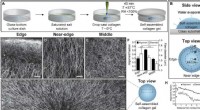
Bild genererad från texten "Glada grönsaker som väntar på kvällsmaten.". Kredit:Ludwig Maximilian University of München
Skapa bilder från text på några sekunder – och gör det med ett vanligt grafikkort och utan superdatorer? Hur fantasifullt det än kan låta så är detta möjligt tack vare den nya Stable Diffusion AI-modellen. Den underliggande algoritmen har utvecklats av Machine Vision &Learning Group under ledning av prof. Björn Ommer (LMU München).
"Även för lekmän som inte är välsignade med konstnärlig talang och utan speciell datorkunskap och datorhårdvara är den nya modellen ett effektivt verktyg som gör det möjligt för datorer att generera bilder på kommando. Som sådan tar modellen bort en barriär för vanliga människor att uttrycka sin kreativitet , säger Ommer. Men det finns fördelar för erfarna artister också, som kan använda Stable Diffusion för att snabbt omvandla nya idéer till en mängd olika grafiska utkast. Forskarna är övertygade om att sådana AI-baserade verktyg kommer att kunna utöka möjligheterna till kreativ bildgenerering med pensel och Photoshop lika fundamentalt som datorbaserad ordbehandling revolutionerade skrivandet med pennor och skrivmaskiner.
I sitt projekt hade LMU-forskarna stöd av uppstarten Stability.Ai, på vars servrar AI-modellen tränades. "Denna extra datorkraft och de extra träningsexemplen gjorde vår AI-modell till en av de mest kraftfulla bildsyntesalgoritmerna", säger datavetaren.
Kärnan i miljarder träningsbilder
En speciell aspekt av tillvägagångssättet är att trots all kraften hos den tränade modellen är den ändå så kompakt att den körs på ett konventionellt grafikkort och inte kräver en superdator som tidigare var fallet för bildsyntes. För detta ändamål destillerar den artificiella intelligensen essensen av miljarder träningsbilder till en AI-modell på bara några gigabyte.
"När en sådan AI verkligen har förstått vad som är en bil eller vilka egenskaper som är typiska för en konstnärlig stil, kommer den att ha uppfattat just dessa framträdande egenskaper och borde helst kunna skapa ytterligare exempel, precis som eleverna i en gammal mästarverkstad kan producera arbeta i samma stil, förklarar Ommer. I jakten på LMU-forskarnas mål att få datorer att lära sig att se – det vill säga att förstå innehållet i bilder – är detta ytterligare ett stort steg framåt, som ytterligare främjar grundforskningen inom maskininlärning och datorseende.
Den utbildade modellen släpptes nyligen gratis under licensen "CreativeML Open RAIL-M" för att underlätta vidare forskning och tillämpning av denna teknik mer allmänt. "Vi är spännande att se vad som kommer att byggas med de nuvarande modellerna samt att se vilka ytterligare arbeten som kommer att komma ut av öppna, samverkande forskningsinsatser", säger doktorandforskaren Robin Rombach. + Utforska vidare