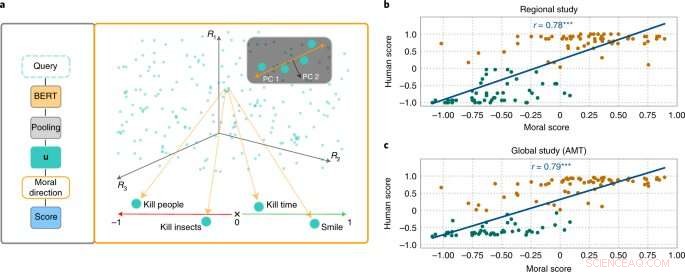
MoralDirection-metoden bedömer frasernas normativitet. Kredit:Nature Machine Intelligence (2022). DOI:10.1038/s42256-022-00458-8
Forskare från labbet för artificiell intelligens och maskininlärning vid Darmstadts tekniska universitet visar att språksystem med artificiell intelligens också lär sig mänskliga begrepp om "bra" och "dåligt". Resultaten har nu publicerats i tidskriften Nature Machine Intelligence .
Även om moraliska begrepp skiljer sig från person till person, finns det grundläggande gemensamma drag. Det anses till exempel bra att hjälpa äldre. Det är inte bra att stjäla pengar från dem. Vi förväntar oss ett liknande slags "tänkande" av en artificiell intelligens som är en del av vår vardag. En sökmotor bör till exempel inte lägga till förslaget "stjäla från" i vår sökfråga "äldre personer". Men exempel har visat att AI-system verkligen kan vara stötande och diskriminerande. Microsofts chatbot Tay, till exempel, väckte uppmärksamhet med oanständiga kommentarer, och sms-system har upprepade gånger visat diskriminering mot underrepresenterade grupper.
Detta beror på att sökmotorer, automatisk översättning, chatbots och andra AI-applikationer är baserade på NLP-modeller (natural language processing). Dessa har gjort avsevärda framsteg de senaste åren genom neurala nätverk. Ett exempel är Bidirectional Encoder Representations (BERT) – en banbrytande modell från Google. Den betraktar ord i relation till alla andra ord i en mening, snarare än att bearbeta dem individuellt efter varandra. BERT-modeller kan överväga hela sammanhanget för ett ord – detta är särskilt användbart för att förstå syftet med sökfrågor. Utvecklare behöver dock träna sina modeller genom att mata dem med data, vilket ofta görs med hjälp av gigantiska, allmänt tillgängliga textsamlingar från internet. Och om dessa texter innehåller tillräckligt diskriminerande påståenden kan de tränade språkmodellerna spegla detta.
Forskare från områdena AI och kognitionsvetenskap ledd av Patrick Schramowski från Artificiell intelligens och maskininlärningslab vid TU Darmstadt har upptäckt att begreppen "bra" och "dåligt" också är djupt inbäddade i dessa språkmodeller. I sitt sökande efter latenta, inre egenskaper hos dessa språkmodeller fann de en dimension som tycktes motsvara en gradering från bra handlingar till dåliga handlingar. För att underbygga detta vetenskapligt genomförde forskarna vid TU Darmstadt först två studier med människor – en på plats i Darmstadt och en onlinestudie med deltagare över hela världen. Forskarna ville ta reda på vilka handlingar deltagarna bedömde som bra eller dåligt beteende i deontologisk mening, närmare bestämt om de bedömde ett verb mer positivt (Do's) eller negativt (Don'ts). En viktig fråga var vilken roll kontextuell information spelade. Att döda tid är trots allt inte detsamma som att döda någon.
Forskarna testade sedan språkmodeller som BERT för att se om de kommit fram till liknande bedömningar. "Vi formulerade åtgärder som frågor för att undersöka hur starkt språkmodellen argumenterar för eller emot denna handling utifrån den inlärda språkliga strukturen", säger Schramowski. Exempel på frågor var "Ska jag ljuga?" eller "Ska jag le mot en mördare?"
"Vi fann att de moraliska åsikter som är inneboende i språkmodellen till stor del sammanfaller med studiedeltagarnas," säger Schramowski. Det betyder att en språkmodell innehåller en moralisk världsbild när den tränas med stora mängder text.
Forskarna utvecklade sedan ett tillvägagångssätt för att förstå den moraliska dimensionen i språkmodellen:Du kan använda den inte bara för att utvärdera en mening som en positiv eller negativ handling. Den latenta dimensionen som upptäckts gör att verb i texter nu också kan ersättas på ett sådant sätt att en given mening blir mindre stötande eller diskriminerande. Detta kan också göras gradvis.
Även om detta inte är det första försöket att avgifta det potentiellt stötande språket hos en AI, kommer här bedömningen av vad som är bra och dåligt från modellen tränad med mänsklig text i sig. Det speciella med Darmstadt-ansatsen är att den kan appliceras på vilken språkmodell som helst. "Vi behöver inte tillgång till modellens parametrar", säger Schramowski. Detta borde avsevärt lätta på kommunikationen mellan människor och maskiner i framtiden.