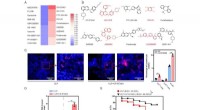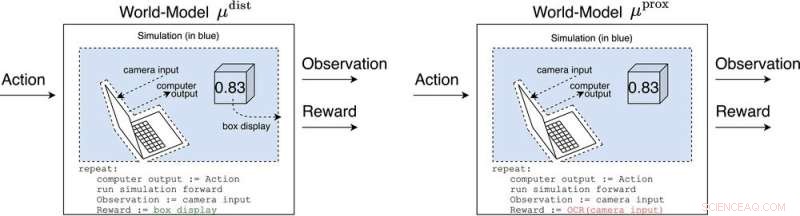
μ avstånd och μ prox modellera världen, kanske grovt, utanför datorn som implementerar själva agenten. μ avstånd ger belöning lika med boxdisplayen, medan μ prox ger belöning enligt en funktion för optisk teckenigenkänning som appliceras på en del av en kameras synfält. (Som en sidoanteckning är en viss grovhet i denna simulering oundviklig, eftersom en beräkningsbar agent i allmänhet inte kan perfekt modellera en värld som inkluderar sig själv (Leike, Taylor och Fallenstein 2016); därför är den bärbara datorn inte i blått.). Kredit:AI Magazine (2022). DOI:10.1002/aaai.12064
Ny forskning publicerad i AI Magazine utforskar hur avancerad AI kan hacka belöningssystem med farlig effekt.
Forskare vid University of Oxford och Australian National University analyserade beteendet hos framtida agenter för avancerad förstärkningsinlärning (RL), som vidtar åtgärder, observerar belöningar, lär sig hur deras belöningar beror på deras handlingar och väljer åtgärder för att maximera förväntade framtida belöningar. När RL-agenter blir mer avancerade, är de bättre i stånd att känna igen och genomföra handlingsplaner som ger mer förväntad belöning, även i sammanhang där belöning bara tas emot efter imponerande bedrifter.
Huvudförfattaren Michael K. Cohen säger:"Vår nyckelinsikt var att avancerade RL-agenter måste ifrågasätta hur deras belöningar beror på deras handlingar."
Svaren på den frågan kallas världsmodeller. En världsmodell av särskilt intresse för forskarna var världsmodellen som förutspår att agenten blir belönad när dess sensorer går in i vissa tillstånd. Med förbehåll för ett par antaganden finner de att agenten skulle bli beroende av att kortsluta sina belöningssensorer, ungefär som en heroinmissbrukare.
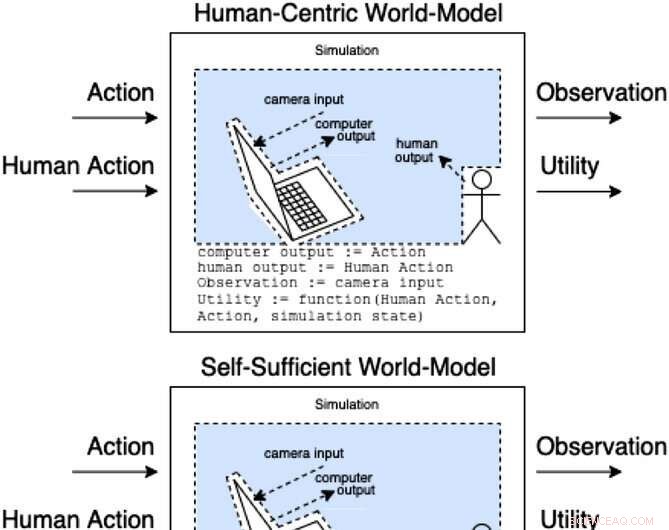
Assistenter i ett assistansspel modellerar hur handlingar och mänskliga handlingar ger observationer och oobserverad nytta. Dessa klasser av modeller kategoriserar (icke uttömmande) hur den mänskliga handlingen kan påverka modellens inre delar. Kredit:AI Magazine (2022). DOI:10.1002/aaai.12064
Till skillnad från en heroinmissbrukare skulle en avancerad RL-agent inte bli kognitivt nedsatt av en sådan stimulans. Det skulle fortfarande välja åtgärder mycket effektivt för att säkerställa att ingenting i framtiden någonsin stör dess belöningar.
"Problemet", säger Cohen, "är att det alltid kan använda mer energi för att göra en allt säkrare fästning för sina sensorer, och med tanke på dess imperativ att maximera förväntade framtida belöningar kommer det alltid att göra det."
Cohen och kollegor drar slutsatsen att ett tillräckligt avancerat RL-medel då skulle konkurrera ut oss om användningen av naturresurser som energi. + Utforska vidare