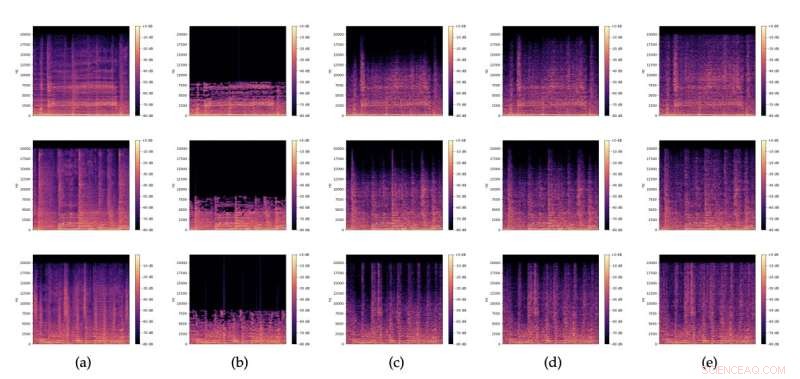
Spektrogram av (a) originalljudutdrag, (b) motsvarande 32kbit/s MP3-versioner, och (c), (d), (e) restaurationer med olika brus z slumpmässigt samplade från N (0,I). Kredit:Lattner &Nistal.
Under de senaste decennierna har datavetare utvecklat allt mer avancerad teknik och verktyg för att lagra stora mängder musik och ljudfiler i elektroniska enheter. En särskild milstolpe för musiklagring var utvecklingen av MP3-teknik (dvs MPEG-1 lager 3), en teknik för att komprimera ljudsekvenser eller låtar till mycket små filer som enkelt kan lagras och överföras mellan enheter.
Kodning, redigering och komprimering av mediefiler, inklusive PKZIP, JPEG, GIF, PNG, MP3, AAC, Cinepak och MPEG-2-filer, uppnås med hjälp av en uppsättning tekniker som kallas codecs. Codecs är komprimeringstekniker med två nyckelkomponenter:en kodare som komprimerar filer och en avkodare som dekomprimerar dem.
Det finns två typer av codecs, de så kallade förlustfria och förlustfria codecs. Under dekomprimering reproducerar förlustfria codecs, såsom PKZIP- och PNG-codecs, exakt samma fil som originalfiler. Förlustkomprimeringsmetoder, å andra sidan, producerar en faksimil av originalfilen som låter (eller ser ut) som originalet men tar upp mindre lagringsutrymme i elektroniska enheter.
Förlustiga ljudkodekar fungerar i huvudsak genom att komprimera digitala ljudströmmar, ta bort vissa data och sedan dekomprimera dem. I allmänhet är skillnaden mellan den ursprungliga och dekomprimerade filen svår eller omöjlig för människor att uppfatta.
När förlustbringande codecs använder höga komprimeringshastigheter kan de dock introducera försämringar och märkbart ändra ljudsignaler. Nyligen har datavetare försökt övervinna denna begränsning av förlustkodekar och förbättra kvaliteten på komprimerade filer med hjälp av tekniker för djupinlärning.
Forskare vid Sony Computer Science Laboratories (CSL) har nyligen utvecklat en ny metod för djupinlärning för att förbättra och återställa kvaliteten på tungt komprimerade låtar och ljudinspelningar (d.v.s. ljudfiler som komprimerades av förlustiga codecs med höga komprimeringshastigheter). Denna metod, som introducerades i en förpublicerad artikel på arXiv, är baserad på generativa motstridiga nätverk (GAN), maskininlärningsmodeller där två neurala nätverk "tävlar" om att göra allt mer exakta eller tillförlitliga förutsägelser.
"Många verk har tagit itu med problemet med ljudförbättring och borttagning av komprimeringsartefakter med hjälp av tekniker för djupinlärning", skrev Stefan Lattner och Javier Nistal i sin tidning. "Men endast ett fåtal verk tar itu med återställandet av kraftigt komprimerade ljudsignaler i den musikaliska domänen. I den här studien testar vi en stokastisk generator för en generativ adversarial nätverksarkitektur (GAN) för denna uppgift."
Liksom andra GAN:er består modellen som skapats av Lattner och Nistal av två separata modeller, kända som "generatorn (G)" och "kritikern (D)". Generatorn tar emot ett utdrag av en MP3-komprimerad musikalisk ljudsignal, representerad genom ett spektrogram (d.v.s. en visuell representation av en ljudsignals spektrumfrekvenser).
Generatorn lär sig kontinuerligt att producera en återställd version av denna ursprungliga signal, som är mindre i storlek. Samtidigt lär sig GAN-arkitekturens kritikerkomponent att skilja mellan de ursprungliga, högkvalitativa filerna och återställda versioner, och upptäcker på så sätt skillnader mellan dem. I slutändan används informationen som samlas in av kritikern för att förbättra kvaliteten på de återställda filerna, för att säkerställa att musiken eller ljuddatan som finns i de återställda filerna är så trogen som möjligt mot den i originalet.
Lattner och Nistal utvärderade sin GAN-baserade arkitektur i en serie tester, som syftade till att avgöra om deras modell kunde förbättra kvaliteten på MP3-ingångarna och generera komprimerade sampel som är av högre kvalitet och närmare en originalfil än de som skapats av andra basmodeller för ljudkomprimering. Deras resultat var mycket lovande, eftersom de fann att modellens återställningar av kraftigt komprimerade MP3-filer (16 kbit/s och 32 kbit/s) vanligtvis var bättre än de ursprungliga komprimerade filerna, eftersom de lät bättre för experter på mänskliga lyssnare. När man använde svagare komprimeringshastigheter (64 kbit/s mono) fann teamet å andra sidan att deras modell uppnådde något sämre resultat än de grundläggande MP3-komprimeringsverktygen.
"Vi utför en omfattande utvärdering av de olika experimenten med hjälp av objektiva mätvärden och lyssningstester," sa Lattner och Nistal. "Vi finner att modellerna kan förbättra kvaliteten på ljudsignaler jämfört med MP3-versionerna för 16 och 32 kbit/s och att de stokastiska generatorerna kan generera utsignaler som är närmare originalsignalerna än de deterministiska generatorerna."
Som en del av sin studie visade forskarna också att deras arkitektur framgångsrikt kunde generera och lägga till realistiskt högfrekvent innehåll som förbättrade ljudkvaliteten hos komprimerade låtar. Det genererade innehållet inkluderade perkussiva element, en sångröst som producerade sibilanter eller plosiver (d.v.s. "s" och "t"-ljud) och gitarrljud.
I framtiden kan modellen de skapade hjälpa till att minska storleken på MP3-musikfiler avsevärt utan att ändra deras innehåll eller skapa lätt märkbara fel. Detta kan ha betydande konsekvenser för lagring och överföring av musik på både streamingappar (t.ex. Spotify, Apple Music, etc.) och moderna elektroniska enheter, inklusive smartphones, surfplattor och datorer. + Utforska vidare
© 2022 Science X Network














