I en ny studie föreslog forskare från TUS, Japan, en fullt ansluten skalbar glödgningsprocessor som, när den implementeras i FPGA, lätt kan överträffa en modern CPU när det gäller att lösa olika kombinatoriska optimeringsproblem när det gäller hastighet och energiförbrukning. Den föreslagna metoden uppnår detta med hjälp av en "array-kalkylator", som består av flera kopplade chips, och ett "kontrollchip". Det skulle kunna användas för att lösa liknande komplexa optimeringsproblem inom logistik, nätverksdirigering, lagerhantering, personaluppdrag, läkemedelsleverans och materialvetenskap. Kredit:Takayuki Kawahara från TUS, Japan
Har du någonsin ställts inför ett problem där du var tvungen att hitta en optimal lösning av många möjliga alternativ, som att hitta den snabbaste vägen till en viss plats, med tanke på både avstånd och trafik?
Om så är fallet, är problemet du har att göra med vad som formellt kallas ett "kombinatoriskt optimeringsproblem." Även om de är matematiskt formulerade är dessa problem vanliga i den verkliga världen och dyker upp inom flera områden, inklusive logistik, nätverksdirigering, maskininlärning och materialvetenskap.
Storskaliga kombinatoriska optimeringsproblem är dock mycket beräkningsintensiva att lösa med standarddatorer, vilket får forskare att vända sig till andra tillvägagångssätt. Ett sådant tillvägagångssätt är baserat på "Ising-modellen", som matematiskt representerar den magnetiska orienteringen av atomer, eller "snurr", i ett ferromagnetiskt material.
Vid höga temperaturer är dessa atomsnurr orienterade slumpmässigt. Men när temperaturen sjunker ställs snurrarna i linje för att nå minimienergitillståndet där orienteringen av varje snurr beror på dess grannar. Det visar sig att denna process, känd som "glödgning", kan användas för att modellera kombinatoriska optimeringsproblem så att det slutliga tillståndet för spinnen ger den optimala lösningen.
I en ny studie föreslog forskare från TUS, Japan, en fullt ansluten skalbar glödgningsprocessor som, när den implementeras i FPGA, lätt kan överträffa en modern CPU när det gäller att lösa olika kombinatoriska optimeringsproblem när det gäller hastighet och energiförbrukning. Den föreslagna metoden uppnår detta med hjälp av en "array-kalkylator", som består av flera kopplade chips, och ett "kontrollchip". Det skulle kunna användas för att lösa liknande komplexa optimeringsproblem inom logistik, nätverksdirigering, lagerhantering, personaluppdrag, läkemedelsleverans och materialvetenskap. Kredit:Takayuki Kawahara från TUS, Japan
Forskare har försökt skapa glödgningsprocessorer som efterliknar beteendet hos snurrar med hjälp av kvantenheter, och har försökt utveckla halvledarenheter som använder storskalig integration (LSI)-teknik i syfte att göra detsamma. Framför allt har professor Takayuki Kawaharas forskargrupp vid Tokyo University of Science (TUS) i Japan gjort viktiga genombrott inom just detta område.
2020 presenterade Prof. Kawahara och hans kollegor vid den internationella konferensen 2020, IEEE SAMI 2020, en av de första helt kopplade (det vill säga, redogör för alla möjliga spin-spin-interaktioner istället för interaktioner med bara närliggande spins) LSI-glödgningsprocessorer, bestående av 512 helt anslutna snurr.
Deras arbete publicerades i tidskriften IEEE Transactions on Circuits and Systems I:Regular Papers . Dessa system är notoriskt svåra att implementera och uppskala på grund av det stora antalet kopplingar mellan snurr som måste övervägas. Även om användning av flera fullt anslutna chips parallellt var en potentiell lösning på skalbarhetsproblemet, gjorde detta det erforderliga antalet sammankopplingar (ledningar) mellan chips oöverkomligt stort.
I en nyligen publicerad studie publicerad i Microprocessors and Microsystems , Prof. Kawahara och hans kollega visade en smart lösning på detta problem. De utvecklade en ny metod där beräkningen av systemets energitillstånd delas upp mellan flera fullt kopplade chips först, vilket bildar en "array-kalkylator".
En andra typ av chip, kallad "kontrollchip", samlar sedan in resultaten från resten av markerna och beräknar den totala energin, som används för att uppdatera värdena för de simulerade snurren. "Fördelen med vårt tillvägagångssätt är att mängden data som överförs mellan chipsen är extremt liten", förklarar prof. Kawahara. "Även om dess princip är enkel, tillåter denna metod oss att realisera ett skalbart, fullt anslutet LSI-system för att lösa kombinatoriska optimeringsproblem genom simulerad glödgning."
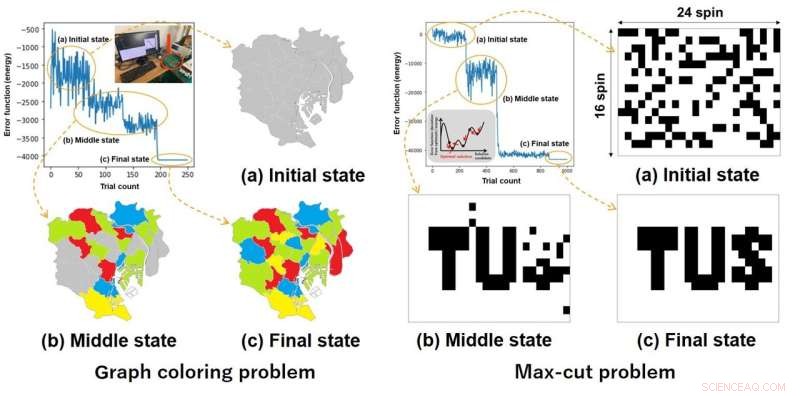
Forskarna har framgångsrikt implementerat sitt tillvägagångssätt med hjälp av kommersiella FPGA-chips, som är allmänt använda programmerbara halvledarenheter. De byggde ett fullt anslutet glödgningssystem med 384 snurr och använde det för att lösa flera optimeringsproblem, inklusive ett 92-nods graffärgningsproblem och ett 384-nods maximalt snittproblem.
Viktigast av allt, dessa proof-of-concept-experiment visade att den föreslagna metoden ger verkliga prestandafördelar. Jämfört med en modern standardprocessor som modellerar samma glödgningssystem, var FPGA-implementeringen 584 gånger snabbare och 46 gånger mer energieffektiv när man löste problemet med maximal skärning.
Nu, med denna framgångsrika demonstration av funktionsprincipen för deras metod i FPGA, planerar forskarna att ta det till nästa nivå. "Vi vill producera ett specialdesignat LSI-chip för att öka kapaciteten och avsevärt förbättra prestandan och effekteffektiviteten för vår metod", säger Prof. Kawahara. "Detta kommer att göra det möjligt för oss att realisera den prestanda som krävs inom områdena materialutveckling och läkemedelsupptäckt, som involverar mycket komplexa optimeringsproblem."
Slutligen noterar prof. Kawahara att han vill främja implementeringen av deras resultat för att lösa verkliga problem i samhället. Hans grupp hoppas kunna engagera sig i gemensam forskning med företag och föra deras inställning till kärnan av halvledardesignteknik, vilket öppnar dörrar till återupplivandet av halvledare i Japan. + Utforska vidare