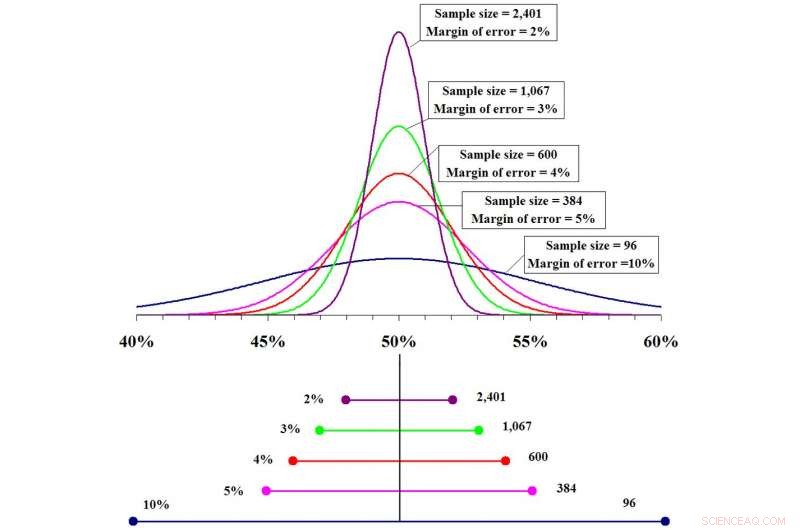
Ju större urvalsstorlek, ju mer exakt förutsägelse och desto mindre felmarginal. Kredit:Fadethree via Wikimedia Commons
Under det senaste året, statistik har varit ovanligt viktig i nyheterna. Hur exakt är covid-19-testet som du eller andra använder? Hur vet forskarna effektiviteten av nya terapier för COVID-19-patienter? Hur kan tv-nätverk förutsäga valresultatet långt innan alla valsedlar har räknats?
Var och en av dessa frågor innebär en viss osäkerhet, men det är fortfarande möjligt att göra korrekta förutsägelser så länge den osäkerheten förstås. Ett verktyg som statistiker använder för att kvantifiera osäkerhet kallas felmarginalen.
Begränsad data
Jag är statistiker, och en del av mitt jobb är att dra slutsatser och förutsägelser. Med obegränsad tid och pengar, Jag skulle helt enkelt kunna testa eller undersöka hela gruppen människor jag är intresserad av för att utvärdera frågan i åtanke och hitta det exakta svaret. Till exempel, för att ta reda på covid-19-infektionsfrekvensen i USA, Jag skulle helt enkelt kunna testa hela USA:s befolkning. Dock, i den verkliga världen, du kan aldrig komma åt 100 % av en befolkning.
Istället, statistiker tar prov på en liten del av befolkningen och bygger en modell för att göra en förutsägelse. Med hjälp av statistisk teori, att resultatet från urvalet extrapoleras för att representera hela populationen.
Helst ett bra urval bör vara representativt för den totala populationen, inklusive kön, rasmässig mångfald, socioekonomisk mångfald, livsstilsmönster och andra demografiska mått. Ju större urval, ju mer lik det skulle vara den sanna befolkningen, och med ett större urval, desto säkrare blir statistikerna i sina förutsägelser. Men det kommer alltid att finnas en viss osäkerhet.
Kvantifiera osäkerhet
Ta läkemedelsutveckling, till exempel. Det är alltid sant att förutsäga att en ny medicin kommer att vara någonstans mellan 0% och 100% effektiv för alla på jorden. Men det är inte en särskilt användbar förutsägelse. Det är en statistikers uppgift att begränsa det intervallet till något mer användbart. Statistiker brukar kalla detta intervall för ett konfidensintervall, och det är intervallet av förutsägelser inom vilka statistiker är mycket säkra på att det verkliga antalet kommer att hittas.
Om ett läkemedel testades på 10 personer och sju av dem fann det effektivt, den uppskattade läkemedlets effektivitet är 70 %. Men eftersom målet är att förutsäga effekten i hela befolkningen, statistiker måste ta hänsyn till osäkerheten med att testa endast 10 personer.
Konfidensintervall beräknas med hjälp av en matematisk formel som omfattar urvalsstorleken, omfånget av svar och sannolikhetslagarna. I det här exemplet, konfidensintervallet skulle vara mellan 42 % och 98 % – ett intervall på 56 procentenheter. Efter att bara ha testat 10 personer, man kan med stor säkerhet säga att läkemedlet är effektivt för mellan 42 % och 98 % av människor i hela befolkningen.
Om du delar upp konfidensintervallet på hälften, du får felmarginalen – i det här fallet, 28 %. Ju större felmarginalen är, desto mindre exakt är förutsägelsen. Ju mindre felmarginalen är, desto mer exakt är förutsägelsen. En felmarginal på nästan 30 % är fortfarande ganska brett.
Dock, föreställ dig att forskarna testade detta nya läkemedel den 1, 000 personer istället för 10 och det var effektivt i 700 av dem. Den uppskattade läkemedelseffekten kommer fortfarande att vara cirka 70 %, men denna förutsägelse är mycket mer exakt. Konfidensintervallet för det större urvalet kommer att vara mellan 67 % och 73 % med en felmarginal på 3 %. Man kan säga att detta läkemedel förväntas vara 70 % effektivt, plus eller minus 3 %, för hela befolkningen.
Statistiker skulle älska att kunna förutsäga med 100 % noggrannhet framgång eller misslyckande för en ny medicin eller de exakta resultaten av ett val. Dock, det här är inte möjligt. Det finns alltid en viss osäkerhet, och felmarginalen är det som kvantifierar denna osäkerhet; det måste beaktas när man tittar på resultaten. Särskilt, felmarginalen definierar intervallet av förutsägelser inom vilka statistiker är mycket säkra på att det verkliga antalet kommer att hittas. En acceptabel felmarginal är en bedömningsfråga baserad på graden av noggrannhet som krävs i de slutsatser som ska dras.
Denna artikel publiceras från The Conversation under en Creative Commons -licens. Läs originalartikeln.