Roboten samlar in slumpmässiga interaktionsdata som ska användas för utbildning av en representation och som off-policy data för RL. Upphovsman:Nair et al.
Förstärkningsinlärning (RL) har hittills visat sig vara en effektiv teknik för att träna artificiella agenter i enskilda uppgifter. Dock, när det gäller utbildning av flerfunktionsrobotar, som ska kunna utföra en mängd olika uppgifter som kräver olika färdigheter, de flesta befintliga RL -metoder är långt ifrån idealiska.
Med detta i åtanke, ett team av forskare vid UC Berkeley har nyligen utvecklat ett nytt RL -tillvägagångssätt som kan användas för att lära robotar att anpassa sitt beteende utifrån den uppgift som de presenteras med. Detta tillvägagångssätt, beskrivs i en uppsats som för publicerats om arXiv och presenterades vid årets konferens om robotinlärning, tillåter robotar att automatiskt komma med beteenden och öva dem över tid, lära sig vilka som kan utföras i en given miljö. Robotarna kan sedan återanvända den kunskap de förvärvat och tillämpa den på nya uppgifter som mänskliga användare ber dem att slutföra.
"Vi är övertygade om att data är nyckeln för robotmanipulation och för att få tillräckligt med data för att lösa manipulation på ett generellt sätt, robotar måste själva samla in data, "Ashvin Nair, en av forskarna som genomförde studien, berättade TechXplore. "Detta är vad vi kallar självövervakad robotinlärning:En robot som aktivt kan samla sammanhängande prospekteringsdata och på egen hand förstå om den har lyckats eller misslyckats med uppgifter för att lära sig nya färdigheter."
Det nya tillvägagångssättet som utvecklats av Nair och hans kollegor bygger på ett målkonditionerat RL-ramverk som presenterades i deras tidigare arbete. I denna tidigare studie, forskarna introducerade målsättning i ett latent utrymme som en teknik för att träna robotar på färdigheter som att skjuta föremål eller öppna dörrar direkt från pixlar, utan behov av en extern belöningsfunktion eller statlig uppskattning.
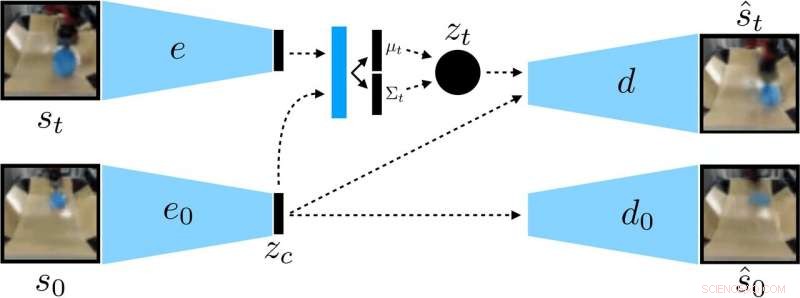
Forskarna utbildade en kontextkonditionerad VAE på data, som avlägsnar sammanhang som förblir konstant under en utrullning. Upphovsman:Nair et al.
"I vårt nya arbete, vi fokuserar på generalisering:Hur kan vi göra självkontrollerat lärande för att inte bara lära oss en enda färdighet, men också kunna generalisera till visuell mångfald medan du utför den färdigheten? "sa Nair." Vi tror att förmågan att generalisera till nya situationer kommer att vara nyckeln till bättre robotmanipulation. "
I stället för att träna en robot på många färdigheter individuellt, den villkorliga målsättande modellen som föreslås av Nair och hans kollegor är utformad för att sätta specifika mål som är genomförbara för roboten och som är i linje med dess nuvarande tillstånd. Väsentligen, algoritmen de utvecklade lär sig en specifik typ av representation som skiljer saker som roboten kan styra från de saker den inte kan styra.
När de använder sin självövervakade inlärningsmetod, roboten samlar inledningsvis data (dvs. en uppsättning bilder och handlingar) genom att slumpmässigt interagera med sin omgivande miljö. Senare, den tränar en komprimerad representation av denna data som konverterar bilder till lågdimensionella vektorer som implicit innehåller information såsom objektens position. Istället för att uttryckligen få veta vad man ska lära sig, denna representation förstår automatiskt begrepp via sitt komprimeringsmål.
"Med hjälp av den inlärda representationen, roboten övar på att nå olika mål och tränar en policy med hjälp av förstärkningslärande, "Nair förklaras." Den komprimerade representationen är nyckeln för denna övningsfas:den används för att mäta hur nära två bilder är så att roboten vet när den har lyckats eller misslyckats, och det används för att prova mål för roboten att öva. Vid testtiden, den kan sedan matcha en målbild som specificeras av en människa genom att utföra sin inlärda politik. "
Forskarna utvärderade effektiviteten av deras tillvägagångssätt i en serie experiment där ett artificiellt medel manipulerade tidigare osynliga objekt i en miljö som skapats med hjälp av MuJuCo -simuleringsplattformen. Intressant, deras träningsmetod gjorde det möjligt för robotagenten att automatiskt skaffa sig färdigheter som den sedan kunde gälla för nya situationer. Mer specifikt, roboten kunde manipulera en mängd olika objekt, generaliserande manipulationsstrategier som den tidigare förvärvat till nya objekt som den inte hade stött på under träning.
"Vi är mest glada över två resultat från detta arbete, "Sa Nair." Först, vi fann att vi kan träna en politik för att skjuta objekt i den verkliga världen på cirka 20 objekt, men den inlärda politiken kan faktiskt också driva andra objekt. Denna typ av generalisering är huvudlöftet om djupinlärningsmetoder, och vi hoppas att detta är början på mycket mer imponerande former av generalisering som kommer. "
Anmärkningsvärt, i deras experiment, Nair och hans kollegor kunde träna en policy från en fast uppsättning interaktioner utan att behöva samla in en stor mängd data online. Detta är en viktig prestation, eftersom datainsamling för robotforskning i allmänhet är mycket dyr, och att kunna lära sig färdigheter från fasta datamängder gör deras tillvägagångssätt mycket mer praktiskt.
I framtiden, modellen för självövervakat lärande som utvecklats av forskarna kan hjälpa utvecklingen av robotar som kan hantera en mängd olika uppgifter utan att träna på en stor uppsättning färdigheter individuellt. Sålänge, Nair och hans kollegor planerar att fortsätta testa deras tillvägagångssätt i simulerade miljöer, samtidigt som man undersöker hur det kan förbättras ytterligare.
"Vi bedriver nu några olika forskningsområden, inklusive att lösa uppgifter med en mycket större mängd visuell mångfald, samt att lösa en stor uppsättning uppgifter samtidigt och se om vi kan använda lösningen på en uppgift för att påskynda lösningen av nästa uppgift, "Sa Nair.
© 2019 Science X Network