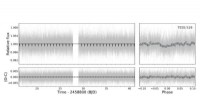
Stjärnförmörkelse:När en exoplanet passerar framför sin sol, dess ljusstyrka ändras på ett karakteristiskt sätt. Denna transitmetod är ett av de mest populära verktygen för astronomer. Kredit:© MPS / René Heller
René Heller från Max Planck Institute for Solar System Research fick redan forskarvärlden att lägga märke till när han och hans team upptäckte inte mindre än 18 tidigare förbisedda exoplaneter i data från rymdteleskopet Kepler. Nu lyckades de igen, denna gång för att hitta en något jordliknande planet som kretsar kring en solliknande stjärna. Vad är så speciellt med Dr. Hellers och hans teams nya metod?
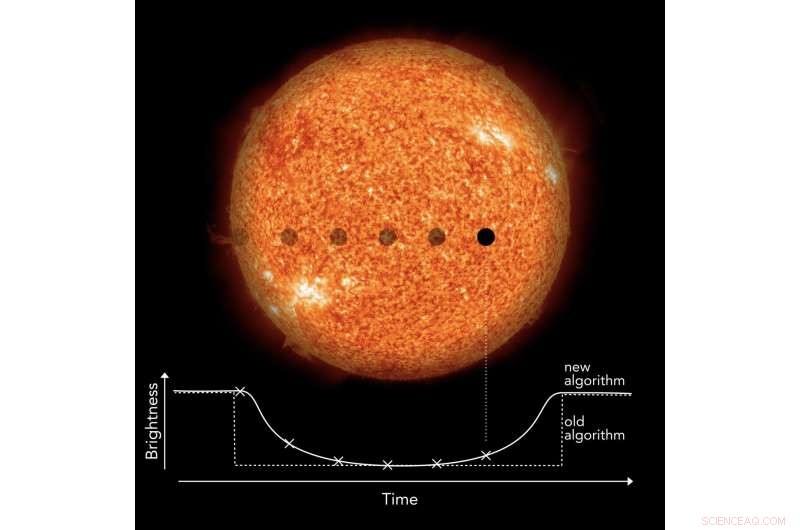
De flesta exoplaneter har hittills hittats med hjälp av den så kallade transitmetoden. Hur fungerar den här metoden och varför är den så framgångsrik?
René Heller:Genom att använda transitmetoden letar vi efter upprepade korta nedtoningar av en stjärna, som orsakas av en planet som passerar framför stjärnan när den ses från jorden. Denna händelse kallas transit. När du tittar på en slumpmässigt vald stjärna, dock, du vet vanligtvis inte om den har en transiterande planet eller ens en planet alls. För att hitta nya transiter, Vi måste vanligtvis titta på en stjärna under mycket lång tid och utan paus, vanligtvis i veckor och ibland i åratal. Men det räcker inte:för att transitmetoden ska fungera, vi behöver vara i planetens omloppsplan runt dess stjärna, sett från jorden. I genomsnitt, detta är bara fallet för ungefär var hundrade exoplanet. Och så måste vi observera hundratals och tusentals stjärnor kontinuerligt.
Transitmetoden är därför inte mer lovande än andra metoder, utan snarare liknar det ökända sökandet efter en nål i en höstack. Dess framgång baseras främst på den kontinuerliga observationen av ett stort antal stjärnor av NASA:s Kepler-rymdteleskop. Kepler har upptäckt tusentals exoplaneter sedan 2009, totalt mer än hälften av alla exoplaneter som är kända idag.
På senare år har du har lyckats förbättra den vanliga transiteringsmetoden. Vad är ditt knep?
Tills för några år sedan, de stora mängderna data som överfördes till oss med teleskop gjorde det nödvändigt att förenkla våra datorstödda sökalgoritmer här och där. Faktiskt, vissa vanliga sökalgoritmer försämrade först kvaliteten på datan med hjälp av vad som kallas data "binning", och sökte sedan efter transiter i lågupplösta data. Bara detta gjorde det möjligt att analysera de enorma mängderna stjärnor, var och en med år av kontinuerliga ljusstyrkemätningar inom tolererbara tidsperioder, som några dagar eller veckor. Under de senaste åren, dock, framsteg inom datorkraft har gjort det möjligt för oss att använda en förfinad algoritm.
Min kollega och IT-specialist Michael Hippke och jag har nu förfinat standardproceduren för exoplanettransitsökningar genom att helt enkelt avstå från databinning. En del av den ökade datorbelastningen kan absorberas av modern CPU-kraft, men vi var också tvungna att designa datorkoden från grunden för att göra den så effektiv som möjligt. Nu fungerar det till och med på en vanlig bärbar dator. Så du kan till och med hitta en exoplanet på en tågresa med en bärbar dator på knäna.
Hur många förbisedda exoplaneter har du kunnat spåra?
Än så länge, vi har publicerat 18 upptäckter i Kepler-data. KOI-456.04 är nu den 19:e exoplaneten som vi har identifierat och som tidigare har förbisetts av de vanliga sökteknikerna. Faktiskt, vi har upptäckt ytterligare några dussin kandidater, som vi just nu studerar mer i detalj innan vi rapporterar dem till samhället. Trots allt, vi vill inte sälja ett mätfel som en planet. Utöver våra egna sökningar med den uppgraderade algoritmen, vi har till och med sett andra forskarteam ladda ner vår kod och använda den för sina egna sökningar. Jag skulle inte bli förvånad om vår algoritm blev den nya standarden för exoplanettransitsökningar.
Data från rymdteleskopet Kepler har förmodligen analyserats grundligt och slutgiltigt vid det här laget. Förväntar du dig ändå ytterligare upptäckter av mindre planeter, kanske lika stor som jorden?
Med traditionella metoder, möjligheterna att hitta exoplaneter i Kepler-data har sannolikt uttömts, Jag håller med. Som sagt, våra första sökningar med vår nya algoritm visar att med denna metod finns det fortfarande spännande upptäckter att göra i datan. Det är som att alla har sopat sina kvastar genom datan och vi samlar nu in de återstående smulorna med en noggrann sopskåpa och borste. Men annorlunda än avfallet som du skulle plocka upp från golvet, det är dessa små smulor, Planeter i jordstorlek, som är de mest värdefulla fynden inom exoplanetvetenskap.
Under de nio verksamhetsåren, Kepler registrerade mätdata från cirka 150, 000 stjärnor. Hur bestämmer du vilka stjärnor som är värda en sekund, närmare titt?
Det noggranna urvalet av stjärnorna som skulle undersökas på nytt var avgörande för våra tidigare upptäckter. Vi använde ett litet men värdefullt knep:vi valde inte bara slumpmässigt en av de 150, 000 stjärnor från Kepler-uppdraget; istället, vi fokuserade på den andra delen av uppdraget, det så kallade K2-uppdraget, där transitplaneter redan hade upptäckts runt totalt 517 stjärnor. För att kontrollera om vår metod verkligen är bättre än de tidigare metoderna, vi tittade helt enkelt på alla ljusstyrkemätningar för dessa 517 stjärnor och letade efter ytterligare planeter som kan ha missats hittills.
Som ett resultat, vi hittade inte bara alla tidigare kända exoplaneter, men vi upptäckte också 18 nya. Det låter kanske inte så mycket, 18 av 517. Det är dock inte bara antalet planeter som är viktigt. Viktigare är det faktum att alla våra nyupptäckta planeter är ungefär lika stora som jorden och därmed mycket mindre än de flesta kända exoplaneter. Naturligtvis var det därför de först hade saknats.
Efter att ha sålt igenom K2-data, vi har nu utökat vår sökning till de mer än 4000 ljuskurvorna från det första Kepler-uppdraget från 2009 till 2013. Och återigen var vi framgångsrika. Planetkandidaten med 1,9 jordens radie KOI-456.04 runt den solliknande stjärnan Kepler-160 är bara vår första publikation.
Varför talar du om KOI-456.04 som en planetarisk kandidat?
Formellt sett, signalen från denna förmodade planet klarar ett av våra statistiska test med en sannolikhet på 85 procent. Det betyder att chansen är 85:15, eller nästan sex till ett, att denna signal verkligen orsakas av en planet och inte av en slumpmässig statistisk variation av data eller av en instrumentell effekt. Sex till ett, Jag skulle säga att det är en bra satsning. Men som astronomer vill vi att signalen ska ha en sannolikhet på 99 procent, en chans på 99 till ett, innan vi formellt skulle bevilja planetarisk status till kandidaten. Tills vidare, KOI-456.04 är fortfarande en bra kandidat.
Varför är det viktigt att undersöka ett enda stjärnsystem så noga? Vad lär vi oss av ett sådant enskilt fall?
Mänskligheten investerar avsevärda medel och arbete men också hjärta och själ i uppföljande observationer av de mest intressanta exoplaneterna eller planetkandidaterna. Även om finansiella investeringar i rymdforskning bara är ungefär en tusendel av militärbudgeten, vi vill inte slösa bort den värdefulla observationstiden. På något vis, observationstiden för mark- och rymdbaserade teleskop är värd miljarder euro eller dollar och vi vill verkligen undvika att spendera den tiden på ett intressant observationsmål – bara för att finna att målet inte existerar.
Det är därför vi gjorde stora ansträngningar i vår studie för att statistiskt fastställa planetens status. Strängt talat, denna karaktärisering av planeten – eller planetkandidaten – var den överlägset mest tidskrävande delen. Min kollega Michael Hippke och jag hade redan lyckats upptäcka KOI-456.04 i maj 2019, efter bara några dagars datorstödda sökningar av uppgifterna. Nästa steg, den extremt komplexa karaktäriseringen av planetsystemet runt stjärnan Kepler-160, tog lång tid, men vi lärde oss mycket när det gäller automatiseringen av våra metoder. Nästa gång kommer vi att vara snabbare och det kommer inte att ta oss ett år till att göra kandidatprövningen efter första upptäckten. Och den goda nyheten är att vi redan har hittat några dussin mer lovande kandidater i Kepler-data.