När framtiden är osäker, framtida belöning kan representeras som en sannolikhetsfördelning. vissa möjliga framtider är bra (grönt), andra är dåliga (röda). Distributionsförstärkningsinlärning kan lära sig om denna fördelning över förutsagda belöningar genom en variant av TD-algoritmen. Kreditera: Natur (2020). DOI:10.1038/s41586-019-1924-6
Ett team av forskare från DeepMind, University College och Harvard University har funnit att lärdomar i att tillämpa inlärningstekniker på AI-system kan hjälpa till att förklara hur belöningsvägar fungerar i hjärnan. I deras papper publicerad i tidskriften Natur , gruppen beskriver att jämföra distributionsförstärkningsinlärning i en dator med dopaminbearbetning i mushjärnan, och vad de lärde sig av det.
Tidigare forskning har visat att dopamin som produceras i hjärnan är involverat i belöningsbearbetning - det produceras när något bra händer, och dess uttryck resulterar i känslor av njutning. Vissa studier har också föreslagit att nervcellerna i hjärnan som svarar på närvaron av dopamin alla svarar på samma sätt - en händelse får en person eller en mus att må bra eller dåligt. Andra studier har föreslagit att neuronal respons är mer av en gradient. I denna nya ansträngning, forskarna har hittat bevis som stöder den senare teorin.
Distributionsförstärkningsinlärning är en typ av maskininlärning baserad på förstärkning. Det används ofta när man designar spel som Starcraft II eller Go. Den håller reda på bra drag kontra dåliga drag och lär sig att minska antalet dåliga drag, förbättra dess prestanda ju mer den spelar. Men sådana system behandlar inte alla bra och dåliga drag lika – varje drag viktas när det registreras och vikterna är en del av de beräkningar som används när man gör framtida dragval.
Forskare har noterat att människor verkar använda en liknande strategi för att förbättra sin spelnivå, också. Forskarna i London misstänkte att likheterna mellan AI-systemen och hur hjärnan utför belöningsbearbetning sannolikt var liknande, också. För att ta reda på om de var korrekta, de utförde experiment med möss. De satte in enheter i sina hjärnor som kunde registrera svar från individuella dopaminneuroner. Mössen tränades sedan för att utföra en uppgift där de fick belöningar för att de svarade på ett önskat sätt.
Musneuronsvaren avslöjade att de inte alla svarade på samma sätt, som tidigare teori hade förutspått. Istället, de svarade på tillförlitligt olika sätt – en indikation på att nivåerna av nöje som mössen upplevde var mer av en gradient, som laget hade förutspått.
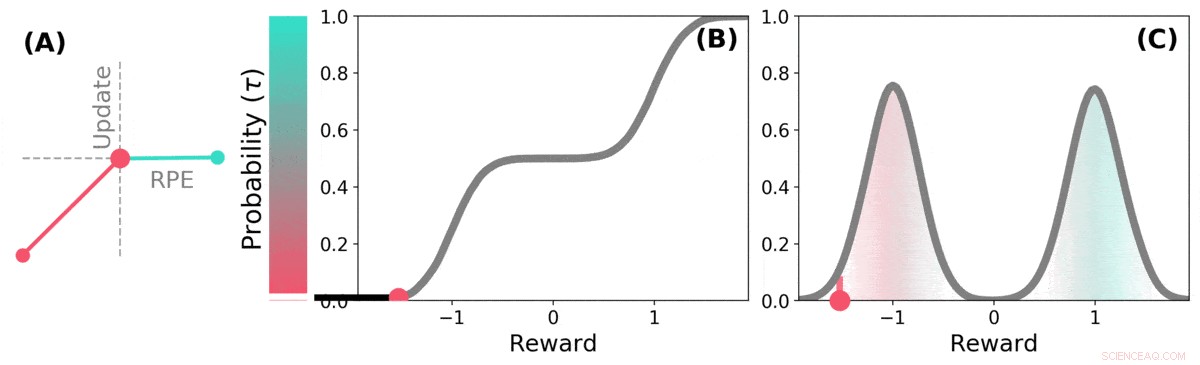
Distributions-TD lär sig värdeuppskattningar för många olika delar av fördelningen av belöningar. vilken del en viss uppskattning omfattar bestäms av typen av asymmetrisk uppdatering som tillämpas på den uppskattningen. (a) En "pessimistisk" cell skulle förstärka negativa uppdateringar och ignorera positiva uppdateringar, en "optimistisk" cell skulle förstärka positiva uppdateringar och ignorera negativa uppdateringar. (b) Detta resulterar i en mångfald av pessimistiska eller optimistiska värdeuppskattningar, visas här som poäng längs den kumulativa fördelningen av belöningar, som fångar (c) Den fullständiga fördelningen av belöningar. Kreditera: Natur (2020). DOI:10.1038/s41586-019-1924-6
© 2020 Science X Network