Ett internationellt team av forskare presenterar en grundlig genomgång av kvantmaskininlärning, dess nuvarande status och framtidsutsikter. Rapporterna kontrasterar maskininlärning med klassiska och kvantresurser, identifiera möjligheter som kvantberäkning ger till detta område. Kredit:ICFO
Språkinlärning hos små barn hänger tydligen ihop med deras förmåga att upptäcka mönster. I sin inlärningsprocess, de söker efter mönster i datamängden som hjälper dem att identifiera och optimera grammatikstrukturer för att korrekt tillägna sig språket. Likaså, onlineöversättare använder algoritmer genom maskininlärningstekniker för att optimera sina översättningsmotorer för att ge väl avrundade och begripliga resultat. Även om många översättningar inte var särskilt meningsfulla i början, under de senaste åren har vi kunnat se stora förbättringar tack vare maskininlärning.
Maskininlärningstekniker använder matematiska algoritmer och verktyg för att söka efter mönster i data. Dessa tekniker har blivit kraftfulla verktyg för många olika applikationer, som kan sträcka sig från biomedicinska användningsområden som i cancerspaning, inom genetik och genomik, i autismövervakning och diagnos och till och med plastikkirurgi, till ren tillämpad fysik, för att studera materialens natur, materia eller till och med komplexa kvantsystem.
Kan anpassa och förändras när de utsätts för en ny uppsättning data, maskininlärning kan identifiera mönster, ofta överträffar människor i precision. Även om maskininlärning är ett kraftfullt verktyg, vissa applikationsdomäner förblir utom räckhåll på grund av komplexitet eller andra aspekter som utesluter användningen av de förutsägelser som inlärningsalgoritmer tillhandahåller.
Således, de senaste åren, kvantmaskininlärning har blivit en fråga av intresse på grund av den enorma potentialen som en möjlig lösning på dessa olösliga utmaningar och kvantdatorer visar sig vara det rätta verktyget för sin lösning.
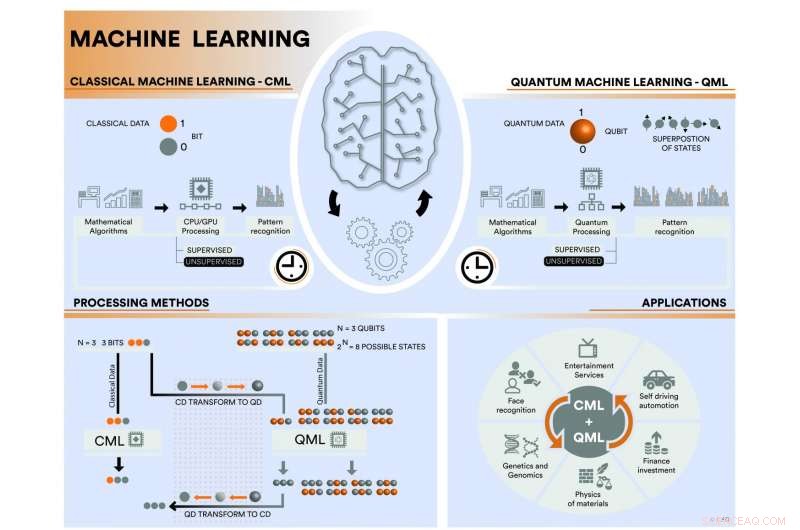
I en nyligen genomförd studie, publicerad i Natur , ett internationellt team av forskare integrerat av Jacob Biamonte från Skoltech/IQC, Peter Wittek från ICFO, Nicola Pancotti från MPQ, Patrick Rebentrost från MIT, Nathan Wiebe från Microsoft Research, och Seth Lloyd från MIT har gått igenom den faktiska statusen för klassisk maskininlärning och kvantmaskininlärning. I sin recension, de har noggrant behandlat olika scenarier som handlar om klassisk och kvantmaskininlärning. I deras studie, de har övervägt olika möjliga kombinationer:den konventionella metoden att använda klassisk maskininlärning för att analysera klassiska data, använda kvantmaskininlärning för att analysera både klassiska och kvantdata, och slutligen, använda klassisk maskininlärning för att analysera kvantdata.
För det första, de syftade till att ge en fördjupad bild av statusen för nuvarande övervakade och oövervakade inlärningsprotokoll inom klassisk maskininlärning genom att ange alla tillämpade metoder. De introducerar kvantmaskininlärning och ger ett omfattande tillvägagångssätt för hur denna teknik kan användas för att analysera både klassiska och kvantdata, betonar att kvantmaskiner kan påskynda bearbetningstider tack vare användningen av kvantglödgare och universella kvantdatorer. Kvantglödgningsteknologi har bättre skalbarhet, men mer begränsade användningsfall. Till exempel, den senaste iterationen av D-Waves supraledande chip integrerar två tusen qubits, och det används för att lösa vissa svåra optimeringsproblem och för effektiv sampling. Å andra sidan, universella (även kallade gate-baserade) kvantdatorer är svårare att skala upp, men de kan utföra godtyckliga enhetsoperationer på kvantbitar genom sekvenser av kvantlogiska grindar. Detta liknar hur digitala datorer kan utföra godtyckliga logiska operationer på klassiska bitar.
Dock, de tar upp det faktum att kontroll av ett kvantsystem är mycket komplext och att analysera klassiska data med kvantresurser är inte så enkelt som man kan tro, främst på grund av utmaningen att bygga kvantgränssnittsenheter som gör att klassisk information kan kodas till en kvantmekanisk form. Svårigheter, problem med "input" eller "output" verkar vara den stora tekniska utmaningen som måste övervinnas.
Det slutliga målet är att hitta den mest optimerade metoden som kan läsa, förstå och få de bästa resultaten av en datamängd, vare sig det är klassiskt eller kvantum. Kvantmaskininlärning syftar definitivt till att revolutionera datavetenskapsområdet, inte bara för att den kommer att kunna styra kvantdatorer, påskynda informationsbehandlingshastigheterna långt bortom nuvarande klassiska hastigheter, men också för att den kan utföra innovativa funktioner, sådan kvantdjupinlärning, som inte bara kunde känna igen kontraintuitiva mönster i data, osynlig för både klassisk maskininlärning och för det mänskliga ögat, men också reproducera dem.
Som Peter Wittek slutligen säger, "Att skriva detta dokument var en ganska utmaning:vi hade en kommitté på sex medförfattare med olika idéer om vad fältet är, var det är nu, och vart det är på väg. Vi skrev om papperet från grunden tre gånger. Den slutliga versionen kunde inte ha fullbordats utan vår redaktörs engagemang, som vi står i skuld till."