'Théâtre D'opéra Spatial' Kredit:Jason Allen / Midjourney
Ett konstpris på Colorado State Fair delades ut förra månaden till ett verk som – utan att domarna kände till det – genererades av ett artificiell intelligens (AI)-system.
Sociala medier har också sett en explosion av konstiga bilder genererade av AI från textbeskrivningar, som "ansiktet på en shiba inu blandat in i sidan av en brödlimpa på en köksbänk, digital konst."

Eller kanske "En havsutter i stil med 'Girl with a Pearl Earring' av Johannes Vermeer":

'En havsutter i stil med 'Girl with a Pearl Earring' av Johannes Vermeer.' Kredit:OpenAI
Du kanske undrar vad som händer här. Som någon som forskar om kreativa samarbeten mellan människor och AI kan jag berätta att bakom rubrikerna och memen pågår en fundamental revolution – med djupgående sociala, konstnärliga, ekonomiska och tekniska implikationer.
Hur vi kom hit
Man kan säga att denna revolution började i juni 2020, när ett företag som heter OpenAI fick ett stort genombrott inom AI med skapandet av GPT-3, ett system som kan bearbeta och generera språk på mycket mer komplexa sätt än tidigare ansträngningar. Du kan föra samtal med den om vilket ämne som helst, be den skriva en forskningsartikel eller en berättelse, sammanfatta text, skriva ett skämt och göra nästan alla tänkbara språkuppgifter.
2021 vände några av GPT-3:s utvecklare åt bilder. De tränade en modell på miljarder par av bilder och textbeskrivningar och använde den sedan för att generera nya bilder från nya beskrivningar. De kallade detta system för DALL-E, och i juli 2022 släppte de en mycket förbättrad ny version, DALL-E 2.

En bild genererad av DALL-E från prompten "Mind in Bloom" som kombinerar stilarna från Salvador Dali, Henri Matisse och Brett Whiteley. Kredit:Rodolfo Ocampo / DALL-E
Liksom GPT-3 var DALL-E 2 ett stort genombrott. Det kan generera mycket detaljerade bilder från textinmatningar i fritt format, inklusive information om stil och andra abstrakta koncept.
Till exempel, här bad jag den att illustrera frasen "Mind in Bloom" som kombinerar stilarna från Salvador Dalí, Henri Matisse och Brett Whiteley.
Tävlande kommer in på scenen
Sedan lanseringen av DALL-E 2 har några konkurrenter dykt upp. Den ena är den fria att använda men lägre kvalitet DALL-E Mini (utvecklad oberoende och nu bytt namn till Craiyon), som var en populär källa till meme-innehåll.
Ungefär samtidigt släppte ett mindre företag vid namn Midjourney en modell som bättre matchade DALL-E 2:s kapacitet. Även om Midjourney fortfarande är lite mindre kapabel än DALL-E 2, har Midjourney lånat ut sig för intressanta konstnärliga undersökningar. Det var med Midjourney som Jason Allen skapade konstverket som vann Colorado State Art Fair-tävlingen.
Google har också en text-till-bild-modell, kallad Imagen, som förmodligen ger mycket bättre resultat än DALL-E och andra. Imagen har dock ännu inte släppts för bredare användning så det är svårt att utvärdera Googles påståenden.
I juli 2022 började OpenAI att kapitalisera på intresset i DALL-E och tillkännagav att 1 miljon användare skulle ges åtkomst på basis av betalning för användning.
Men i augusti 2022 kom en ny utmanare:Stable Diffusion.
Stable Diffusion konkurrerar inte bara med DALL-E 2 i dess kapacitet, utan ännu viktigare är den öppen källkod. Vem som helst kan använda, anpassa och justera koden som de vill.
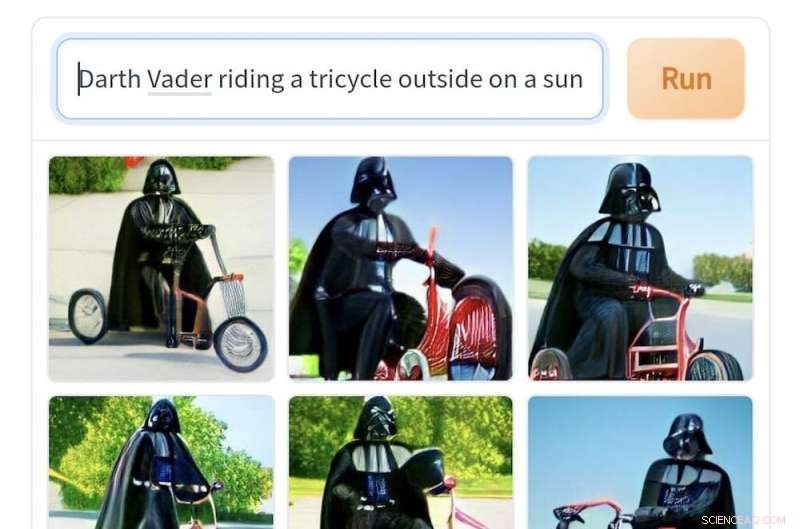
Bilder genererade av Craiyon från prompten "Darth Vader rider en trehjuling ute på en solig dag". Kredit:Craiyon
Redan under veckorna sedan Stable Diffusion släpptes har människor pressat koden till gränserna för vad den kan göra.
För att ta ett exempel:folk insåg snabbt att eftersom en video är en sekvens av bilder, kunde de justera Stable Diffusions kod för att generera video från text.
@StableDiffusion Img2Img x #ebsynth x @koe_recast TEST#stablediffusion #AIart pic.twitter.com/aZgZZBRjWM
— Scott Lighthiser (@LighthiserScott) 7 september 2022
Ett annat fascinerande verktyg byggt med Stable Diffusions kod är Diffuse the Rest, som låter dig rita en enkel skiss, ge en textuppmaning och generera en bild från den.
Slutet på kreativiteten?
Vad betyder det att du kan generera vilken typ av visuellt innehåll, bild eller video som helst, med några rader text och ett klick på en knapp? Vad sägs om när du kan skapa ett filmmanus med GPT-3 och en filmanimation med DALL-E 2?
Och ser vi längre fram, vad kommer det att betyda när sociala mediers algoritmer inte bara kurerar innehåll för ditt flöde, utan genererar det? What about when this trend meets the metaverse in a few years, and virtual reality worlds are generated in real time, just for you?
These are all important questions to consider.
Some speculate that, in the short term, this means human creativity and art are deeply threatened.
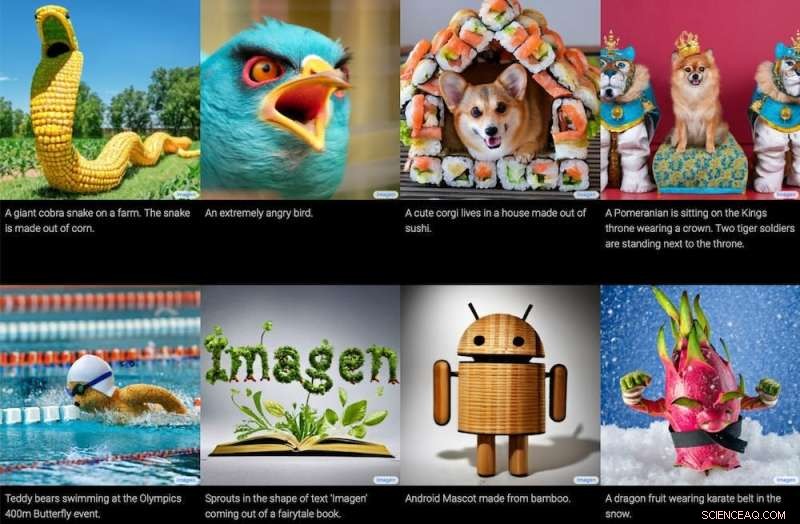
Images generated by the Imagen text-to-image model, together with the text that produced them. Google / Imagen
Perhaps in a world where anyone can generate any images, graphic designers as we know them today will be redundant. However, history shows human creativity finds a way. The electronic synthesizer did not kill music, and photography did not kill painting. Instead, they catalyzed new art forms.
I believe something similar will happen with AI generation. People are experimenting with including models like Stable Diffusion as a part of their creative process.
Or using DALL-E 2 to generate fashion-design prototypes:
Want to use @StableDiffusion right from #Photoshop? Now you can!https://t.co/gqFWpABQLY pic.twitter.com/LbgSWZz31L
— Christian Cantrell (@cantrell) September 8, 2022
A new type of artist is even emerging in what some call "promptology," or "prompt engineering". The art is not in crafting pixels by hand, but in crafting the words that prompt the computer to generate the image:a kind of AI whispering.
Collaborating with AI
The impacts of AI technologies will be multidimensional:we cannot reduce them to good or bad on a single axis.
New artforms will arise, as will new avenues for creative expression. However, I believe there are risks as well.
We live in an attention economy that thrives on extracting screen time from users; in an economy where automation drives corporate profit but not necessarily higher wages, and where art is commodified as content; in a social context where it is increasingly hard to distinguish real from fake; in sociotechnical structures that too easily encode biases in the AI models we train. In these circumstances, AI can easily do harm.
How can we steer these new AI technologies in a direction that benefits people? I believe one way to do this is to design AI that collaborates with, rather than replaces, humans. + Utforska vidare
Den här artikeln är återpublicerad från The Conversation under en Creative Commons-licens. Läs originalartikeln.