Modellen med blandad effekt möjliggör mer exakt identifiering av hotspots där atmosfäriska variabler förhåller sig annorlunda jämfört med andra områden. Kredit:John Wiley &Sons Ltd.
En mer tillförlitlig metod för att identifiera regioner med olika samband mellan luftföroreningar och väderförhållanden förbättrar upptäckten av hotspots för föroreningar.
Förhållandet mellan väderförhållanden och luftföroreningar är komplext och kan variera kraftigt från plats till plats. Detta gör det svårt att lokalisera källorna till föroreningar och förutsäga dess beteende i atmosfären. Medan dataforskare och statistiker har gjort betydande framsteg i brottningen med detta problem, de enorma mängderna miljödata och mängden variabler, som vindhastighet, temperatur och föroreningskomponent, kräver kompromisser för att göra problemet hanterbart.
Till exempel, de flesta befintliga metoder för att upptäcka "hotspots" i korrelationen mellan variabler i rumslig data involverar att konstruera ett rutnät där förhållandet mellan variabler i en cell behandlas oberoende av alla andra. Även om detta inte är helt realistiskt – det finns ofta ett beroende mellan rumsliga områden, särskilt i väder- och luftföroreningsdata – är det utomordentligt svårt att hitta rumsliga hotspots och samtidigt bestämma den rumsliga beroendestrukturen.
Ying Sun och Junho Lee från KAUSTs Environmental Statistics Laboratory har tagit ett steg framåt för att ta itu med detta problem med utvecklingen av en "mixed effect-modell" för hotspot-detektion.

Den här kartan visar hur modellen med blandad effekt delar upp nordöstra USA i block, så att de kan identifiera "hotspots". Kredit:John Wiley &Sons Ltd
"Vi tar itu med problemet genom att använda en enkel rumslig blockstruktur för att approximera det rumsliga beroendet, " säger Lee. "Detta tillåter oss att hitta rumsliga hotspots som visar distinkta mönster samtidigt som vi minskar frekvensen av falska positiva på grund av rumsligt beroende."
Tillvägagångssättet, utvecklad i samarbete med Howard Chang från Emory University i USA, innebär att dela upp regionen i block och sekventiellt applicera slumpmässiga effekter på blocken för att reta ut starka korrelationer från bakgrundsvariationer eller "brus". Detta har den extra fördelen att kunna identifiera valfritt antal hotspot-kluster i data, inklusive kluster som kan överlappa varandra.
"Den största utmaningen var hur man bestämmer en lämplig blockstorlek för de slumpmässiga effekterna, " säger Lee. "Vi bestämde oss för att matcha blockstorleken till intervallet av rumsligt beroende i data."
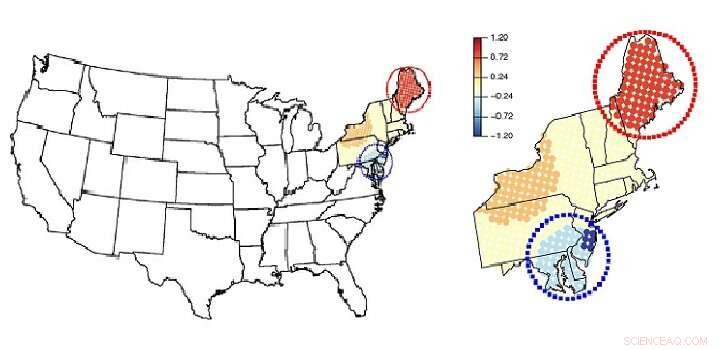
Teamet använde sin metod för att analysera luftföroreningsdata över nordöstra USA. De upptäckte att på sommaren, koncentrationerna av partiklar i mikrometerskala i luften (PM2,5) ökade med temperaturen och minskade med relativ fuktighet över större delen av regionen.
"Dock, med vårt förhållningssätt, vi kunde hitta distinkta områden med motsatt trend, som i Chesapeake Bay-området, där det finns ett negativt samband mellan PM2,5 och temperatur, och runt Maine där det finns en positiv korrelation mellan PM2,5 och relativ luftfuktighet, " säger Lee.














