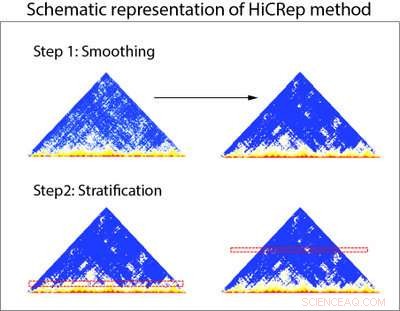
Schematisk representation av HiCRep-metoden. HiCRep använder två steg för att korrekt bedöma reproducerbarheten av data från Hi-C-experiment. Steg 1:Data från Hi-C-experiment (representerade i triangelgrafer) jämnas först ut för att tillåta forskare att se trender i data tydligare. Steg 2:Data stratifieras baserat på avstånd för att ta hänsyn till överflöd av närliggande interaktioner i Hi-C-data. Kredit:Li Laboratory, Penn State University
En ny statistisk metod för att utvärdera reproducerbarheten av data från Hi-C – ett banbrytande verktyg för att studera hur genomet fungerar i tre dimensioner inuti en cell – kommer att hjälpa till att säkerställa att data i dessa "big data"-studier är tillförlitliga.
"Hi-C fångar de fysiska interaktionerna mellan olika regioner av genomet, sa Qunhua Li, biträdande professor i statistik vid Penn State och huvudförfattare till uppsatsen. "Dessa interaktioner spelar en roll för att bestämma vad som gör en muskelcell till en muskelcell istället för en nerv- eller cancercell. standardmått för att bedöma datareproducerbarhet kan ofta inte avgöra om två prover kommer från samma celltyp eller från helt orelaterade celltyper. Detta gör det svårt att bedöma om uppgifterna är reproducerbara. Vi har utvecklat en ny metod för att noggrant utvärdera reproducerbarheten av Hi-C-data, vilket kommer att göra det möjligt för forskare att tolka biologin säkrare utifrån data."
Den nya metoden, kallas HiCRep, utvecklad av ett team av forskare vid Penn State och University of Washington, är den första som förklarar en unik egenskap hos Hi-C-data – interaktioner mellan regioner i genomet som ligger nära varandra är mycket mer sannolikt att inträffa av en slump och skapar därför falska, eller falskt, likhet mellan icke-relaterade prover. En artikel som beskriver den nya metoden dyker upp i tidskriften Genomforskning .
"Med den enorma mängd data som produceras i studier av hela genom, det är viktigt att säkerställa kvaliteten på uppgifterna, " sa Li. "Med högkapacitetsteknologier som Hi-C, vi är i stånd att få ny insikt om hur genomet fungerar inuti en cell, men bara om uppgifterna är tillförlitliga och reproducerbara."
Inuti en cells kärna finns en enorm mängd genetiskt material i form av kromosomer – extremt långa molekyler gjorda av DNA och proteiner. Kromosomerna, som innehåller gener och de regulatoriska DNA-sekvenser som styr när och var generna används, är organiserade och förpackade i en struktur som kallas kromatin. Cellens öde, om det blir en muskel- eller nervcell, till exempel, beror på, åtminstone delvis, på vilka delar av kromatinstrukturen som är tillgänglig för gener som kan uttryckas, vilka delar är stängda, och hur dessa regioner interagerar. HiC identifierar dessa interaktioner genom att låsa de interagerande regionerna i genomet tillsammans, isolera dem, och sedan sekvensera dem för att ta reda på var de kom ifrån i genomet.
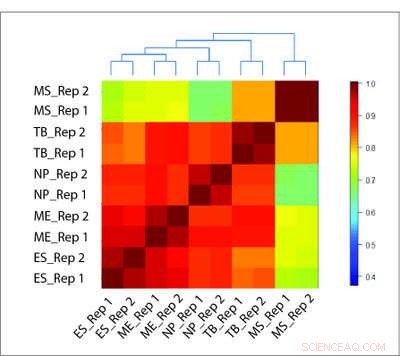
HiCRep-metoden kan noggrant rekonstruera det biologiska förhållandet mellan olika celltyper, där andra metoder misslyckas. Kredit:Li Laboratory, Penn State University
"Det är ungefär som en gigantisk skål med spagetti där varje plats som nudlarna rör vid kan vara en biologiskt viktig interaktion, " sa Li. "Hi-C hittar alla dessa interaktioner, men de allra flesta av dem förekommer mellan regioner i genomet som ligger mycket nära varandra på kromosomerna och inte har specifika biologiska funktioner. En konsekvens av detta är att signalstyrkan i hög grad beror på avståndet mellan interaktionsregionerna. Detta gör det extremt svårt för vanliga reproducerbarhetsmått, såsom korrelationskoefficienter, att differentiera Hi-C-data eftersom detta mönster kan se väldigt lika ut även mellan väldigt olika celltyper. Vår nya metod tar hänsyn till den här funktionen hos Hi-C och låter oss på ett tillförlitligt sätt särskilja olika celltyper."
"Detta ger oss en grundläggande statistisk läxa som ofta förbises i fältet, " sa Li. "Ganska ofta, korrelation behandlas som en proxy för reproducerbarhet i många vetenskapliga discipliner, men de är faktiskt inte samma sak. Korrelation handlar om hur starkt två objekt är relaterade. Två irrelevanta objekt kan ha hög korrelation genom att vara relaterade till en gemensam faktor. Detta är fallet här. Avstånd är den dolda gemensamma faktorn i Hi-C-data som driver korrelationen, vilket gör att korrelationen inte återspeglar informationen av intresse. Ironiskt, medan detta fenomen, känd som förvirrande effekt i statistiska termer, diskuteras i varje elementär statistikkurs, det är fortfarande ganska slående att se hur ofta det förbises i praktiken, även bland välutbildade vetenskapsmän."
Forskarna designade HiCRep för att systematiskt redogöra för denna avståndsberoende egenskap hos Hi-C-data. För att åstadkomma detta, forskarna jämnar först ut data så att de kan se trender i data tydligare. De utvecklade sedan ett nytt mått på likhet som lättare kan skilja data från olika celltyper genom att stratifiera interaktionerna baserat på avståndet mellan de två regionerna. "Det här är som att studera effekten av läkemedelsbehandling för en befolkning med väldigt olika åldrar. Stratifiering efter ålder hjälper oss att fokusera på läkemedelseffekten. För vårt fall, stratifiering efter avstånd hjälper oss att fokusera på det verkliga förhållandet mellan proverna."
För att testa deras metod, forskargruppen utvärderade Hi-C-data från flera olika celltyper med HiCRep och två traditionella metoder. Där de traditionella metoderna utlöstes av falska korrelationer baserade på överskottet av närliggande interaktioner, HiCRep kunde på ett tillförlitligt sätt differentiera celltyperna. Dessutom, HiCRep kunde kvantifiera mängden skillnad mellan celltyper och exakt rekonstruera vilka celler som var närmare relaterade till varandra.