En miljon processer är mappade till pixlarna i en 1000 × 1000 pixlar svart-vit skiss av Alan Turing. Pixlarna slås på och av i enlighet med de momentana binära värdena för processerna. Kredit:Nature Communications
"In-memory computing" eller "beräkningsminne" är ett framväxande koncept som använder de fysiska egenskaperna hos minnesenheter för både lagring och bearbetning av information. Detta strider mot nuvarande von Neumann system och enheter, som vanliga stationära datorer, bärbara datorer och till och med mobiltelefoner, som skickar data fram och tillbaka mellan minnet och datorenheten, vilket gör dem långsammare och mindre energieffektiva.
I dag, IBM Research tillkännager att dess forskare har visat att en oövervakad maskininlärningsalgoritm, körs på en miljon Phas Change Memory (PCM) enheter, framgångsrikt hittat tidsmässiga korrelationer i okända dataströmmar. Jämfört med toppmoderna klassiska datorer, denna prototypteknologi förväntas ge 200x förbättringar i både hastighet och energieffektivitet, vilket gör den mycket lämplig för att möjliggöra ultratäta, låg effekt, och massivt parallella datorsystem för applikationer inom AI.
Forskarna använde PCM-enheter gjorda av en germanium antimon telluridlegering, som är staplade och inklämda mellan två elektroder. När forskarna applicerar en liten elektrisk ström på materialet, de värmer det, som ändrar sitt tillstånd från amorft (med ett oordnat atomarrangemang) till kristallint (med en ordnad atomkonfiguration). IBM-forskarna har använt kristalliseringsdynamiken för att utföra beräkningar på plats.
"Detta är ett viktigt steg framåt i vår forskning om AI:s fysik, som utforskar nya hårdvarumaterial, enheter och arkitekturer, " säger Dr Evangelos Eleftheriou, en IBM Fellow och medförfattare till tidningen. "När CMOS-skalningslagarna går sönder på grund av tekniska begränsningar, ett radikalt avsteg från processor-minne-dikotomi behövs för att kringgå begränsningarna hos dagens datorer. Med tanke på enkelheten, hög hastighet och låg energi för vår in-memory computing-metod, det är anmärkningsvärt att våra resultat liknar vårt klassiska klassiska tillvägagångssätt som körs på en von Neumann -dator. "
Detaljerna förklaras i deras papper som visas idag i tidskriften peer-review Naturkommunikation . För att demonstrera tekniken, författarna valde två tidsbaserade exempel och jämförde deras resultat med traditionella maskininlärningsmetoder som k-means clustering:
"Minnet har hittills setts som en plats där vi bara lagrar information. Men i detta arbete, vi visar slutgiltigt hur vi kan utnyttja fysiken hos dessa minnesenheter för att också utföra en ganska hög beräkningsprimitiv. Resultatet av beräkningen lagras också i minnesenheterna, och i denna mening är konceptet löst inspirerat av hur hjärnan beräknar." sa Dr. Abu Sebastian, forskare inom utforskande minne och kognitiv teknologi, IBM Research och huvudförfattare till tidningen.
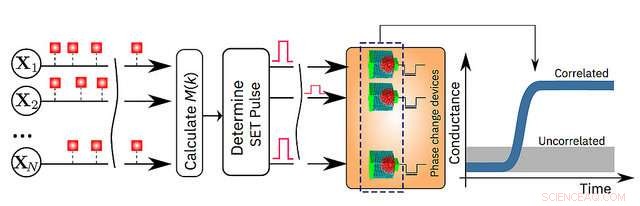
En schematisk illustration av in-memory computing-algoritmen. Kredit:IBM Research