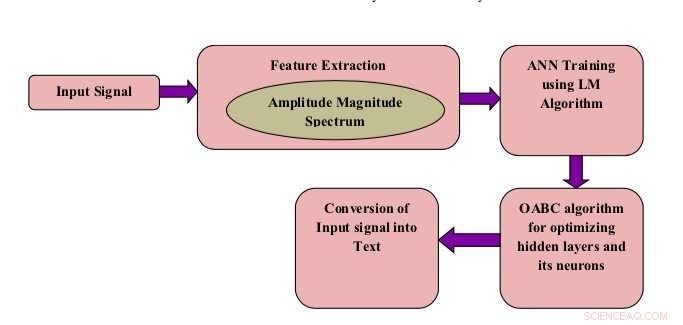
Blockschema över föreslagen modell. Kredit:Shukla &Jain.
Under det senaste decenniet eller så, framsteg inom maskininlärning har banat väg för utvecklingen av allt mer avancerade taligenkänningsverktyg. Genom att analysera ljudfiler med mänskligt tal, dessa verktyg kan lära sig att identifiera ord och fraser på olika språk, konvertera dem till ett maskinläsbart format.
Medan flera maskininlärningsbaserade modeller har uppnått lovande resultat på taligenkänningsuppgifter, de presterar inte alltid bra på alla språk. Till exempel, när ett språk har ett ordförråd med många liknande klingande ord, prestanda för taligenkänningssystem kan minska avsevärt.
Forskare vid Mahatma Gandhi Missions College of Engineering &Technology och Jaypee Institute of Information Technology, i Indien, har utvecklat ett taligenkänningssystem för att hantera detta problem. Detta nya system, presenteras i en artikel publicerad i Springer Link's International Journal of Speech Technology , kombinerar ett artificiellt neuralt nätverk (ANN) med en optimeringsteknik som kallas opposition artificiell bikoloni (OABC).
"I det här arbetet, standardstrukturen för ANN:er är omdesignad med Levenberg-Marquardt-algoritmen för att hämta en optimal förutsägelsehastighet med noggrannhet, " skrev forskarna i sin uppsats. "De dolda skikten och nervcellerna i de dolda skikten optimeras ytterligare med hjälp av oppositionstekniken för optimering av konstgjorda bikolonier."
En unik egenskap hos systemet som utvecklats av forskarna är att det använder en OABC-optimeringsalgoritm för att optimera ANN:s lager och artificiella neuroner. Som namnet antyder, Algoritmer för artificiella bikolonier (ABC) är utformade för att simulera honungsbins beteende för att hantera en mängd olika optimeringsproblem.
"Rent generellt, optimeringsalgoritmer initierar slumpmässigt lösningarna i den matchande domänen, " förklarade forskarna i sin uppsats. "Men den här lösningen kan ligga i motsatt riktning mot den bästa lösningen, vilket ökar beräkningsoverheaden avsevärt. Därför kallas denna oppositionsbaserade initiering som OABC."
Systemet som utvecklats av forskarna betraktar enskilda ord som uttalas av olika människor som en inmatad talsignal. Senare, det extraherar så kallade amplitudmodulations (AM) spektrogramfunktioner, som i huvudsak är ljudspecifika egenskaper.
Funktionerna som extraheras av modellen används sedan för att träna ANN att känna igen mänskligt tal. Efter att den har tränats på en stor databas med ljudfiler, ANN lär sig att förutsäga isolerade ord i nya prover av mänskligt tal.
Forskarna testade sitt system på en serie ljudklipp från mänskligt tal och jämförde det med mer konventionella taligenkänningstekniker. Deras teknik överträffade alla andra metoder, uppnå anmärkningsvärda precisionspoäng.
"Känsligheten, specificitet, och noggrannheten för den föreslagna metoden är 90,41 procent, 99,66 procent och 99,36 procent, respektive, vilket är bättre än alla befintliga metoder, " skrev forskarna i sin uppsats.
I framtiden, taligenkänningssystemet skulle kunna användas för att uppnå mer effektiv kommunikation mellan människa och maskin i en mängd olika miljöer. Dessutom, tillvägagångssättet de använde för att utveckla systemet skulle kunna inspirera andra team att designa liknande modeller, som kombinerar ANN:er och OABC-optimeringstekniker.
© 2019 Science X Network