Kredit:Massachusetts Institute of Technology
För alla framsteg som forskare har gjort med maskininlärning för att hjälpa oss att göra saker som crunch -nummer, köra bil och upptäcka cancer, vi tänker sällan på hur energikrävande det är att underhålla de massiva datacenter som möjliggör sådant arbete. Verkligen, en studie från 2017 förutspådde att senast 2025, Internetanslutna enheter skulle använda 20 procent av världens elektricitet.
Maskininlärningens ineffektivitet är delvis en funktion av hur sådana system skapas. Neurala nätverk utvecklas vanligtvis genom att generera en initial modell, justera några parametrar, försöker igen, och sedan skölja och upprepa. Men detta tillvägagångssätt innebär att betydande tid, energi och datorresurser läggs på ett projekt innan någon vet om det verkligen kommer att fungera.
MIT doktorand Jonathan Rosenfeld liknar det med 1600-talets forskare som försöker förstå gravitationen och planeternas rörelse. Han säger att sättet vi utvecklar maskininlärningssystem idag – i avsaknad av sådana förståelser – har begränsad prediktiv kraft och är därför väldigt ineffektivt.
"Det finns fortfarande inte ett enhetligt sätt att förutsäga hur väl ett neuralt nätverk kommer att prestera med tanke på vissa faktorer som modellens form eller mängden data den har tränats på, säger Rosenfeld, som nyligen utvecklat ett nytt ramverk om ämnet med kollegor vid MIT:s datavetenskap och artificiell intelligens Lab (CSAIL). "Vi ville undersöka om vi kunde flytta maskininlärning framåt genom att försöka förstå de olika relationerna som påverkar ett nätverks noggrannhet."
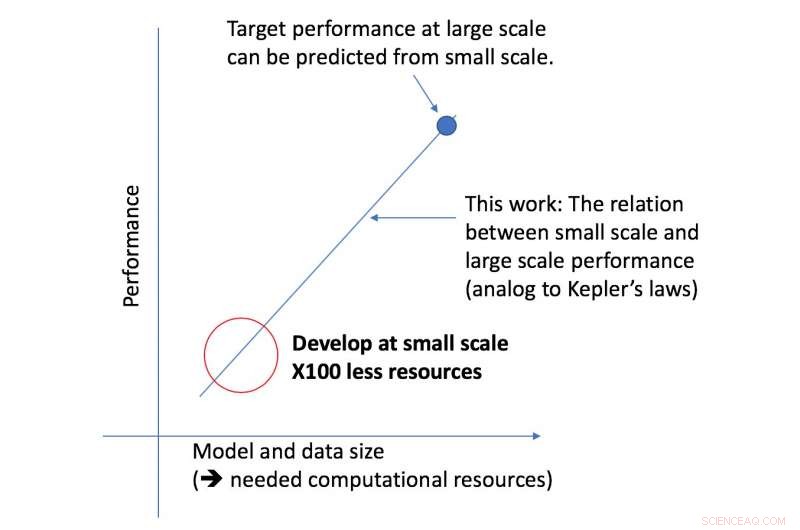
CSAIL-teamets nya ramverk tittar på en given algoritm i mindre skala, och, baserat på faktorer som dess form, kan förutsäga hur bra det kommer att prestera i större skala. Detta gör att en dataforskare kan avgöra om det är värt att fortsätta att ägna mer resurser för att träna systemet ytterligare.
"Vårt tillvägagångssätt säger oss saker som mängden data som behövs för att en arkitektur ska kunna leverera ett specifikt målprestanda, eller den mest beräkningsmässigt effektiva avvägningen mellan data och modellstorlek, " säger MIT-professor Nir Shavit, som skrev den nya tidningen tillsammans med Rosenfeld, tidigare doktorand Yonatan Belinkov och Amir Rosenfeld vid York University. "Vi ser dessa resultat som att de har långtgående implikationer inom området genom att tillåta forskare inom akademi och industri att bättre förstå sambanden mellan de olika faktorer som måste vägas när man utvecklar modeller för djupinlärning, och att göra det med de begränsade beräkningsresurser som är tillgängliga för akademiker."
Ramverket gjorde det möjligt för forskare att exakt förutsäga prestanda vid den stora modellen och dataskalorna med femtio gånger mindre beräkningskraft.
Aspekten av djupinlärningsprestanda som teamet fokuserade på är det så kallade "generaliseringsfelet, " som hänvisar till felet som genereras när en algoritm testas på verkliga data. Teamet använde konceptet med modellskalning, vilket innebär att modellformen ändras på specifika sätt för att se dess effekt på felet.
Som nästa steg, teamet planerar att utforska de underliggande teorierna om vad som gör att en specifik algoritms prestanda lyckas eller misslyckas. Detta inkluderar att experimentera med andra faktorer som kan påverka utbildningen av djupinlärningsmodeller.