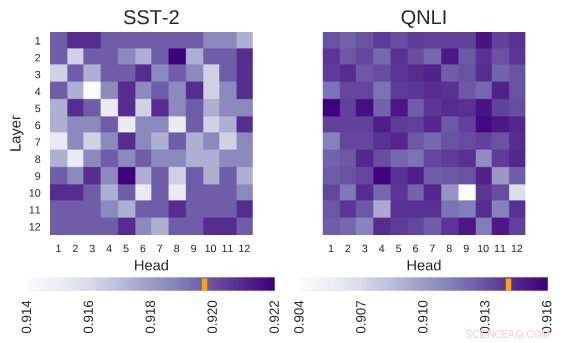
Undersökt BERT-arkitektur har arkitekturen av 12 lager gånger 12 huvuden. Varje cell i denna figur visar prestanda för BERT om motsvarande huvud är avstängt. Mörkare färger indikerar högre prestanda, och vita celler indikerar huvuden utan vilka BERTs prestanda minskar. Stanford Sentiment Treebank (SST-2):Det finns flera huvuden som kodar information som är nödvändig för uppgiften. Question Natural Language Inference (QNLI):De flesta huvuden förbättrar den övergripande prestandan när de är avstängda. Kredit:Kovaleva et al.
BERT, en transformatorbaserad modell som kännetecknas av en unik självuppmärksamhetsmekanism, har hittills visat sig vara ett giltigt alternativ till återkommande neurala nätverk (RNN) för att ta itu med naturliga språkbehandlingsuppgifter (NLP). Trots deras fördelar, än så länge, väldigt få forskare har studerat dessa BERT-baserade arkitekturer på djupet, eller försökte förstå orsakerna bakom effektiviteten av deras självuppmärksamhetsmekanism.
Medveten om denna lucka i litteraturen, forskare vid University of Massachusetts Lowells Text Machine Lab for Natural Language Processing har nyligen genomfört en studie som undersöker tolkningen av självuppmärksamhet, den viktigaste komponenten i BERT-modellerna. Ledande utredare och seniorförfattare för denna studie var Olga Kovaleva och Anna Rumshisky, respektive. Deras papper förpublicerade på arXiv och kommer att presenteras på EMNLP 2019-konferensen, föreslår att en begränsad mängd uppmärksamhetsmönster upprepas över olika BERT-delkomponenter, antyder deras överparameterisering.
"BERT är en ny modell som gjorde ett genombrott i NLP -gemenskapen, ta över topplistorna över flera uppgifter. Inspirerad av den senaste trenden, vi var nyfikna på att undersöka hur och varför det fungerar, " forskarteamet berättade för TechXplore via e-post. "Vi hoppades hitta ett samband mellan självuppmärksamhet, BERT:s huvudsakliga underliggande mekanism, och språkligt tolkbara relationer inom den givna inmatningstexten."
BERT-baserade arkitekturer har en lagerstruktur, och vart och ett av dess lager består av så kallade "huvuden". För att modellen ska fungera, vart och ett av dessa huvuden är tränade att koda en specifik typ av information, därmed bidra till den övergripande modellen på sitt sätt. I deras studie, forskarna analyserade informationen som kodats av dessa enskilda huvuden, med fokus på både kvantitet och kvalitet.
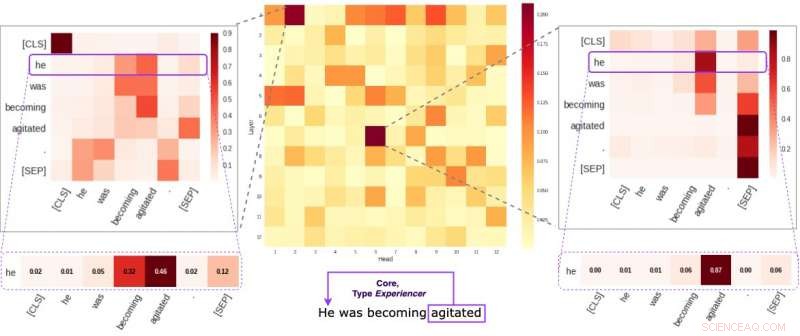
Varje cell i mittenfiguren återspeglar hur enskilda huvuden uppmärksammar de centrala semantiska länkarna inom en given mening (i genomsnitt). Vi identifierade två specifika huvuden som tenderar att koda semantisk information mer än de andra. De två bilderna på sidorna visar hur dessa två huvuden tilldelar vikter till enskilda ord inom en slumpmässig mening i vår datauppsättning. Kredit:Kovaleva et al.
"Vår metod fokuserade på att undersöka individuella huvuden och de mönster av uppmärksamhet de gav, " förklarade forskarna. "I huvudsak, vi försökte svara på frågan:"När BERT kodar ett enda ord i en mening, uppmärksammar den de andra orden på ett sätt som är meningsfullt för människor?"
Forskarna genomförde en serie experiment med både grundläggande förtränade och finjusterade BERT-modeller. Detta gjorde det möjligt för dem att samla många intressanta observationer relaterade till självuppmärksamhetsmekanismen som ligger i kärnan i BERT-baserade arkitekturer. Till exempel, de observerade att en begränsad uppsättning uppmärksamhetsmönster ofta upprepas över olika huvuden, vilket tyder på att BERT-modeller är överparametriserade.
"Vi fann att BERT tenderar att vara överparametriserad, och det finns mycket redundans i informationen den kodar, ", sa forskarna. "Detta betyder att det beräkningsmässiga fotavtrycket för att träna en så stor modell inte är väl motiverat."
Ett ytterligare intressant fynd som samlats in av forskarteamet vid University of Massachusetts Lowell är att beroende på uppgiften som en BERT-modell tar, slumpmässigt att stänga av några av dess huvuden kan leda till en förbättring, snarare än en nedgång, i prestanda. Dessutom, forskarna identifierade inte några språkliga mönster som är av särskild betydelse för att bestämma BERT:s prestation i nedströmsuppgifter.
"Att göra djupinlärning tolkbart är viktigt för både grundläggande och tillämpad forskning, och vi kommer att fortsätta arbeta i denna riktning, " sa forskarna. "Nya BERT-baserade modeller har nyligen släppts, och vi planerar att utöka vår metod för att undersöka dem också."
© 2019 Science X Network